【字符函数和字符串函数】
目录
- 字符分类函数
- 字符转换函数
- strlen的使用和模拟实现
- strcpy的使用和模拟实现
- strcat的使用和模拟实现
- strcmp的使用和模拟实现
- strncpy的使用
- strncat的使用
- strncmp的使用
- strstr的使用和模拟实现
- strtok的使用
- strerror的使用
- 字符串匹配优化-KMP算法
在编程的过程中,经常要处理字符和字符串,为了方便操作字符和字符串,c语言标准库提供了一系列库函数,接下来学习一下这些函数
1. 字符分类函数
c语言有一系列函数专门做字符分类的,也就是一个字符属于什么类型的字符
这些函数都需要一个头文件ctype.h
| 函数 | 如果它的参数符合下列条件就返回真 |
|---|---|
| iscntrl | 任何控制字符 |
| isspace | 空白字符: 空格 ’ ’ ,换页 ‘\f’ , 换行 ‘\n’ , 回车 ‘\r’ , 制表符 ‘\t’ , 垂直制表符 ‘\v’ |
| isdigit | 十进制数字 0-9 |
| isxdigit | 十六进制数字,包括所有十进制数字, 小写字母a-f,大写字母A-F |
| islower | 小写字母a-z |
| isupper | 大写字母A-Z |
| isalpha | 字母a-z或A-Z |
| isalnum | 字母或者数字,a-z,A-Z,0-9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符 (可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
控制字符说明,当c在0x00-0x1F之间或等于0x7F(DEL)时,返回非零值,否则返回零
这些函数的使用方法类似,只讲解一个:
int islower (int c);
islower函数能够判断参数部分的c是否是小写字母
通过返回值来说明是否是小写字母,如果是小写字母就返回非0的整数,如果不是小写字母,则返回0
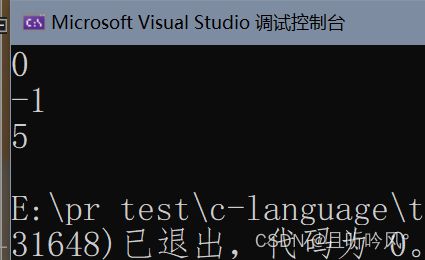
练习
写一个代码,将字符串中的小写字母转大写,其他字符不变
int i = 0;
char str[] = "test string.\n";
char c;
while (str[i]) {
c = str[i];
if (islower(c)) {
c -= 32;
}
putchar(c);
i++;
}
输出
2. 字符转换函数
c语言提供了两个字符转换函数:
int tolower ( int c ); //将参数的大写字母转小写
int toupper ( int c ); //将参数的小写字母转大写
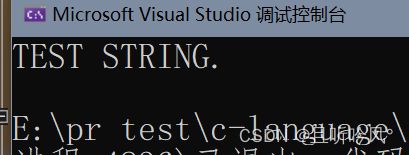
有了转换函数,就可以用这种方法实现上面的功能
int i = 0;
char str[] = "test string.\n";
char c;
while (str[i]) {
c = str[i];
if (islower(c)) {
c = toupper(c);
}
putchar(c);
i++;
}
3. strlen的使用和模拟实现
函数原型
size_t strlen ( const char * str);
- 字符串以
\0作为结束标志,strlen函数返回\0之前字符个数,不包含\0 - 参数指向的字符串必须以\0结束
- 函数的返回值是size_t,是无符号的
如 strlen(3)-strlen(6),一个是3的长度,一个是6,减下来本来等于-3,但因为返回值是无符号的,在没有其他变量接收的时候,会转化为一个无符号的数\ - 使用包含头文件
使用
const char* str1 = "abcdef";
const char* str2 = "bbb";
if(strlen(str2)-strlen(str1)>0)
{
printf("str2>str1\n");
}
else
{
printf("srt1>str2\n");
}
上面由于strlen返回的是无符号,所以短的减长的会是一个无符号,大于0,输出str2>str1
输出:

strlen的模拟实现
方式1,计数器:
//计数器的方式
int my_strlen(const char* str) {
assert(str);
int count = 0;
while (*str) {
count++;
str++;
}
return count;
}
方式2,指针:
//指针-指针的方式
int mystrlen(const char* str) {
assert(str);
char* p = str;
while (*p) {
p++;
}
return p - str;
}
方式3 递归:
int my_strlen(const char* str) {
assert(str);
if (*str == '\0') {
return 0;
}
else {
return 1 + my_strlen2(str+1);
}
}

