【论文复现】使用PaddleDetection复现OrientedRepPoints的复现笔记
1 复现流程
复现流程表:
- 翻译原始论文;
- 学习PaddleDetection配置参数
- 对齐Dataloader;
2 MMRotate代码
2.1 配置mmrotate环境
官方安装文档:INSTALLATION — mmrotate documentation
Clone原始模型代码
git clone https://github.com/open-mmlab/mmrotate.git mmrotate_oriented_reppoints
安装openmim
python -m pip install -U openmim -i https://pypi.tuna.tsinghua.edu.cn/simple
安装mmcv
mim install mmcv-full -i https://pypi.tuna.tsinghua.edu.cn/simple
安装mmdet
mim install mmdet -i https://pypi.tuna.tsinghua.edu.cn/simple
以项目源码安装mm
pip install -v -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
参数说明:
-v: means verbose, or more output.-e: means installing a project in editable mode, thus any local modifications made to the code will take effect without reinstallation.
验证mmrotate安装时出现错误:“RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)”
在使用mmrotate官方示例验证其安装时,出现错误:
[mmrotate_oriented_reppoints]:
…
File “d:\professional\xxx\mmrotate\models\roi_heads\bbox_heads\rotated_bbox_head.py”, line 418, in get_bboxes
det_bboxes, det_labels = multiclass_nms_rotated(
File “d:\professional\xxx\mmrotate\core\post_processing\bbox_nms_rotated.py”, line 58, in multiclass_nms_rotated
bboxes, scores, labels = bboxes[inds], scores[inds], labels[inds]
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
(1)将测试命令修改为使用cpu进行推理:
python demo/image_demo.py demo/demo.jpg oriented_rcnn_r50_fpn_1x_dota_le90.py oriented_rcnn_r50_fpn_1x_dota_le90-6d2b2ce0.pth --out-file result.jpg --device cpu
(2)将出错位置的张量索引操作改成一致的设备
大概率出错的是这两句代码:
def assign(self,
points,
gt_rbboxes,
gt_rbboxes_ignore=None,
gt_labels=None,
overlaps=None):
......
gt_bboxes_wh = (gt_bboxes[:, 2:] - gt_bboxes[:, :2]).clamp(min=1e-6)
scale = self.scale
gt_bboxes_lvl = ((torch.log2(gt_bboxes_wh[:, 0] / scale) +
torch.log2(gt_bboxes_wh[:, 1] / scale)) / 2).int()
gt_bboxes_lvl = torch.clamp(gt_bboxes_lvl, min=lvl_min, max=lvl_max)
# stores the assigned gt index of each point
assigned_gt_inds = points.new_zeros((num_points, ), dtype=torch.long)
# stores the assigned gt dist (to this point) of each point
assigned_gt_dist = points.new_full((num_points, ), float('inf'))
points_range = torch.arange(points.shape[0]) # NOT specify a device
for idx in range(num_gts):
gt_lvl = gt_bboxes_lvl[idx]
# get the index of points in this level
lvl_idx = gt_lvl == points_lvl
points_index = points_range[lvl_idx] # <-- error1
...
# the index of nearest k points to gt center in this level
min_dist_points_index = points_index[min_dist_index] # <-- error2
我看了一下,points_index也是来自于points_range,很大的可能性是points_range的设备不一致,然后track上去,发现points_range = torch.arange(points.shape[0])这一句代码没有显示指定设备,可能会分配到CPU上从而引发错误,于是把代码修改为:
points_range = torch.arange(points.shape[0]).to(gt_bboxes_lvl.device) # 跟gt_bboxes_lvl的设备保持一致
2.2 数据集配置:DOTA1.0
2.2.1 在Win11上使用mklink创建软链接
示例代码:
mklink /j "D:\Professional\Paddle\mmrotate_oriented_reppoints\data\DOTA" "D:\Professional\Paddle\DOTA"
2.2.2 数据集目录结构
mmrotate
├── mmrotate
├── tools
├── configs
├── data
│ ├── DOTA
│ │ ├── train
│ │ ├── val
│ │ ├── test
2.2.3 划分数据集:mmrotate: split dota dataset
Note:
原始论文切图的方式是这样的:
We crop the original images into the patches of 1024 × 1024 with a stride of 824.
