TensoRF: Tensorial Radiance Fields
TensoRF: Tensorial Radiance Fields
TensoRF是ECCV2022一个非常有特色的工作。作者在三维场景表示中引入张量分解的技术,将4D张量分解成多个低秩的张量分量,实现更好的重建质量、更快的重建速度、更小的模型体积。
文章目录
- TensoRF: Tensorial Radiance Fields
- 一、论文想法
- 二、张量分解-数学原理
- 三、VM分解在NeRF中的具体使用
- 四、实验细节
- 总结
一、论文想法
TensoRF并没有采用像原始NeRF一样纯粹的隐式表示方法,更像是一种显示+隐式结合表示的方法,将场景建模为一个四维的张量,张量中的每一项代表一个体素,体素内包含了体积密度和多维的特征信息。

论文的中心思想是,使用张量分解技术,将4D张量分解成多个低秩的张量分量,实际处理时不用建模出这个4D张量,而用一系列1D向量、2D矩阵表示,从而降低显存消耗,提高运算速度。
二、张量分解-数学原理
外积(outer product)是线性代数中的一类重要运算,对于n维和m维的两个向量,其外积定义为一个n × m的矩阵。即,由u中的每个元素和v中的每个元素相乘得到的m × n阶矩阵A:

例如,当m=4, n=3时,有:

如果一个张量可以写成N个向量的外积,这个张量就是秩一张量。

其中张量中的每一个元素为:

张量分解中的一种最简洁的形式,张量CP分解,就是将任意某个张量,近似分解成一系列秩一张量的求和形式。

针对三维张量的CP分解,可用三维空间中X轴、Y轴、Z轴的外积,来可视化辅助理解:

CP分解的优点:计算速度快、显存占用低,由O(n3)降低到了O(n)级别。CP分解的缺点:紧凑性太高,可能需要许多组件(a1、a2、…、aR的数量)来对复杂场景进行建模,计算成本很高。为了折衷组件的数量和矩阵分解的效率,作者新提出了一种VM分解。
VM分解与CP分解相似, VM的含义是Vector-Matric,向量和矩阵的意思。相比于CP分解,这里有三项内容的加和,每一项有各自的组件数量R1,R2,R3,这三个值可以不同。相比原先,VM分解的显存占用也有所降低,O(n3)降低到了O(n2)级别。

针对三维张量的VM分解,可用三维空间中X、Y、Z轴分别与Y-Z、X-Z、X-Y平面的外积,来可视化辅助理解:

三、VM分解在NeRF中的具体使用
TensoRF:预先定义好,一组体密度特征相关的向量Vσ和矩阵Mσ,一组颜色特征相关的向量Vc和矩阵Mc。其中,density_plane代表体密度特征相关的矩阵,分别率为(128, 128),共有16个,(0)(1)(2)分别代表X-Y平面、Y-Z平面、X-Z平面。density_line代表体密度特征相关的向量,长度为128,共有16个,(0)(1)(2)分别代表Z平面、X平面、Y平面。同理,app_plane代表颜色特征相关的矩阵,app_line代表颜色特征相关的向量。