指针每次+1,往右挪一位,字符串的长度就会减1
4. strcpy函数的使用和模拟实现
char* strcpy ( char* destination, const char* source );
复制源指针的字符串到目标指针,遇到空字符结束
- 源字符串必须以
\0结束 - 会将源字符串中的 \0 拷贝到目标空间
- 目标空间必须足够大,以确保能存放源字符串,不然报错
- 目标空间必须可修改
模拟实现
char* my_strcpy(char* destination,const char* source) {
char* ret = destination;
assert(destination);
assert(source);
while (*source) {
*destination = *source;
destination++;
source++;
}
*destination = '\0';
return ret;
}
strcat的使用和模拟实现
拼接源字符串到目标字符串,目标字符串的结尾空字符被新字符第一个字符覆盖
- 原字符串必须以\0结束
- 目标字符串也得有 \0 , 否则不知道追加从哪开始
- 目标空间必须足够大,能容纳下两个字符串
- 目标空间可修改
- 字符串自己给自己追加
模拟实现
char* my_strcat(char* dest,const char* src) {
char* ret = dest;
assert(dest);
assert(src);
while (*dest) {
dest++;
}
while (*src) {
*dest = *src;
dest++;
src++;
}
*dest='\0';
return ret;
}
6. strcmp的使用和模拟实现
这个函数开始比较每个字符串的第一个字符,如果相等继续比较下一对,直到不同或者空字符结束
- 第一个字符串大于第二个字符串,返回大于0的数字
- 第一个字符串等于第二个字符串,返回0
- 第一个字符串小于第二个字符串,返回小于0的数组
模拟实现
int my_strcmp(const char* str1,const char* str2) {
assert(str1);
assert(str2);
while (*str1 == *str2) {
if (*str1 == '\0') {
return 0;
}
str1++;
str2++;
}
return *str1 - *str2;
}
7. strncpy函数的使用
char* strncpy ( char* destination, const char* source, size_t num );
拷贝原字符串前num个字符到目标字符串,如果在复制num个字符后,原字符串的末尾被找到,目标指针用0填充直到写入num个字符
- 从原字符串拷贝num个字符到目标空间
- 如果原字符串长度小于num,则拷贝完原字符串后,在目标后边追加0,直到num个
使用
char string[32] = "Cats are nice";
strncpy( string, "Dog", 3 );
printf ( "After: %s\n", string );
输出:

这个函数拷贝时不会在末尾自动加\0
8. strncat的使用
char* strncat ( char* destination, const char* source, size_t num );
- 将source指向字符串的前num个字符追加到destination的末尾,再追加一个\0
- 如果source的字符串长度小于num,只会将到\0的内容追加到末尾
char str1[20];
char str2[20];
strcpy (str1,"To be ");
strcpy (str2,"or not to be");
strncat (str1, str2, 6);
printf("%s\n", str1);
拼接str2前6个字符到str1末尾,也就是or not
输出:

9. strncmp的使用
int strcmp ( const char* str1, const char* str2, size_t num ) ;
比较str1和str2的前num个字符,如果相等继续往后比较,最多比较num个,如果提前发现不一样就提前结束,如果num个字符都相等,就返回0

