【深入理解指针 (2)】
目录
- 数组名的理解
- 使用指针访问数组
- 一维数组传参的本质
- 冒泡排序
- 二级指针
- 指针数组
- 指针数组模拟二维数组
1. 数组名的理解
在上一个章节使用指针访问数组的内容时,有这样的代码:
int arr[10] ={1,2,3,4,5,6,7,8,9,10}
int* p= &arr[0]
这里 &arr[0] 的方式拿到了第一个元素的地址,但是数组名本来就是地址,而且是数组首元素的地址
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
输出结果:

可以看见两个地址是一样的,所以数组名就是数组首元素的地址
是数组首元素的地址,那sizeof求出的为什么不是首元素的大小
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%d\n", sizeof(arr));
输出的结果是40,首元素的地址应该是4或者8才对
其实数组名是首元素的地址是没问题的,但有两个例外
- sizeof (数组名),sizeof单独放数组名,这里的数组名表示整个数组,计算整个数组的大小
- & 数组名,这里的数组名表示整个数组,取出的是整个数组的地址,虽然显示的一样,但还是有区别的
可以对每个类型地址+1看看
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
printf("&arr = %p\n", &arr);
三个地址是一样的,那arr和&arr有啥区别
再看下面代码执行的结果:
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0]+1 = %p\n", &arr[0]+1);
printf("arr = %p\n", arr);
printf("arr+1 = %p\n", arr+1);
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr+1);

前两个+1加的是一个元素的大小4,因为这两个都是取首元素的地址,+1就是跳过一个元素
&arr取的是整个数组的地址,+就是跳过整个数组,所以是40个字节
2. 使用指针访问数组
有了前面的说明,就可以很方便的使用指针访问数组了
int arr[5] ;
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
for (int i = 0; i < sz; i++) {
*p = i + 1;
p++;
}
//输出
p = arr;
for (int i = 0; i < sz; i++) {
printf("%d", *(p+i));
}
既然arr是数组首元素的地址,赋值给了p,可以使用arr[i]访问,那p[i]是否也可以访问数组呢?
int arr[5] ;
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
for (int i = 0; i < sz; i++) {
*p = i + 1;
p++;
}
//输出
for(i=0; i<sz; i++)
{
printf("%d ", p[i]);
}
*(p+i)和p[i]都是可以正常打印的,所以本质上p[i]等价于 (p+i)
同理arr[i]等价于(arr+i),在编译的时候,也是转换为首元素的地址+偏移量求出元素的地址来访问的
类似的 *(i+arr)写为i[arr]访问数组也是没问题的,但一般不这样写
3. 一维数组传参的本质
之前在main函数里可以计算数组元素个数,那我们可以吧数组传递给一个函数,在函数内部求元素个数吗?
void test(int arr[])
{
int sz2 = sizeof(arr) / sizeof(arr[0]);
printf("sz2 = %d\n", sz2);
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int sz1 = sizeof(arr)/sizeof(arr[0]);
printf("sz1 = %d\n", sz1);
test(arr);
return 0;
}

在函数内部没有正确获取元素个数,这时就体现了数组传参的本质,数组传参本质上传递的是数组首元素的地址
所以sizeof (arr) 计算的是地址的大小不是数组的大小,两个地址大小一样,结果是1
一维数组传参,形参部分可以写成数组的形式,也可以写成指针的形式
4. 冒泡排序
核心思想: 两两相邻元素比较
详细过程分析: 以数据为 9,4,2,6,7 举例升序的排列,即从小到大
一轮比较称为一趟冒泡排序,先演示第一趟
先用第一个元素9和第二个元素4比较,如果第一个大于第二个元素,两个交换位置。然后第二个和第三个元素比较,大于则交换,依次循环

