【yolov8】与yolov5的区别及改进详解
图像识别技术在物联网、智能监控等领域广泛应用。而深度学习中的目标检测技术,能够帮助我们对图像中的目标进行识别,进而实现自动化控制。目前,Yolov8和Yolov5是目标检测领域热门的模型。
- yolo目标检测原理
- yolov5详解
- yolov8
-
- yolov8结构图
- Conv模块
- C2f模块和C3模块
- 耦合头Coupled Head和解耦头 Decoupled Head
- Anchor-Based和Anchor-free
-
- Anchor-Based
- Anchor-free
- 总结:
yolo目标检测原理
使用yolo进行目标检测的主要思想是将目标检测任务转化为一个回归问题,通过前向传播过程完成目标的定位和分类。yolo通常采用backbone-neck-head的网络结构。
- Backbone 主要负责从输入图像中提取高层次的语义特征。这些特征对于目标检测等任务非常关键,因为它们捕获了图像中的上下文和抽象信息。backbone通常包含多个卷积层和池化层,构建了一个深层次的特征提取器。
- Neck位于backbone和head之间,通常用来进一步整合调整由backbone提取的特征,有利于将不同层次的特征融合,提升网络对目标的感知能力
- Head检测头负责将目标进行定位和分类,生成最终的目标检测结果。head通常包括边界框回归层(用于预测目标的位置)和分类层(用于预测目标的类别)。
yolov5详解
v5的模块详解早就准备好了
yolov8
YOLOv8是Ultralytics公司于2023年1月10日发布的YOLOv5的下一个重大更新版本。它是一种用于目标检测的先进深度学习算法,支持图像分类、物体检测和实例分割任务。
yolov5和yolov8的推理过程几乎一样,在backbone和neck部分,两者都使用了CSP梯度分流的思想,且都使用了SPPF模块,不同的是yolov8使用梯度流更丰富的C2f结构,对不同尺度模型调整了不同的通道数。在head部分,将之前的耦合头结构换成了目前主流的解耦头结构,将分类和检测头分离,同时也从Anchor-Based换成了Anchor-Free。
yolov8结构图

将yolov8和yolov5结构图对比可发现,yolov5中的C3模块全部替换成C2f模块。
Conv模块

Conv 模块由单个 Conv2d、BatchNorm2d 和激活函数构成,用于提取特征并整理特征图
Conv模块中Conv2d的paddingg是自动计算的,通过修改stride来决定特征图缩小的倍数。在backbone中Conv模块的stride全部为2,kernel均为3。因此Conv每次会将特征图的宽高减半,下采样特征图,同时提取到目标特征。
BatchNorm2d为批归一化层,对每批的数据做归一化,能够有效地加速神经网络的训练过程,提高模型的泛化能力。
SiLu为激活函数,增加了数据的非线性。
C2f模块和C3模块

YOLOv8 参考了 C3 模块的残差结构以及YOLOv7的 ELAN 思想,设计出了 C2f 结构,可以在保证轻量化的同时获得更加丰富的梯度流信息,并根据模型尺度来调整通道数,大幅提升了模型性能;
可以看到,C2f模块相比于C3模块有更多的跳层连接,并增加了额外的split操作,取消了分支中的卷积操作,这样丰富了梯度回传时的支流,加强了特征信息并减少计算量。
耦合头Coupled Head和解耦头 Decoupled Head
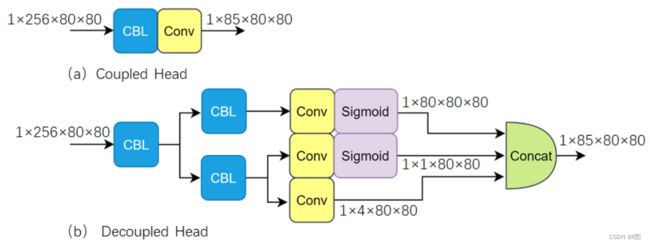
耦合头的设计是在网络的末尾,通过一系列的卷积和全连接层,同时预测不同尺度的边界框位置、尺寸和类别。这种设计使得YOLOv5可以在不同尺度上并行地进行目标检测,即使用一层卷积同时完成分类和定位任务。
解耦头的设计是将分类和检测头分离,两条并行的分支分别取提取类别特征和位置特征,然后各用一层1×1卷积完成分类和定位任务。以提高目标检测的准确性。
Decoupled Head不仅是模型精度上会提高,同时网络的收敛速度也加快了,使用Decoupled Head的表达能力更好,增强了模型的鲁棒性,可以更好地建模位置和类别之间的关系,提高目标检测性能。。
Anchor-Based和Anchor-free
anchor也叫做锚,预先设置目标可能存在的大概位置,然后再在这些预设边框的基础上进行精细化的调整。而它的本质就是为了解决标签分配的问题。
目标检测领域的发展从anchor-free到anchor-base,现在又有回到anchor-free的趋势。
anchor-free和anchor-based是两种不同的目标检测方法,区别在于是否使用预定义的anchor框来匹配真实的目标框。
Anchor-Based
在同一个像素点上,生成多个不同大小和比例的候选框,覆盖几乎所有位置和尺度,每个参考框负责检测与其交并比大于阈值 (训练预设值,常用0.5或0.7) 的目标,然后通过anchor中有没有认识的目标和目标框偏离参考框的偏移量完成目标检测,不再需要多尺度遍历滑窗,极大的提升了速度。
在训练过程中,模型学习预测每个锚框的偏移量(相对于真实目标框的偏移),以调整它们以更好地匹配目标的位置。模型还负责为每个锚框预测目标类别。
通常,在预测结束后,采用NMS非极大值抑制来排除高度重叠的锚框,以确保每个目标只有一个最终的检测结果。
优点:
适用于多尺度和多宽高比的目标。
对于密集目标排列的情况,锚框可以提高检测性能。
缺点
对于目标数量较少的情况,锚框设计可能浪费计算资源。
对于小目标检测较为困难。
Anchor-free
无锚框在构建模型时将其看作一个点,即目标框的中心点。不依赖于预定义的锚框,而是直接预测目标的中心点。直接学习目标框的位置,通常通过回归目标框的四个顶点坐标来实现。
同样,模型负责为每个目标预测其类别,在预测结束后,采用NMS进行后处理。
优点:
相对简洁,无需设计大量的锚框。
更适合小目标检测。
缺点
对于多尺度和多宽高比的目标,可能性能较差。
在密集目标排列的情况下,容易出现定位不准确的问题。
总结:
YOLOv8 模型包括 Input、Backbone、Neck 和 Head 4部分。其中Input选用了Mosaic数据增强方法,并且对于不同大小的模型,有部分超参数会进行修改,典型的如大模型会开启 MixUp 和 CopyPaste数据增强,能够丰富数据集,提升模型的泛化能力和鲁棒性。Backbone 主要用于提取图片中的信息,提供给Neck和Head使用。Neck 部分主要起特征融合的作用,充分利用了骨干网络提取的特征,采用FPN +PAN结构,能够增强多个尺度上的语义表达和定位能力。Head输出端根据前两部分处理得到的特征来获取检测目标的类别和位置信息,做出识别。
yolov8和yolov5结构大体一致,不同的是yolov8主干网络使用的时梯度流更丰富的C2f模块,将分类和检测头分离,解决了分类和定位关注侧重点不同的问题,同时也采用了无锚框的目标检测,能够提升检测速度。