所以,可以看到原始论文没有使用 ms-split 的方式切分数据集。
1024×1024 patches with an overlap of 200 [mmrotate]
Note:
可以看到原始论文中的描述跟MMRotate官方repo使用的切图方式是一致的,因为 overlap = 200 和 stride = 824 是等价的,因为 200 + 824 = 1024,刚好就是图像的宽度1024。
Ss_trainval:
python tools/data/dota/split/img_split.py --base-json tools/data/dota/split/split_configs/ss_trainval.json
Ss_test:
python tools/data/dota/split/img_split.py --base-json tools/data/dota/split/split_configs/ss_test.json
标注说明
| 717.0 | 76.0 | 726.0 | 78.0 | 722.0 | 95.0 | 714.0 | 90.0 | small-vehicle | 0 |
|---|---|---|---|---|---|---|---|---|---|
| x1 | y1 | x2 | y2 | x3 | y3 | x4 | y4 | category | is_hard_sample |
修改数据集配置文件:configs/_base_/datasets/dotav1.py
将data_root修改为:
# dataset settings
dataset_type = 'DOTADataset'
data_root = 'data/split_ss_dota/'
2.3 训练设置
原始论文训练环境
4 * RTX 2080Ti
训练命令
python tools/train.py configs/oriented_reppoints/oriented_reppoints_r50_fpn_40e_dota_ms_le135.py
2.4 可视化
可视化数据集
python tools/misc/browse_dataset.py configs/oriented_reppoints/oriented_reppoints_r50_fpn_40e_dota_ms_le135.py
2.5 自定义Hooks
MMRotate官方教程:Customize self-implemented hooks
2.6 类和函数说明
2.6.1 模型类
RotatedRepPoints
init_weights()
初始化RotatedRepPoints模型,包括载入主干网络的预训练权重;
Parameters: none
Scenarios:
- 在
tools/train.py中,用于初始化模型参数,包括载入主干网络的预训练权重;
2.7 Troubleshooting
I. 出现错误:from collections import Sequence, ImportError: cannot import name ‘Sequence’ from ‘collections’
我们在运行tools/misc/browse_dataset.py出现了错误:
Traceback (most recent call last):
File "D:\Professional\Paddle\mmrotate_oriented_reppoints\tools\misc\browse_dataset.py", line 4, in <module>
from collections import Sequence
ImportError: cannot import name 'Sequence' from 'collections' (C:\Users\xxx\.conda\envs\openmmlab\lib\collections\__init__.py)
其主要原因是python从3.9开始需要从collections.abc而不是collections中导入Sequence抽象类;