10. strstr的使用和模拟实现
char* strstr ( const char* str1, const char* str2) ;
- 函数返回字符串str2在字符串str1中第一次出现的位置,不是子串返回NULL
- 字符串的比较匹配不包含\0.以\0作为结束标志
char str[] ="This is a simple string";
char * pch;
pch = strstr (str,"simple");
printf("%p\n", pch );
输出:
 模拟实现
模拟实现
char* my_strstr(const char* str1, const char* str2) {
char* start1 = (char*)str1;
char* s1, *s2;
if (!*str2)
return ((char*) str1);
while (*start1) {
s1 = start1;
s2 = (char*) str2;
while (!(*s2-*s1) && *s1 && *s2) {
s1++;
s2++;
if (!*s2) {
return start1;
}
}
start1++;
}
return NULL;
}
11. strtok的使用
- sep参数指向一个字符串,定义了用作分隔符的字符集合
- 第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记
- strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针 ( strtok函数会改变被操作的字符串,所以在使用的时候切分的字符串一般都是临时拷贝的内容,并且可修改 )
- strtok函数的第一个参数不为NULL,函数将找到str中的第一个标记,strtok函数保存它在字符串中的位置
- strtok函数的第一个参数为NULL,函数将在同一个字符串中被保存的位置开始,查找下一个标记
- 如果字符串中不存在更多的标记,则返回NULL指针
使用
char arr[] = "[email protected]";
char* sep = ".@";
char* s = NULL;
//分开输出
s = strtok(arr,sep);
printf("%s ",s);
s = strtok(NULL, sep);
printf("%s ", s);
s = strtok(NULL, sep);
printf("%s ", s);
s = strtok(NULL, sep);
printf("%s ", s);
//循环
for (s = strtok(arr, sep); s != NULL; s = strtok(NULL, sep)) {
printf("%s ", s);
}
12. strerror的使用
char* strerror ( int errnum ) ;
可以吧参数部分错误码对应的错误字符串返回
在不同的系统和c标准库都规定了一些错误码,一般放在 errno.h 头文件,用一个全局的变量errno来记录错误码,刚开始是0,表示没有错误,数字很难理解错误信息,所以可以通过数字打印错误信息
//打印0-10的错误信息
for (int i = 0; i <= 10; i++) {
printf("%d :%s\r\n", i, strerror(i));
}
输出 (win10 vs2022):

使用
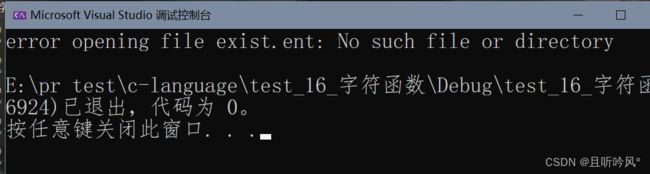
FILE* pfile = fopen("exist.ent","r");
if (pfile == NULL) {
printf("error opening file exist.ent:%s",strerror(errno));
}
由于目录不存在此文件,会打印错误信息,不存在该文件
输出

也可以使用perror函数,可以直接将错误信息打印出来,不需要错误码,还会先输出冒号和空格,再打印错误信息
FILE* pfile = fopen("exist.ent","r");
if (pfile == NULL) {
//printf("error opening file exist.ent:%s",strerror(errno));
perror("error opening file exist.ent");
}
输出
13. 字符串匹配优化-KMP算法
上面的strstr函数的使用使用的是一种BF算法,从T字符串和S字符串的第一个开始比较,如果相等继续比较第二个,不相等,比较T字符的第二个和S字符串的第一个,它的时间复杂度是 O (m*n),m和n可看做是两个字符串的长度。这种方法是可以优化的,如果S字符串的长度是5,当T字符串剩下的长度不足5时,肯定是匹配失败的,这时,可以提前返回失败
这里讲解另一种匹配思路,KMP方法
简介
kmp算法是字符匹配算法,核心是利用匹配失败后的信息,尽量减少子串的匹配次数达到快速匹配的目的。具体通过next()的函数实现,本身包含了模式串的局部匹配信息,时间复杂度为O(m+n)
KMP的i值不会回退,只回退j,j也不是一定回退到0位置
- 首先说明为什么主串不回退

上面的一个主串和子串,按照BF匹配,匹配到5下标,一个是d,一个是c,所以需要回退,j回退到0,i回退到刚开始匹配的下标的下一个,也就是1下标,继续开始匹配
但我们再想一想,既然能匹配到最后一个字符,说明两个串前面有一部分是相同的,例如上图的第一个蓝色下划线ab,子串中有两个ab,之所以用第一个ab,是因为中间有可能有其他字母漏匹配,以第一次匹配的为准。
在这种情况下,i没必要回退,继续匹配下一个字符d,j也没必要回退到0下标,因为ab和上面匹配到的ab是一样的,j完全可以回退到ab后的2下标继续匹配,这时同时移动两个下标,两个字符串完全匹配上了,就用没有回退的方式找到了子串的位置
上面可能是一个特定的例子,但可以总结出这种思路,根据不同的结果调整j返回的下标,,这个就是next数组,,它保存了每个结果匹配不成功j返回的下标,不同的j值对应了一个k值,k就是返回的位置
k值的计算规则是这样:
规则: 找到匹配成功部分两个相等的真子串 (不包括本身),一个以下标0开始,另一个以j-1下标结尾。若找到,k值找到的子串长度,没找到填0
不管什么数据,next[0] = -1,next[1] = 0
以下面的练习来说明next数组的填写规则

