sqoop导入导出工具的使用以及通过java代码连接linux,远程执行shell命令
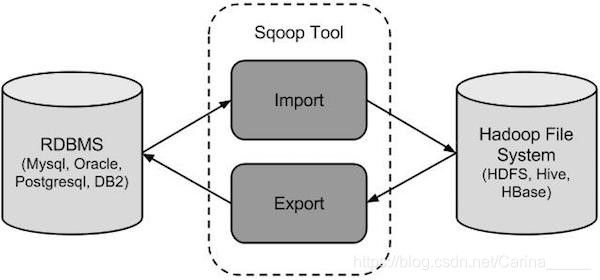
1、sqoop是apache开源提供的一个数据导入导出的工具,从关系型数据库导入到hdfs,或者从hdfs导出到关系型数据库等等
导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
导出数据:从Hadoop的文件系统中导出数据到关系数据库mysql等
**原理:**通过MR的inputformat和outputformat来实现数据的输入与输出,底层执行的全部都是MR的任务,只不过这个mr只有map阶段,没有reduce阶段
说白了只是对数据进行抽取,从一个地方,抽取到另外一个地方
2、sqoop的大的版本
sqoop 1.x 不用安装,解压就能用
sqoop 2.x 架构发生了变化,引入了一个服务端 可以通过代码提交sqoop的任务
一般用sqoop1.x比较多,直接将我们的命令写入到脚本里面去,执行脚本即可
sqoop安装
下载地址
http://archive.cloudera.com/cdh5/cdh/5/
sqoop1版本详细下载地址
http://archive.cloudera.com/cdh5/cdh/5/sqoop-1.4.6-cdh5.14.0.tar.gz
sqoop2版本详细下载地址
http://archive.cloudera.com/cdh5/cdh/5/sqoop2-1.99.5-cdh5.14.0.tar.gz
我们这里使用sqoop1的版本,下载之后上传到/export/softwares目录下,然后进行解压
cd /export/softwares
tar -zxvf sqoop-1.4.6-cdh5.14.0.tar.gz -C …/servers/
2、修改配置文件
cd /export/servers/sqoop-1.4.6-cdh5.14.0/conf/
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
export HADOOP_COMMON_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0
export HADOOP_MAPRED_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0
export HIVE_HOME=/export/servers/hive-1.1.0-cdh5.14.0
3、加入额外的依赖包
sqoop的使用需要添加两个额外的依赖包,一个是mysql的驱动包,一个是java-json的的依赖包,不然就会报错
mysql-connector-java-5.1.40.jar
java-json.jar
将这个两个jar包添加到sqoop的lib目录下
4、验证启动
cd /export/servers/sqoop-1.4.6-cdh5.14.0
bin/sqoop-version
sqoop工具的使用
1、列举出mysql服务器上面所有的数据库
bin/sqoop list-databases --connect jdbc:mysql://192.168.163.30:3306 --username root --password admin
2、列举出数据库下面所有的数据库表
bin/sqoop list-tables --connect jdbc:mysql://192.168.163.30:3306/azkaban --username root --password admin
3、导入mysql表到hdfs上面来 但是没有指定hdfs的导入路径
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb --username root --password admin --table emp -m 1
4、导入mysql表到hdfs上面来 指定hdfs的路径
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb --username root --password admin --table emp -m 1 --delete-target-dir --target-dir /sqoop/emp
5、导入数据到hdfs上面来,指定hdfs的路径,并且指定导出字段之间的分隔符
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb --username root
–password admin --table emp -m 1 --delete-target-dir --target-dir /sqoop/emp2
–fields-terminated-by ‘\t’
6、导入数据到hive表里面来
需要将hive-exec包放到sqoop的lib目录下面来
hive建表:
create external table emp_hive(id int,name string,deg string,salary int ,dept string) row format delimited fields terminated by ‘\001’;
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb --username root
–password admin --table emp -m 1 --delete-target-dir --target-dir /sqoop/emp2
–fields-terminated-by ‘\001’ --hive-import --hive-table sqooptohive.emp_hive --hive-overwrite
如果mysql表字段比hive字段多,那么hive里面就会丢几个字段
如果mysql表字段比hive字段少,那么hive里面就会有字段为null值
7、导入数据到hive里面来,并且自动创建hive表
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb
–username root --password admin --table emp_conn --hive-import -m 1
–hive-database sqooptohive;
8、导入数据子集
bin/sqoop import
–connect jdbc:mysql://192.168.163.30:3306/userdb
–username root --password admin --table emp_add
–target-dir /sqoop/emp_add -m 1 --delete-target-dir
–where "city = ‘sec-bad’"
9、通过sql语句查找导入hdfs里面来
使用sql语句来进行查找是不能加参数–table
并且必须要添加where条件,
并且where条件后面必须带一个$CONDITIONS 这个字符串,
并且这个sql语句必须用单引号,不能用双引号
bin/sqoop import --connect jdbc:mysql://192.168.163.30:3306/userdb
–username root --password admin
-m 1 --delete-target-dir
–target-dir /sqoop/emp_conn
–query ‘select phno from emp_conn where 1=1 and $CONDITIONS’
10、增量的导入
只导入我们部分需要的数据
现在时间2018-11-20 02:30:00 导入数据时间 2018-11-19 00:00:00 2018-11-19 23:59:59
全量导入,数据太多,对数据库压力比较大
增量的导入
bin/sqoop import
–connect jdbc:mysql://192.168.163.30:3306/userdb
–username root
–password admin
–table emp
–incremental append
–check-column id
–last-value 1202
-m 1
–target-dir /sqoop/increment
如何解决增量导入的问题??