所以需要修改browse_dataset.py的源码,将原始语句
from collections import Sequence
改成
from collections.abc import Sequence
II. 重新配置conda环境时,出现错误:“OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.”
相关信息如下:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
Process finished with exit code 3
主要原因是OMP在首次运行时,发现当前conda环境中已经存在libiomp5md.dll而引发冲突;(具体错误原因的分析,请参考知乎文章《关于OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.错误解决方法》)
解决方法:
将当前conda环境彻底删除(在envs文件夹中确认此env文件夹已经删除),然后再重新配置conda环境;
3 PaddleDetection学习笔记
3.1 配置环境&Clone代码
创建conda环境:
conda create --name conda-paddle python=3.10
Clone代码:
git clone https://github.com/PaddlePaddle/PaddleDetection.git Paddle_oriented_reppoints
3.1.1 PaddleRorate算子编译
Visual Studio配置说明
PaddleRorate在文档中并没有提供适合于Win11平台算子编译的配置说明;
我们感觉似乎是直接安装 Visual Studio 生成工具 就可以了;
进入旋转检测算子目录
Win11
切换E盘分区:
E:
进入旋转算子目录:
cd E:\Professional\Paddle\Paddle_oriented_reppoints\ppdet\ext_op
Troubleshooting
(1)报错:C:\Users…\lib\site-packages\paddle\include\paddle/phi/api/include/tensor.h(23): fatal error C1083: 无法打开包括文件: “cuda_runtime.h”: No such file or directory
今天我们尝试使用conda来配置CUDA的编译环境,在编译算子时出现了这样的错误:
C:\Users\xxx\anaconda3\envs\conda-paddle\lib\site-packages\paddle\include\paddle/phi/api/include/tensor.h(23): fatal error C1083: 无法打开包括文件: “cuda_runtime.h”: No such file or directory
error: command ‘C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Tools\MSVC\14.34.31933\bin\HostX64\x64\cl.exe’ failed with exit code 2
也就是paddle无法找到cuda_runtime.h头文件;
解决方案:
使用conda安装cuda-cudart-dev包,安装 cuda_runtime 的C++函数库,包括cuda_runtime.h头文件;
具体的安装命令请参考Nvidia官方conda源:nvidia / packages / cuda-cudart-dev
Note:
注意cuda-cudart-dev中CUDA主版本号与paddle保持一致,例如:paddle在安装时使用CUDA11.7,则cuda-cudart-dev也要选择CUDA11的版本。
3.2 数据集配置:DOTA数据集
Note:
MMRotate中不是使用标准COCO格式作为标注文件的,所以这里我们不能直接PaddleDetection中已有的数据读取类,而需要复现MMRotate中的数据读取类。
3.2.1 定义PaddleDetection格式数据集
官方教程:使用PP-YOLOE-R进行旋转框检测 - 飞桨AI Studio (自定义数据集章节)
PaddleDetection格式:COCO多边形标注
{ "id": int, // 目标实例唯一标志符
"image_id": int, // 所属的图像文件
"category_id": int, // 对应的类别
"segmentation": [polygon], // 实例多边形标注
"area": float, // 标注区域的面积
"bbox": [x,y,width,height],
"iscrowd": 0, // 0:单个目标实例
}
设置文件夹路径
Win11命令:
对数据集目录创建软链接
New-Item -ItemType SymbolicLink -Path "D:\Professional\Paddle\Paddle_oriented_reppoints\dataset\dota\data" -Target "D:\Professional\Paddle\mmrotate_oriented_reppoints\data"
设置trainval目录
New-Item -ItemType SymbolicLink -Path "D:\Professional\Paddle\Paddle_oriented_reppoints\dataset\dota\trainval" -Target "D:\Professional\Paddle\mmrotate_oriented_reppoints\data\split_ss_dota\trainval"
设置test目录
New-Item -ItemType SymbolicLink -Path "D:\Professional\Paddle\Paddle_oriented_reppoints\dataset\dota\test" -Target "D:\Professional\Paddle\mmrotate_oriented_reppoints\data\split_ss_dota\test"
工作空间中DOTA数据集目录
$DOTA_ROOT = "D:\Professional\Paddle\Paddle_oriented_reppoints\DOTA_ROOT"
多尺度切图
Win11命令:
对于有标注的数据进行切图(train & val)
python configs/rotate/tools/prepare_data.py `
--input_dirs ${DOTA_ROOT}/train/ ${DOTA_ROOT}/val/ `
--output_dir ${OUTPUT_DIR}/trainval/ `
--coco_json_file DOTA_trainval1024.json `
--subsize 1024 `
--gap 500 `
--rates 0.5 1.0 1.5
对于无标注的数据进行切图需要设置 --image_only(test)
python configs/rotate/tools/prepare_data.py `
--input_dirs ${DOTA_ROOT}/test/ `
--output_dir ${OUTPUT_DIR}/test1024/ `
--coco_json_file DOTA_test1024.json `
--subsize 1024 `
--gap 500 `
--rates 0.5 1.0 1.5 `
--image_only
3.3 PaddleDetection配置文件说明
_BASE_:基础配置
‘…/…/datasets/dota.yml’:DOTA数据集配置文件
‘…/…/runtime.yml’:运行时配置
模型配置
pretrain_weights:主干网络预训练权重
可以使用权重文件的URL或者本地文件路径。
3.4 数据变换:sample_transforms
3.4.1 RandomRFlip:旋转框随机翻转
3.4.2 自定数据处理算子 [doc]
| MMRotate | PPDetection | Description |
|---|---|---|
__call__() |
apply() |
单个样本处理函数 |
'flip' |
'flipped' |
是否对进行了翻转操作 |
3.4 新增模型类:OrientedReppoints
Step1:在ppdet/modeling/architectures中添加oriented_reppoints.py文件;
Step2:在文件中加入OrientedReppoints模型类实现;
Step3:在ppdet/modeling/architectures/__init__.py加入引用语句:
...
from . import s2anet
from . import oriented_reppoints
...