首先规则2说,0和1下标,总是填-1和0

接下来看2下标,按照规则1的说法,需要找两个真子串,一个以下标0开始,一个以j-1,也就是找以a开始以b结尾的两个真子串,只有一个ab,所以填0
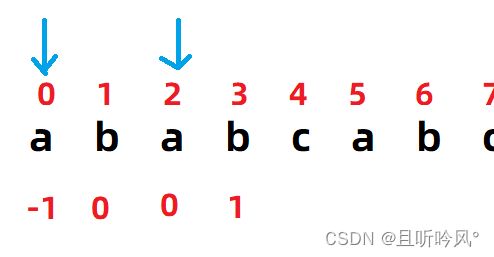
然后看3下标,就是找以0下标开始,2下标结束的两个子串,也就是以a开始,a结尾的子串,有两个a,长度是1,填1
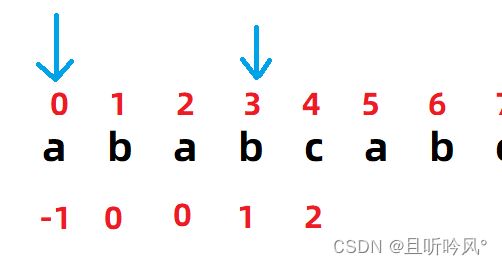
到下标4的时候,找以a开始b结尾的两个子串,0和1下标的ab和2和3下标的ab符合条件,ab长度是2,填2
按照上述规则继续往下,得出下面结果:

那么如何将这种方法转换为程序呢?这里我们分为两种情况
第一种情况,要填的下标的前一个字母和匹配的第一个字串的下一个相等,下图所示

我们要填第9个下标,9下标需要根据8下标填,之前匹配到的字串是abc (绿色下划线),可以发现8下标和k下标的字母都是a,说明9下标肯定可以匹配abca,所以在8下标的基础上加1。
j看做需要填的下标,可以得出规则,k是next[j-1],如果next[j-1] == next[k] ,next[j] = next[j-1] +1
第二种情况,要填的j-1下标的字母和匹配到的第一个字串的下一个字符不一致

需要填6下标,i下标和k下标一个是a,一个是c,不一致。所以k需要回退,回退到k的位置,k的字符是a还是不一致,继续回到0下标,0下标时a,和i下标一致,所以填1,如果一直不相等,会回到0下标,值是-1的话,加1,填为最小值0就行
规则,如果next[j-1] != next[k] , k = next[k],一直重复,直到找到 next[k] == next [j-1],如果值为-1,填为0
得出以上两种情况,就可以写代码了
代码
//获取next数组
void GetNext(char* sub,int* next) {
next[0] = -1;
next[1] = 0;
int lensub = strlen(sub);
int i = 2; //当前下标
int k = 0; //前一项k值
while (i<lensub) {
if (k==-1 || sub[i - 1] == sub[k]) {
next[i] = k + 1;
i++;
k++;
}
else {
k = next[k];
}
}
}
//kmp
int KMP(const char* str,const char* sub ) {
assert(str!=NULL && sub!=NULL);
int lenstr = strlen(str);
int lensub = strlen(sub);
if (lenstr == 0 || lensub == 0) return-1;
int* next = (int*)malloc(sizeof(int) * lensub);
assert(next != NULL);
GetNext(sub,next);
int i = 0; //遍历主串
int j = 0; //遍历子串
while (i<lenstr && j<lensub) {
if (j==-1 || str[i] == sub[j]) {
i++;
j++;
}
else {
j = next[j];
}
if (j >= lensub) {
//找到了,返回下标
return i - j;
}
}
//没找到,返回-1
return -1;
}
测试
printf("%d\r\n", KMP("ababcedfdab", "abab")); //0
printf("%d\r\n", KMP("ababcedfdab", "ababf")); //-1
printf("%d\r\n", KMP("ababcedfdab", "edfd")); //5
输出