MySQL关系型数据库管理系统_day02
MySQL:关系型数据库管理系统_day02
一、DQL查询数据
1.简单查询
-- 语法格式:
select 字段名1,字段名2,... from 表名;
-- 查询所有的字段可以使用 * , * 代表所有的字段
select * from 表名;
--定义别名,将对应的字段名替换成中文,as可以省略
select 字段名1 as '中文',
字段名2 as '中文',
字段名3 as '中文'
from 表名;
-- 使用去重查询 关键字 distinct,去除重复的数据
select distinct 字段名 from 表名;
注意:查询不会对数据库中的数据进行修改, 只是一种显示数据的方式。
查询的字段可以进行数学计算,函数操作,…
2.条件查询
如果不添加条件会查到所有信息,在应用过程中一般都会对查到的数据进行过滤
-- 语法格式:
select 列名 from 表名 where 条件;
/*条件:
> < >= <= != <>
and && 多个条件同时成立
between ... and ... 区间值(前后包含)
or || 多个条件成立任意一个即可
not 取反
in(值,值,...) 等于任意一个值即可*/
注意:值为null,判断时,is null is not null
执行顺序:
1.从哪个表查询 from
2.按照指定条件过滤 where
3.指定返回的字段值 select
3.模糊查询
-- like关键字配合通配符
-- % 匹配0-多个
-- _ 匹配1-多个
select * from 表名 where 字段名 like '通配符组合';
4.排序
将查询出的结果按照指定的要求排序。(关键字 order by)
4.1单列排序
-- 默认升序(asc)也可以设置降序(desc)
select 字段,字段,... from 表 [where 条件] order by 字段[asc|desc];
4.2多列排序(组合排序)
按照指定多个列中的值进行排序,先按照指定的第一个列中的值排序,出现重复再按照第二个列中的值排序。
select 字段,字段,... from 表 [where 条件] order by 字段[asc|desc],字段[asc|desc];
5.函数
函数:(方法)将具体的操作封装在方法中,调用方法,完成相关的操作
5.1单行函数
对一行中的数据进行操作,操作多少行返回多少行。
5.1.1字符串函数
lower(字段名)--------->.将字母转换为小写。
upper(字段名)--------->.将字母转换为大写
注意:对中文不生效!!!!!!!!!
length(字段名)------------>返回占用的字节数
注意:utf-8编码中一个中文占用3个字节!!!!
concat(字段名,‘要拼接的字符’)--------------------->字符串拼接
注意:括号里内容位置不固定,以实际为准!!!!
lpad(要填充的字段名,填充到几位,‘要填充的内容’)--------------------->左侧填充
rpad(要填充的字段名,填充到几位,‘要填充的内容’)--------------------->右侧填充
ltrim(字段名)---------------------------->去除左侧空格
rtrim(字段名)---------------------------->去除右侧空格
trim(字段名)---------------------------->去除两侧空格
replace(要进行替换操作的字段名,“要被替换的字符”,“新字符”)------------>替换指定字符
reverse(要进行操作的字段名)--------------->字符串翻转
substr|substring(要截取的字段名,开始位置,截取长度)----------->字符串截取
注意:截取函数起始位置是1!!!
5.1.2其他单行函数
-- 数值函数
-- abs(数值)---------->绝对值函数
select abs(1), abs(-2) from dual;
-- dual表示虚表,可以省略
select abs(1), abs(-2)
ceil(3.5)------------->获取比当前数大的最小整数
floor(3.5)------------>获取比当前数小的最大整数
mod(3,2)-------------->返回余数
pi()------------------>输出pi
pow(2,3)-------------->幂运算
rand()---------------->生成一个0-1之间的随机函数,包含0,不包含1
round(1.245, 2)------->保留对应的位数并四舍五入
truncate(1.245,2)---->只保留对应的位数
-----------------------------------------------
-- 日期函数
curdate()---------->返回当前日期
curtime()---------->返回当前时间
now()-------------->返回当前日期和时间
sysdate()---------->返回该函数执行时的日期和时间
------------------------------------------------
-- 流程控制函数
if(条件, t, f)-------------->如果条件为真,则返回t,否则返回f
ifnull(value1, value2)----->如果value1不为null,则返回value1,否则返回value2
nullif(value1, value2)----->如果value1等于value2,则返回null,否则返回value1
case
when 条件1 then 结果1
when 条件2 then 结果2
when 条件3 then 结果3----------->多用于等值匹配,类似于swich
when 条件4 then 结果4
else 结果5
end``
#### 5.2.多行函数(分组函数 | 聚合函数)
对一列中的数据进行操作,最终返回一个结果。
##### 5.2.1具体的函数
max() ------------>最大值
min()-------------->最小值
sum() ------------->求和
avg()--------------->平均值
count()----------->个数
count(主键|具体数值)
***注意:多用于统计,自动忽略null值***
### 6.分组
```sql
-- 按照指定的字段值分组,相同的值分为1组。
select 分组字段/聚合函数 from 表名 group by 分组字段 [having 条件];
6.1执行顺序
1.from 找表
2.where 过滤
3.group by 分组
4.select 返回需要的数据(分组字段,分组的统计)
总结:from – where – group by – having –- select – order by
6.2 where与having的区别
相同点:都是过滤数据的操作
不同点:where:分组之前执行,不允许使用分组函数
having:分组之后执行,允许使用分组函数
7.limit关键字(MySQL方言)
select 字段1, 字段2 ... from 表名 limit offset, length;
-- offset 起始行数, 从0开始, 如果省略则默认从0开始, 0代表MySQL中第一条数据
-- length 返回的行数
二、SQL执行流程
1.流程图
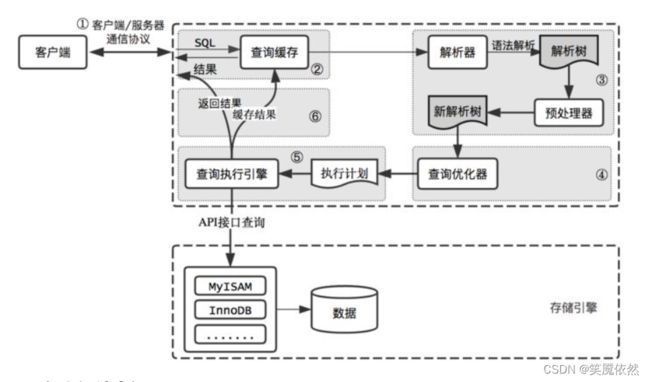
2. 执行流程各部分的作用
2.1查询缓存
将查询的数据缓存起来,下次查询同样的语句时直接返回缓存的结果,由于命中率太低,mysql8被删除
2.2解析器
-
词法分析:抓关键字、表名、字段名等
-
语法分析:查看是否满足mysql语法
3.生成新的解析树
2.3 优化器
对sql语句执行顺序进行优化,生成最优的执行计划交给执行器
2.4执行器
操作存储引擎执行sql语句
3.流程图简化