...
from .s2anet import *
from .oriented_reppoints import *
...
3.5 Troubleshooting
(1)出现错误:if isinstance(parameters[0], dict): IndexError: list index out of range
在复现模型时,遇到这样一个错误:
Traceback (most recent call last):
File "C:\Users\xxx\AppData\Local\JetBrains\Toolbox\apps\PyCharm-C\ch-0\223.7571.203\plugins\python-ce\helpers\pydev\pydevd.py", line 1496, in _exec
pydev_imports.execfile(file, globals, locals) # execute the script
File "C:\Users\xxx\AppData\Local\JetBrains\Toolbox\apps\PyCharm-C\ch-0\223.7571.203\plugins\python-ce\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "D:\Professional\Paddle\Paddle_oriented_reppoints\tools\train.py", line 172, in <module>
main()
File "D:\Professional\Paddle\Paddle_oriented_reppoints\tools\train.py", line 168, in main
run(FLAGS, cfg)
File "D:\Professional\Paddle\Paddle_oriented_reppoints\tools\train.py", line 123, in run
trainer = Trainer(cfg, mode='train')
File "D:\Professional\Paddle\Paddle_oriented_reppoints\ppdet\engine\trainer.py", line 158, in __init__
self.optimizer = create('OptimizerBuilder')(self.lr, self.model)
File "D:\Professional\Paddle\Paddle_oriented_reppoints\ppdet\optimizer\optimizer.py", line 347, in __call__
return op(learning_rate=learning_rate,
File "C:\Users\xxx\.conda\envs\conda-paddle\lib\site-packages\paddle\optimizer\momentum.py", line 148, in __init__
if isinstance(parameters[0], dict):
IndexError: list index out of range
原因是因为刚刚新建模型,而模型目前没有注册任何模块,于是就不包含参数,在框架内部遍历parameters的时候,就会报错;
临时的解决方案,我们是在OrientedRepPoints添加了一个nn.Conv2D模块,方便后续进行调试;
(2)出现错误:Config annotation dataset/dota/trainval/ms_trainval_coco.json is not a file, dataset config is not valid
今天在设置数据集时,出现了下面的错误:
[12/27 21:17:08] ppdet.utils.download WARNING: Config annotation dataset/dota/trainval/ms_trainval_coco.json is not a file, dataset config is not valid
[12/27 21:17:08] ppdet.utils.download INFO: Dataset D:\Professional\Paddle\Paddle_oriented_reppoints\dataset\dota is not valid for reason above, try searching C:\Users\xxx/.cache/paddle/dataset or downloading dataset…
Traceback (most recent call last):
File “D:\Professional\Paddle\Paddle_oriented_reppoints\tools\align.py”, line 174, in
main()
File “D:\Professional\Paddle\Paddle_oriented_reppoints\tools\align.py”, line 170, in main
run(FLAGS, cfg)
File “D:\Professional\Paddle\Paddle_oriented_reppoints\tools\align.py”, line 125, in run
trainer = TrainAligner(cfg, mode=‘train’)
File “D:\Professional\Paddle\Paddle_oriented_reppoints\ppdet\engine\train_aligner.py”, line 99, in init
self.loader = create(‘{}Reader’.format(capital_mode))(
File “D:\Professional\Paddle\Paddle_oriented_reppoints\ppdet\data\reader.py”, line 162, in call
self.dataset.check_or_download_dataset()