第二趟时继续用第一个元素和第二个元素相比,大于则交换,这次比较次数比上一次少一次,因为9已经排好了不会动

- 因为是升序,所以比较是不是大于后面的数,大了则移动,最大的在最后。在第一趟冒泡排序的时候找出了最大值9,且放到了最后的位置。第二趟找到了除9外的最大值7,放到了倒数第二个位置
- 有5个数字只需要比较4次,将其他4个排好,最后一个数字自然就会排好,这是需要几趟冒泡循环的次数
- 第一趟两两比较,5个数字只需要比较4次,也就是4对,n-1次。第二趟时,由于最大的9已经排好,不需要比较,只需要n-2次…
- 升序用大于号比较,降序则用<号
void bubble_sort(int arr[],int sz) {
//总共比较sz-1次
for (int i = 0; i < sz-1; i++) {
//i越大,需要比较的次数越小
for (int j = 0; j < sz - i - 1; j++) {
//比较相邻两个数,大了则交换
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main()
{
int arr[] = { 3,1,7,5,8,9,0,2,4,6 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
for (int i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
return 0;
}
这种代码怎么进行优化,比如数据为 9,1,2,3,4,5这种,第一趟排序完数组已经变成有序了,那么就没有必要继续冒泡下去了
可以设置一个变量,当一趟中有一次交换说明数组仍是无序,没有交换说明有序了
void bubble_sort(int arr[],int sz) {
//总共比较sz-1次
for (int i = 0; i < sz-1; i++) {
int flag = 1; //假定数组已经有序
//i越大,需要比较的次数越小
for (int j = 0; j < sz - i - 1; j++) {
flag = 0; //交换置0
//比较相邻两个数,大了则交换
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
if (flag==1)
break;
}
}
int main()
{
int arr[] = { 3,1,7,5,8,9,0,2,4,6 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
for (int i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
return 0;
}
5. 二级指针
指针变量也是变量,是变量就有地址,那么指针的地址存放在哪?
这就是二级指针

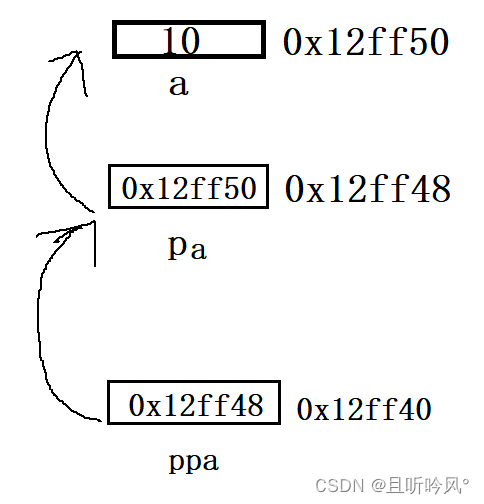
上面定义了一个变量a,值是10,这个变量的地址是0x12ff50,指针pa指向a的地址,它的值是0x12ff50,这个指针也有自己的地址,是0x12ff48,这个就是二级指针,指向指针的指针,二级指针也有自己的地址,是0x12ff40
定义说明
以 int* p=&a 为例
int说明指向的类型是int*
第二个*表示是指针类型
p是二级指针的名字
对于二级指针的运算有:
- *ppa 通过对ppa中的地址进行解引用,这样找到的是pa,*ppa其实访问的就是pa
int b=20;
*ppa=&b; //等价于pa=&b
- **ppa通过*ppa找到pa,然后对pa解引用,找到的是a
**ppa=30;
//等价于 *pa=30
//等价于 a=30
6. 指针数组
指针数组是指针还是数组?
我们类比一下,整形数组是存放整形数组
那指针数组,就是存放指针的数组
决定实物本质的是后面的词,指针数组,本质上是数组

7. 指针数组模拟二维数组
用指针数组来模拟一个二维数组,一维数组的首元素是数组首个元素的地址,二维数组每一行是一个一维数组
int arr1[5] = { 1,2,3,4,5 };
int arr2[5] = { 2,3,4,5,6 };
int arr3[5] = { 3,4,5,6,7 };
//定义一个指针数组,每个变量用一个一维数组初始化
int* p[3] = { arr1,arr2,arr3 };
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 5; j++) {
//printf("%d ", p[i][j]);
printf("%d ", *(*(p+i)+j));
}
printf("\r\n");
}
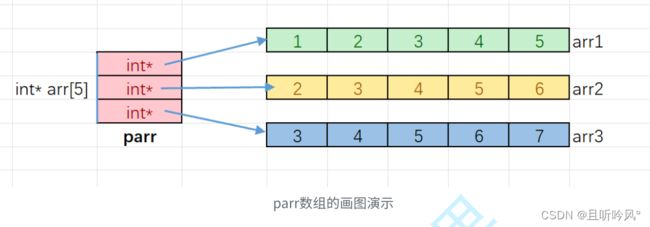
上述两种打印方法都可以,第一种是下标访问,第二种是用解引用的方式拆解下标。p[i]实际上就是访问每一行的一维数组,p[i][j]就是遍历每一行的每个元素
上述是模拟的二维数组,但不是真正的二维数组,真正的二维数组是连续存放的