《python每天一小段》-- (10)爬取小说:斗罗大陆
欢迎阅读《Python每天一小段》系列!在本篇文章中,将使用Python编写一个简单的爬虫程序,爬取网络小说《斗罗大陆》的内容。
文章目录
-
-
- (1)安装依赖库
- (2)步骤概述
- (3)爬虫准备步骤
- (4)爬虫代码实现
- (5)执行结果
-
以下是根据提供的内容进行扩展和整理的《python每天一小段》博客文章的示例:
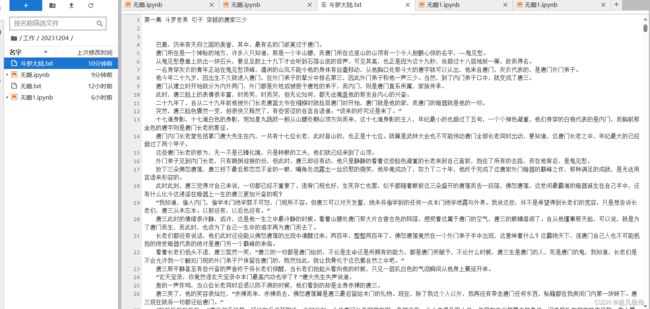
爬取章节如图:

在本篇文章中,将使用Python编写一个简单的爬虫程序,用于从小说网站上爬取《斗罗大陆》小说的章节内容,并将其保存到本地文件中。我们将使用requests库发送HTTP请求,lxml库解析HTML响应,并使用XPath表达式来提取所需的数据。
(1)安装依赖库
pip install lxml
(2)步骤概述
- 获取代理头:通过检查网页头部信息,获取User-Agent,用于伪装爬虫代码的访问信息。
- XPath安装使用:安装XPath Helper扩展程序,并使用XPath表达式剔除HTML标签,提取小说文字内容。
- 获取下一章内容:通过检查网页元素,找到下一章的链接,并使用XPath表达式来获取下一章的URL。
(3)爬虫准备步骤
url为小说的第一章,网页地址:https://www.51shucheng.net/wangluo/douluodalu/21750.html

获取代理头:
-
获取代理头的作用主要是用于伪装代码访问的信息
-
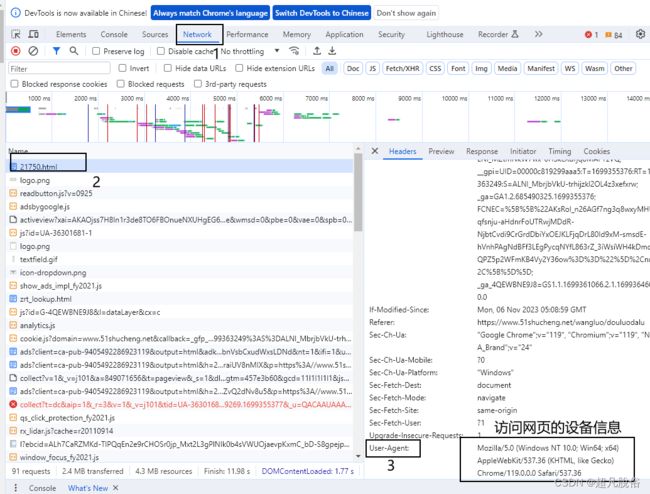
在网页空白处,鼠标右击点击检查,打开界面在network选项,使用ctrl+r刷新一下network的信息,截图中2的任意位置,鼠标左击,可以看到headers头部信息,找到User-Agent,复制该信息,用于代码:
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
xpath安装使用
- google浏览器安装扩展程序:XPath Helper(可将快捷键设置为ctrl+u,没设置不知道具体快捷键,打不开黑框)
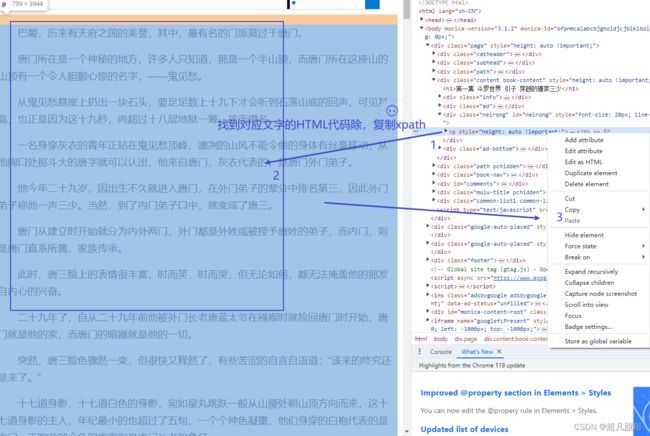
在小说网页界面,按ctrl+uxpath的小黑框,输入:string(//div/p)
string(//div/p)是通过网页截取,因为不懂html,就粗略过一遍