每个表都会有三个固定的字段
create_time
update_time
is_delete
operator
create_time 2018-11-18 20:12:32
update_time 2018-11-19 20:12:32
如何解决导入增量的问题
每个数据都会有一个创建时间,可以根据我们的创建时间来判断是否是我们前一天的数据
如何解决导入减量数据的问题???
什么是减量数据????删除掉的数据 数据不是做真删除
做假删除,其实就是改变了一些数据的状态,数据的更新时间,同步改变
银行客户 13859687451
变更手机号 13896541235
所有的减量数据都转化为变更数据来处理
第一个:涉及到数据的变更问题,
变更数据一定有更新时间 每天导入数据的时候,需要根据创建时间和更新时间来一起判断
第一条数据 create_time 2018-11-19 12:23:45
第二条数据 update_time 2018-11-19 15:23:45
根据两个条件来同时进行判断,满足任意一个,都要将数据导入过来
id create_time update_time
1 2018-11-15 23:45:15 2018-11-15 23:45:15
1 2018-11-15 23:45:15 2018-11-28 23:45:15
最后再group by id
如何解决减量问题??
如何解决变更问题???
都是根据create_time update_time 来联合进行判断
使用–where来实现增量的导入
bin/sqoop import
–connect jdbc:mysql://192.168.163.30:3306/userdb
–username root
–password admin
–table emp
–incremental append
–where "create_time > ‘2018-06-17 00:00:00’ and is_delete=‘1’ and create_time < ‘2018-06-17 23:59:59’ "
–target-dir /sqoop/incement2
–check-column id
–m 1
不能使用 --last-value 2018-06-17 00:00:00
因为如果产生一条数据是2018-06-18 01:00:00,同样会被导入到18号当天的文件中去
2018-06-18 02:00:00
sqoop的数据的导出:
导出:从hdfs到关系型数据库
bin/sqoop export
–connect jdbc:mysql://192.168.163.30:3306/userdb
–username root --password admin
–table emp_out
–export-dir /sqoop/emp
–input-fields-terminated-by “,”
导出数据的时候,如果导出到一半,报错了怎么办????
一般都是创建mysql的临时表 如果临时表导入成功,再往目的表里面导入
sqoop的job 就是将我们的导入导出到命令,保存起来,下次可以直接调用,没有必要,写脚本就好了
sqoop导入导出是一个离线处理的工具
底层使用的都是MR的程序
通过java代码执行linux的shell命令
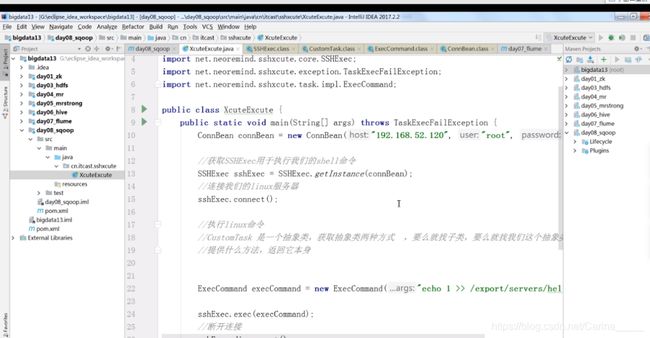

离线项目的处理架构流程
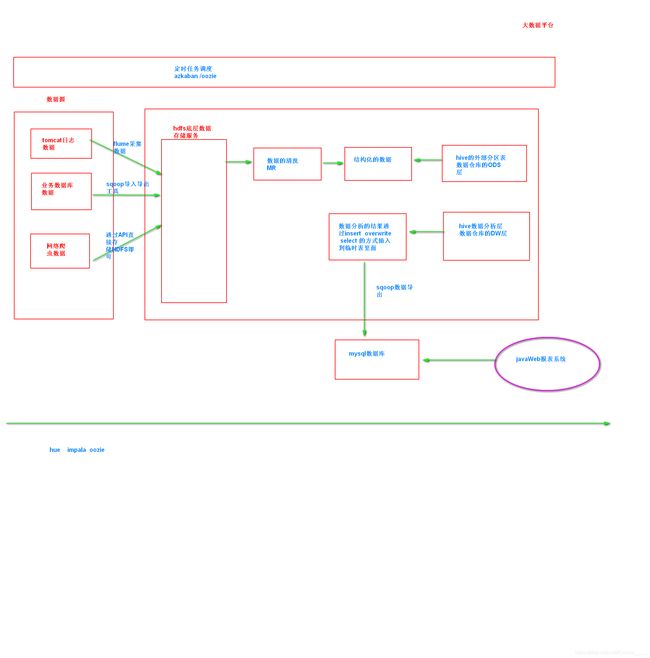
可以实现实时的抽取数据的工具
canal 通过解析binlog可以实现实时的数据抽取
flume 自定义source 代码在github上面 也可以实现近似实时的数据抽取
streamSet 比较强大,可以实现实时的抽取数据
下去调研了解以上三个工具实现实时的抽取