NeRF的本质:输入坐标位置x、观测方向d,预测体密度σ、颜色c。
TensoRF将空间体密度张量视为三维张量。在预测体密度σ时,输入坐标位置x,取出对应索引下体密度特征相关的向量、矩阵中的值,利用VM公式计算得到该点的体密度特征(标量) ,直接求和作为体密度σ 。
TensoRF将空间颜色特征张量视为四维张量。在预测颜色c时,输入坐标位置x,取出对应索引下颜色特征相关的向量、矩阵中的值,利用VM公式concatenate得到该点的颜色特征(144维的向量) ,用线性层转化成27维。定义MLP解码器,输入计算出的该点的颜色特征向量(27维)、观测方向d(3维),采用傅里叶编码并concatenate,利用线性层回归出该点位置的颜色c。
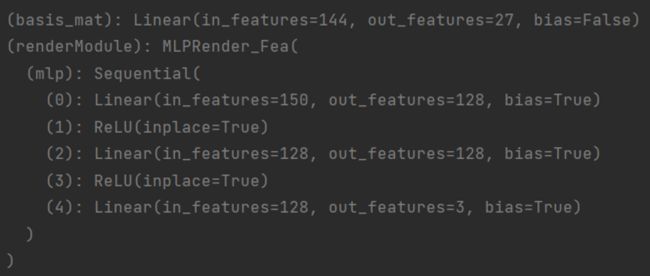
此处的MLP网络只负责解码,不负责提取特征(因为前面已经利用VM分解提取到了颜色特征),因此比原始NeRF的MLP还要简单很多,只有几个线性层。
在整个处理过程中,计算体密度特征、颜色特征向量时,采用的是离散建模,再插值采样的方式,因此认为是显式的;而计算颜色时,采用了MLP网络回归的方式,因此认为是隐式的。
和NeRF一样,TensoRF本质也是输入坐标位置x、观测方向d,预测体密度σ、颜色c。只不过在建模拟合函数时,引入了张量分解的技巧,利用张量分解先提取体密度σ、颜色c的特征,再对提取到的特征回归体密度σ、颜色c。

这里x表示坐标位置,d表示观测方向,Gσ表示插值采样得到的体密度特征, Gc表示插值采样得到的颜色特征向量,S表示MLP解码函数。
四、实验细节
以Lego数据集为例,采用TensoRF进行隐式三维重建。
训练集采用100张RGB图像,每张图像尺寸(800, 800, 3)。
整个建模的空间场景定义为一个长方体,XYZ三个分量坐标都是[-1.5, 1.5],建模的初始体素为[-1.5, 1.5] × [-1.5, 1.5] × [-1.5, 1.5]。 初始分辨率固定为128 × 128 × 128,即每个voxel的长宽高均为3/128=0.0234,后续会随着alpha Mask和上采样不断细化更新。
输入一个batch的三维坐标x、观测方向d。x: (bs, 3)、d: (bs, 3),整体流程可分为6步:
- 将x分解成X轴、Y轴、Z轴三个分量,即x1: (bs, 1)、 x2: (bs, 1)、 x3: (bs, 1),表示粒子在XYZ轴上各自的坐标数值。
- 根据粒子在XYZ轴上各自的坐标数值,在定义的16×3个体密度特征有关向量中插值采样,取出对应的数值: (bs, 16, 3);在定义的16*3个体密度特征有关矩阵中插值采样,取出对应的数值: (bs, 16, 3); 相乘后得到(bs, 16, 3),再全部求和累加,得到(bs, 1),即作为体密度σ。
- 根据粒子在XYZ轴上各自的坐标数值,在定义的48×3个颜色密度特征有关向量中插值采样,取出对应的数值: (bs, 48, 3);在定义的48*3个体密度特征有关矩阵中插值采样,取出对应的数值: (bs, 48, 3); 相乘后得到(bs, 48, 3),再全部拼接在一起,作为颜色特征: (bs, 144) 。
- 利用前面定义的线性层Linear(in_features=144, out_features=27, bias=False),也就是论文中的B矩阵,将颜色特征转换成: (bs, 27) 。
- 将颜色特征(bs, 27) 进行傅里叶编码[six(x), cos(x), sin(2x), cos(2x)],转换成(bs, 108) 。将观测方向(bs, 3) 进行编码,转换成(bs, 12) 。再加入原始值,concatenate得到(bs, 150) 。
- 将(bs, 150)输入MLP网络,经过三个线性层,最终输出(bs, 3),作为颜色c。
总结
TensoRF是第一个从张量的角度来看待辐射场建模,并提出了辐射场重建作为一个低秩张量重建的问题,整体思路非常巧妙,而且数学原理丰富,理论扎实。美中不足在于代码里的工程trick较多,特别是涉及到alpha mask的更新和体素上采样,细节非常复杂,还是不够简洁优美。
从实验效果来看,TensoRF的渲染效果其实并不算特别惊艳,但确实是大幅减少了NeRF的训练时间,并且降低了渲染所需要的显存,总体而言是令人眼前一亮的工作。