File “D:\Professional\Paddle\Paddle_oriented_reppoints\ppdet\data\source\dataset.py”, line 99, in check_or_download_dataset
self.dataset_dir = get_dataset_path(self.dataset_dir, self.anno_path,
File “D:\Professional\Paddle\Paddle_oriented_reppoints\ppdet\utils\download.py”, line 225, in get_dataset_path
raise ValueError(
ValueError: Dataset dataset/dota/ is not valid and cannot parse dataset type ‘’ for automaticly downloading, which only supports ‘voc’ , ‘coco’, ‘wider_face’, ‘fruit’, ‘roadsign_voc’ and ‘mot’ currently进程已结束,退出代码1
可以看到,提示性比较明显的报错信息就是:Config annotation dataset/dota/trainval/ms_trainval_coco.json is not a file, dataset config is not valid;
就是提示设置的数据集json文件路径无效,需要检查一下数据集标注文件的路径是否正确;
在本项目中,也就是需要检查configs/datasets/dotav1.yml中json标注文件的路径;
4 超参数一览表
| Name | param |
|---|---|
| Input size | 1333×768, 1333×1280 |
| Type | float32 |
5 Reprod_log学习笔记
5.1 安装命令
python -m pip install reprod_log --force-reinstall -i https://pypi.tuna.tsinghua.edu.cn/simple
5.2 函数和类
ReprodLogger:记录张量数据
使用示例:reprod_log_demo/write_log.py
5.3 导出张量数据
# TODO: export feat
reprod_log = ReprodLogger()
reprod_log.add(f"pool_feat", x.detach().cpu().numpy())
reprod_log.save("output/mm_pool_feat.npy")
print("Quit")
quit()
5.4 对齐张量
模板:
# TODO: align feat
reprod_log = ReprodLogger()
reprod_log.add("pool_feat", x.numpy())
reprod_log.save("temp/pp_pool_feat.npy")
# 开始比较精度差异
diff_helper = ReprodDiffHelper()
info1 = diff_helper.load_info("mm_output/mm_pool_feat.npy")
info2 = diff_helper.load_info("temp/pp_pool_feat.npy")
diff_helper.compare_info(info1, info2)
diff_helper.report(
diff_method="mean", diff_threshold=1e-6, path="./diff.txt")
print("Quit")
quit()
6 重写配置文件
6.1 超参数换算表
| mmrorate | paddleDetection |
|---|---|
| lr_config.step | schedulers.milestones = step - 1 |
| Backbone: | |
| frozen_stages (1) | freeze_at = frozen_stages - 1 (0) |
| out_indices | return_idx = out_indices |
| FPN: | |
| start_level | extra_stage = start_level + 1 |
| Head: | |
| anchor_generator.scales | anchor_scales = scales |
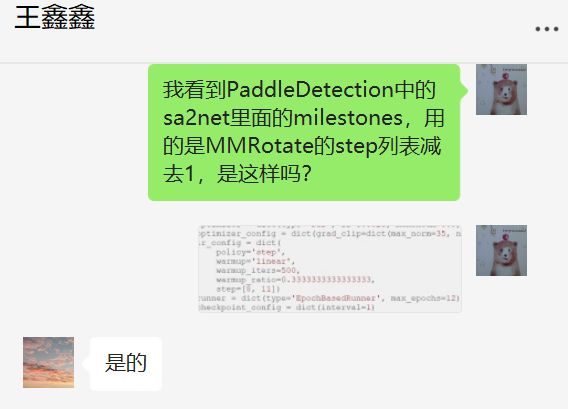
关于schedulers.milestones的设置
这个我已经跟鑫鑫确认了,schedulers.milestones = step - 1,聊天记录如下:
7 模块权重转换
7.1 参考资料
俏斌分享的模型权重转换代码:Py_torch2paddle
8 校对目录设置
New-Item -ItemType SymbolicLink -Path "D:\Professional\Paddle\Paddle_oriented_reppoints\mm_output" -Target "D:\Professional\Paddle\mmrotate_oriented_reppoints\output"
9 模型类:OrientedRepPoints
9.1 MM模型类:RotatedRepPoints

8 主干网络:ResNet
8.1 主干网络对齐记录:5e-4
主干网络的对齐精度,我们使用的阈值是5e-4,对齐结果如下:
[2023-01-11 16:34:50,637] [ INFO] utils.py:118 - feat0:
[2023-01-11 16:34:50,638] [ INFO] utils.py:123 - mean diff: check passed: True, value: 3.343301841596258e-06
[2023-01-11 16:34:50,638] [ INFO] utils.py:118 - feat1:
[2023-01-11 16:34:50,638] [ INFO] utils.py:123 - mean diff: check passed: True, value: 3.4712193155428395e-05
[2023-01-11 16:34:50,638] [ INFO] utils.py:118 - feat2:
[2023-01-11 16:34:50,638] [ INFO] utils.py:123 - mean diff: check passed: True, value: 3.119021494057961e-05
[2023-01-11 16:34:50,638] [ INFO] utils.py:118 - feat3:
[2023-01-11 16:34:50,638] [ INFO] utils.py:123 - mean diff: check passed: True, value: 0.00023211663938127458
[2023-01-11 16:34:50,639] [ INFO] ReprodDiffHelper.py:64 - diff check passed
8.1 PPDet-ResNet 无法跟 MMRotate-ResNet 对齐
今天我们在对齐主干网络时,发现 PPDet-ResNet 无法跟 MMRotate-ResNet 对齐,其现象如下:
[2022-12-29 20:11:26,130] [ INFO] utils.py:118 - input:
[2022-12-29 20:11:26,130] [ INFO] utils.py:123 - mean diff: check passed: True, value: 3.0450131305315153e-08
[2022-12-29 20:11:26,131] [ INFO] ReprodDiffHelper.py:64 - diff check passed
[2022-12-29 20:11:30,990] [ INFO] utils.py:118 - feat0:
[2022-12-29 20:11:30,991] [ INFO] utils.py:123 - mean diff: check passed: False, value: 0.16119591891765594
[2022-12-29 20:11:30,991] [ INFO] utils.py:118 - feat1:
[2022-12-29 20:11:30,991] [ INFO] utils.py:123 - mean diff: check passed: False, value: 0.1201038584113121
[2022-12-29 20:11:30,991] [ INFO] utils.py:118 - feat2:
[2022-12-29 20:11:30,992] [ INFO] utils.py:123 - mean diff: check passed: False, value: 0.06433149427175522
[2022-12-29 20:11:30,992] [ INFO] utils.py:118 - feat3:
[2022-12-29 20:11:30,992] [ INFO] utils.py:123 - mean diff: check passed: False, value: 0.3645188808441162
[2022-12-29 20:11:30,992] [ INFO] ReprodDiffHelper.py:66 - diff check failed
可以看到输入张量input是可以对齐的,但是后面主干网络输出的多个feat都无法对齐;
8.2 参数字典
| MMRotate | PPDetection | Description |
|---|---|---|
| conv1.weight | conv1.conv1.conv.weight | (64, 3, 7, 7) |
| bn1: | conv1.conv1.norm: | BN |
| bn1.weight | conv1.conv1.norm.weight | (64) |
| bn1.bias | conv1.conv1.norm.bias | (64) |
| bn1.running_mean | conv1.conv1.norm._mean | (64) |
| bn1.running_var | conv1.conv1.norm._variance | (64) |
| bn1.num_batches_tracked | - | - |
| layer1.0: | res2.res2a.branch2a: | |
| layer1.0.conv1.weight | res2.res2a.branch2a.conv.weight | (64, 64, 1, 1) |
| layer1.0.bn1: | res2.res2a.branch2a.norm: | BN |
| layer1.0.bn1.weight | res2.res2a.branch2a.norm.weight | (64) |
| layer1.0.bn1.bias | res2.res2a.branch2a.norm.bias | (64) |
| layer1.0.bn1.running_mean | res2.res2a.branch2a.norm._mean | (64) |
| layer1.0.bn1.running_var | res2.res2a.branch2a.norm._variance | (64) |
| layer1.0.bn1.num_batches_tracked | - | - |
9 训练指令
Win11:
set CUDA_VISIBLE_DEVICES=0 | python tools/train.py -c configs/rotate/oriented_reppoints/oriented_reppoints_r50_40e_ms_dota.yml