xpath配合lxml模块,用于剔除html标签,以及底部的评论,剩下就是小说文字。

获取下一章内容:
在下一章处,鼠标右击点击检查
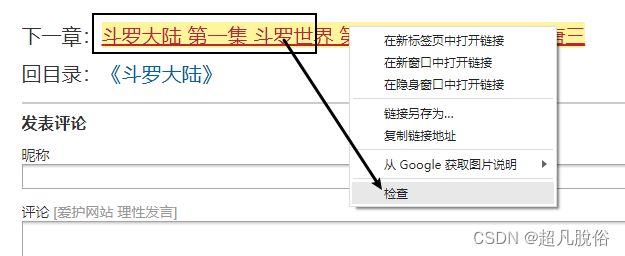
在elements处,找到下一章的链接,

鼠标右击Copy->Copy Xpath
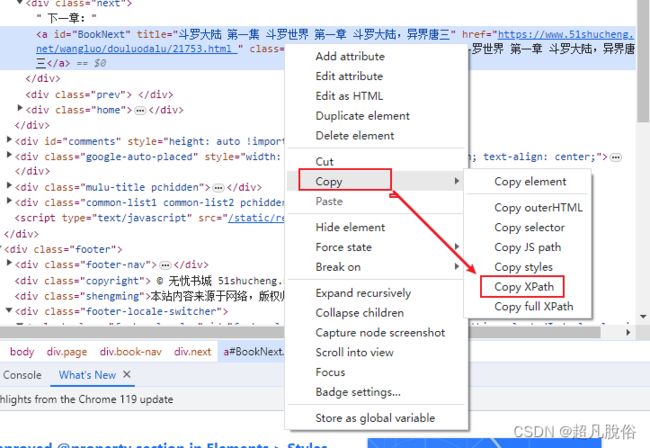
粘贴xpath查看获取的具体内容是否正确,显示的时下一章的主题即可。
使用XPath表达式来从HTML页面中查找下一章链接的URL
next_chapter_url = e.xpath('//*[@id="BookNext"]/@href')

(4)爬虫代码实现
#首先,我们导入所需的库:
import requests
from lxml import etree
from urllib.parse import urljoin
#然后,我们定义初始URL和一个循环,用于遍历每一章节:
url = 'https://www.51shucheng.net/wangluo/douluodalu/21750.html'
while True:
# 发送GET请求
resp = requests.get(url, headers=headers)
# 解析HTML响应
e = etree.HTML(resp.text)
# 提取章节标题和内容
info = ' '.join(e.xpath('//div/p//text()'))
title = e.xpath('//h1/text()')[0]
# 打印和保存章节内容
print(title)
with open('斗罗大陆.txt', 'a', encoding='utf-8') as f:
f.write(title + '\n\n' + info + '\n\n')
# 获取下一章的URL
next_chapter_url = e.xpath('//*[@id="BookNext"]/@href')
if not next_chapter_url:
print("没有更多章节可用。")
break
# 更新URL
url = urljoin(url, next_chapter_url[0])
在代码中,使用requests.get()发送GET请求,并使用headers参数传递代理头信息。然后,使用lxml库的etree.HTML()函数解析HTML响应,以便我们可以使用XPath表达式提取所需的数据。
我们使用XPath表达式 //div/p//text() 提取章节内容,并使用 //h1/text() 提取章节标题。然后,我们打印章节标题,并将章节标题和内容写入到名为 斗罗大陆.txt 的文件中。
接下来,我们使用XPath表达式 //*[@id="BookNext"]/@href 获取下一章的URL,并使用urljoin()函数将相对URL转换为绝对URL,以确保正确构建URL。
最后,通过循环继续处理下一章,直到没有更多章节可用。
(5)执行结果
在代码执行完成后,我们将在控制台上看到每一章的标题,并将所有章节的标题和内容保存在 斗罗大陆.txt 文件中。
可以根据需要对代码进行修改和优化,例如添加异常处理、设置请求延迟等。

小说内容: