【改进YOLOV8】融合EfficientViT骨干网络的车辆颜色车牌识别系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义:
随着交通事故的不断增加和交通管理的日益重要,车辆识别系统在交通领域中的应用变得越来越重要。车辆颜色和车牌识别系统是车辆识别系统中的一个重要组成部分,它可以帮助交通管理部门监控交通流量、追踪犯罪嫌疑人以及实施交通违法行为的监管。因此,提高车辆颜色和车牌识别系统的准确性和效率对于交通管理具有重要意义。
目前,基于深度学习的目标检测算法在车辆颜色和车牌识别系统中取得了显著的成果。其中,YOLO(You Only Look Once)算法是一种非常流行的目标检测算法,它通过将目标检测任务转化为回归问题,实现了实时的目标检测。然而,YOLO算法在处理小目标和密集目标时存在一定的困难,而且对于复杂场景中的车辆颜色和车牌识别任务,其准确性和鲁棒性还有待提高。
为了解决这些问题,本研究提出了一种改进的YOLOV8算法,该算法融合了EfficientViT(Efficient Vision Transformer)骨干网络。EfficientViT是一种基于Transformer的轻量级图像分类网络,它通过引入注意力机制和多头自注意力机制,有效地捕捉图像中的全局和局部特征。将EfficientViT作为YOLOV8的骨干网络,可以提高车辆颜色和车牌识别系统的准确性和鲁棒性。
本研究的主要目标是改进车辆颜色和车牌识别系统的性能,具体包括以下几个方面:
首先,通过融合EfficientViT骨干网络,可以提高车辆颜色和车牌识别系统的准确性。EfficientViT通过引入注意力机制和多头自注意力机制,能够更好地捕捉图像中的关键特征,从而提高目标检测的准确性。
其次,融合EfficientViT骨干网络可以提高车辆颜色和车牌识别系统的鲁棒性。EfficientViT能够有效地处理复杂场景中的目标检测任务,对于小目标和密集目标的处理能力更强,从而提高系统在复杂场景下的识别效果。
最后,改进的YOLOV8算法可以实现实时的车辆颜色和车牌识别。由于YOLO算法的高效性,改进的YOLOV8算法可以在实时应用中实现较高的帧率,满足实时交通监控的需求。
综上所述,改进YOLOV8算法融合EfficientViT骨干网络的车辆颜色和车牌识别系统具有重要的研究意义和应用价值。通过提高系统的准确性和鲁棒性,可以更好地满足交通管理部门对于车辆识别系统的需求,提高交通管理的效率和安全性。同时,该研究还可以为其他领域的目标检测任务提供借鉴和参考,推动深度学习在实际应用中的发展。
2.图片演示

3.视频演示
【改进YOLOV8】融合EfficientViT骨干网络的车辆颜色车牌识别系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集TCDatasets。
labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.2 predict.py
class DetectionPredictor(BasePredictor):
def postprocess(self, preds, img, orig_imgs):
preds = ops.non_max_suppression(preds,
self.args.conf,
self.args.iou,
agnostic=self.args.agnostic_nms,
max_det=self.args.max_det,
classes=self.args.classes)
if not isinstance(orig_imgs, list):
orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)
results = []
for i, pred in enumerate(preds):
orig_img = orig_imgs[i]
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
img_path = self.batch[0][i]
results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))
return results
这个程序文件是一个名为predict.py的文件,它是一个用于预测基于检测模型的类DetectionPredictor的定义。它继承自BasePredictor类,并实现了postprocess方法来进行预测结果的后处理。
这个文件使用了Ultralytics YOLO库,该库是一个用于目标检测的工具包。它使用了一些辅助函数和类,如Results和ops。
在DetectionPredictor类中,有一个postprocess方法,用于对预测结果进行后处理。该方法接收预测结果preds、输入图像img和原始图像orig_imgs作为参数,并返回一个Results对象的列表。
在postprocess方法中,首先使用ops.non_max_suppression函数对预测结果进行非最大抑制处理,以过滤掉重叠的边界框。然后,根据输入图像的尺寸和原始图像的尺寸,对预测结果中的边界框进行缩放。最后,将原始图像、图像路径、类别名称和边界框信息封装成Results对象,并添加到结果列表中。
这个文件还提供了一个示例用法,展示了如何使用DetectionPredictor类进行预测。示例代码中,首先导入了一些必要的模块和资源文件,然后创建了一个DetectionPredictor对象,并调用predict_cli方法进行预测。
总之,这个程序文件是一个用于预测基于检测模型的类DetectionPredictor的定义,它使用了Ultralytics YOLO库,并提供了一个示例用法。
5.3 train.py
class DetectionTrainer(BaseTrainer):
def build_dataset(self, img_path, mode='train', batch=None):
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)
def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):
assert mode in ['train', 'val']
with torch_distributed_zero_first(rank):
dataset = self.build_dataset(dataset_path, mode, batch_size)
shuffle = mode == 'train'
if getattr(dataset, 'rect', False) and shuffle:
LOGGER.warning("WARNING ⚠️ 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")
shuffle = False
workers = 0
return build_dataloader(dataset, batch_size, workers, shuffle, rank)
def preprocess_batch(self, batch):
batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255
return batch
def set_model_attributes(self):
self.model.nc = self.data['nc']
self.model.names = self.data['names']
self.model.args = self.args
def get_model(self, cfg=None, weights=None, verbose=True):
model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
if weights:
model.load(weights)
return model
def get_validator(self):
self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'
return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
def label_loss_items(self, loss_items=None, prefix='train'):
keys = [f'{prefix}/{x}' for x in self.loss_names]
if loss_items is not None:
loss_items = [round(float(x), 5) for x in loss_items]
return dict(zip(keys, loss_items))
else:
return keys
def progress_string(self):
return ('\n' + '%11s' *
(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')
def plot_training_samples(self, batch, ni):
plot_images(images=batch['img'],
batch_idx=batch['batch_idx'],
cls=batch['cls'].squeeze(-1),
bboxes=batch['bboxes'],
paths=batch['im_file'],
fname=self.save_dir / f'train_batch{ni}.jpg',
on_plot=self.on_plot)
def plot_metrics(self):
plot_results(file=self.csv, on_plot=self.on_plot)
def plot_training_labels(self):
boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)
cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)
plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
这是一个用于训练基于检测模型的程序文件train.py。它使用了Ultralytics YOLO库进行目标检测模型的训练。
该程序文件包含了一个名为DetectionTrainer的类,它继承自BaseTrainer类,用于基于检测模型进行训练。该类具有以下功能:
- 构建YOLO数据集:根据传入的图像路径、模式(训练或验证)和批次大小,构建YOLO数据集。
- 获取数据加载器:根据传入的数据集路径、批次大小、排名和模式(训练或验证),构建并返回数据加载器。
- 预处理批次:对一批图像进行预处理,包括缩放和转换为浮点数。
- 设置模型属性:将类别数、类别名称和超参数等属性附加到模型上。
- 获取模型:返回一个YOLO检测模型。
- 获取验证器:返回一个用于YOLO模型验证的DetectionValidator。
- 标记损失项:返回一个带有标记的训练损失项的损失字典。
- 进度字符串:返回一个格式化的训练进度字符串,包括当前的epoch、GPU内存、损失、实例数和大小。
- 绘制训练样本:绘制带有注释的训练样本图像。
- 绘制指标:绘制来自CSV文件的指标。
- 绘制训练标签:创建一个带有标签的YOLO模型的训练图。
在程序的主函数中,首先定义了训练的参数(模型路径、数据集路径和训练轮数),然后创建了一个DetectionTrainer对象,并调用其train方法进行训练。
5.4 ui.py
class PlateRecognition:
def __init__(self):
# 初始化SVM分类器
self.clf = svm.SVC(kernel='linear', C=1.0, probability=True)
self.alphabet_mapping = {
"0": "0",
"1": "1",
"2": "2",
"3": "3",
"4": "4",
"5": "5",
"6": "6",
"7": "7",
"8": "8",
"9": "9",
"10": "A",
"11": "B",
"12": "C",
"13": "D",
"14": "E",
"15": "F",
"16": "G",
"17": "H",
"18": "I",
"19": "J",
"20": "K",
"21": "L",
"22": "M",
"23": "N",
"24": "O",
"25": "P",
"26": "Q",
"27": "R",
"28": "S",
"29": "T",
"30": "U",
"31": "V",
"32": "W",
"33": "X",
"34": "Y",
"35": "Z" }
def preprocess_image(self, image):
# 图像预处理
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 高斯滤波,去除噪声
blur = cv2.GaussianBlur(gray, (5, 5), 0)
# 二值化,将图像转换为黑白两色
thresh = cv2.adaptiveThreshold(blur, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY_INV, 11, 2)
return thresh
def locate_plate(self, image):
# 车牌定位
# 提取图像的边缘
canny = cv2.Canny(image, 100, 200)
# 膨胀操作,使边缘连成一个整体
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
dilate = cv2.dilate(canny, kernel, iterations=1)
# 查找所有轮廓
contours, hierarchy = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 找到面积最大的轮廓,即为车牌轮廓
max_area = 0
max_contour = None
for contour in contours:
area = cv2.contourArea(contour)
if area > max_area:
max_area = area
max_contour = contour
# 计算车牌的位置和大小
x, y, w, h = cv2.boundingRect(max_contour)
return x, y, w, h
def segment_chars(self, plate_image):
# 字符分割
# 把车牌的宽高扩大一些,便于字符的分割
plate_image = plate_image[:, :, np.newaxis]
plate_image = np.repeat(plate_image, 3, axis=2)
plate_image = cv2.resize(plate_image, (500, 114))
# 划分每个字符的位置
char_pos = [(50, 5, 90, 114), (142, 5, 182
......
这个程序文件是一个基于PyQt5的图形用户界面程序,用于车牌识别和目标检测。程序中使用了一些第三方库,如OpenCV、PyTorch等。
程序中定义了一个PlateRecognition类,用于车牌识别。该类包含了一些方法,如图像预处理、车牌定位、字符分割、特征提取等。还包含了训练SVM分类器的方法和加载数据集的方法。
程序中还定义了一些辅助函数,如创建车牌字典、检查车辆颜色和车牌是否匹配等。
程序中还定义了加载模型和运行模型的函数,用于目标检测。其中load_model函数用于加载目标检测模型,run函数用于运行目标检测模型。
程序中还定义了另一个加载模型和运行模型的函数,用于车辆颜色识别。
整个程序的主要功能是通过图形用户界面实现车牌识别和目标检测,并且可以检查车辆颜色和车牌是否匹配。
5.5 backbone\convnextv2.py
class LayerNorm(nn.Module):
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class GRN(nn.Module):
def __init__(self, dim):
super().__init__()
self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))
self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))
def forward(self, x):
Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)
Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)
return self.gamma * (x * Nx) + self.beta + x
class Block(nn.Module):
def __init__(self, dim, drop_path=0.):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim)
self.act = nn.GELU()
self.grn = GRN(4 * dim)
self.pwconv2 = nn.Linear(4 * dim, dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.grn(x)
x = self.pwconv2(x)
x = x.permute(0, 3, 1, 2)
x = input + self.drop_path(x)
return x
class ConvNeXtV2(nn.Module):
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768],
drop_path_rate=0., head_init_scale=1.
):
super().__init__()
self.depths = depths
self.downsample_layers = nn.ModuleList()
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList()
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6)
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward(self, x):
res = []
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
res.append(x)
return res
该程序文件是一个实现了ConvNeXt V2模型的PyTorch代码。ConvNeXt V2是一个用于图像分类任务的卷积神经网络模型。
该程序文件包含了以下几个类和函数:
-
LayerNorm类:实现了支持两种数据格式(channels_last和channels_first)的LayerNorm层。
-
GRN类:实现了全局响应归一化(Global Response Normalization)层。
-
Block类:实现了ConvNeXtV2模型的基本块。
-
ConvNeXtV2类:实现了ConvNeXt V2模型。
-
update_weight函数:用于更新模型的权重。
-
convnextv2_atto函数:创建一个ConvNeXtV2模型实例,用于处理输入图像的分辨率为640x640的情况。
-
convnextv2_femto函数:创建一个ConvNeXtV2模型实例,用于处理输入图像的分辨率为768x768的情况。
-
convnextv2_pico函数:创建一个ConvNeXtV2模型实例,用于处理输入图像的分辨率为1024x1024的情况。
-
convnextv2_nano函数:创建一个ConvNeXtV2模型实例,用于处理输入图像的分辨率为1280x1280的情况。
-
convnextv2_tiny函数:创建一个ConvNeXtV2模型实例,用于处理输入图像的分辨率为1536x1536的情况。
-
convnextv2_base函数:创建一个ConvNeXtV2模型实例,用于处理输入图像的分辨率为2048x2048的情况。
-
convnextv2_large函数:创建一个ConvNeXtV2模型实例,用于处理输入图像的分辨率为3072x3072的情况。
-
convnextv2_huge函数:创建一个ConvNeXtV2模型实例,用于处理输入图像的分辨率为5632x5632的情况。
以上是该程序文件的概述。该程序文件实现了ConvNeXt V2模型的各个组件,并提供了不同分辨率下的模型实例的创建函数。
5.6 backbone\CSwomTramsformer.py
class CSWinTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], mlp_ratio=4., qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_features = self.embed_dim = embed_dim
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
self.blocks = nn.ModuleList([
CSWinBlock(
dim=embed_dim, reso=img_size // patch_size, num_heads=num_heads[i], mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])], norm_layer=norm_layer,
last_stage=(i == len(depths) - 1))
for i in range(len(depths))])
self.norm = norm_layer(embed_dim)
self.feature_info = [dict(num_chs=embed_dim, reduction=0, module='head')]
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.head.weight, std=.02)
zeros_(self.head.bias)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x.mean(dim=1)) # global average pooling
return x
该程序文件是一个用于实现CSWin Transformer模型的Python文件。该模型是一个用于图像分类任务的Transformer模型。该文件定义了CSWin Transformer模型的各个组件,包括Mlp、LePEAttention、CSWinBlock和Merge_Block等。其中,Mlp是一个多层感知机模块,用于对输入进行线性变换和激活函数处理;LePEAttention是一个基于位置编码的注意力机制模块;CSWinBlock是CSWin Transformer的基本块,包含了多个LePEAttention模块和Mlp模块;Merge_Block是用于将CSWinBlock的输出进行降维的模块。该文件还定义了一些辅助函数,用于将图像转换为窗口形式和将窗口形式的图像转换为原始图像形式。
6.系统整体结构
下表总结了每个文件的功能:
| 文件名 | 功能 |
|---|---|
| export.py | 导出模型为ONNX、TFLite、TensorFlow Edge TPU等格式 |
| predict.py | 使用模型进行预测 |
| train.py | 训练模型 |
| ui.py | 图形用户界面,实现车牌识别和目标检测 |
| backbone\convnextv2.py | ConvNeXtV2模型的定义和创建函数 |
| backbone\CSwomTramsformer.py | CSWin Transformer模型的定义和创建函数 |
| backbone\EfficientFormerV2.py | EfficientFormerV2模型的定义和创建函数 |
| backbone\efficientViT.py | EfficientViT模型的定义和创建函数 |
| backbone\fasternet.py | FasterNet模型的定义和创建函数 |
| backbone\lsknet.py | LSKNet模型的定义和创建函数 |
| backbone\repvit.py | RepVIT模型的定义和创建函数 |
| backbone\revcol.py | RevCol模型的定义和创建函数 |
| backbone\SwinTransformer.py | Swin Transformer模型的定义和创建函数 |
| backbone\VanillaNet.py | VanillaNet模型的定义和创建函数 |
| extra_modules\afpn.py | AFPN模块的定义 |
| extra_modules\attention.py | 注意力机制模块的定义 |
| extra_modules\block.py | 模块的定义 |
| extra_modules\dynamic_snake_conv.py | 动态蛇形卷积模块的定义 |
| extra_modules\head.py | 模型头部的定义 |
| extra_modules\kernel_warehouse.py | 卷积核仓库的定义 |
| extra_modules\orepa.py | OREPA模块的定义 |
| extra_modules\rep_block.py | RepBlock模块的定义 |
| extra_modules\RFAConv.py | RFAConv模块的定义 |
| models\common.py | 通用模型函数和工具函数 |
| models\experimental.py | 实验性模型的定义和创建函数 |
| models\tf.py | TensorFlow模型的定义和创建函数 |
| models\yolo.py | YOLO模型的定义和创建函数 |
| ultralytics… | Ultralytics库的各个模块和功能 |
| utils… | 通用工具函数和辅助函数 |
以上是对每个文件功能的简要概述。由于文件数量较多,表格中只列出了部分文件,其他文件的功能可以参考文件名和路径进行推测。
7.YOLOv8模型
YOLOv8模型由Ultralytics团队在YOLOv5模型的基础上,吸收了近两年半来经过实际验证的各种改进,于2023年1月提出。与之前的一些YOLO 系列模型想类似,YOLOv8模型也有多种尺寸,下面以YOLOv8n为例,分析 YOLOv8模型的结构和改进点。YOLOv8模型网络结构如
输入图片的部分,由于发现Mosaic数据增强尽管这有助于提升模型的鲁棒性和泛化性,但是,在一定程度上,也会破坏数据的真实分布,使得模型学习到一些不好的信息。所以YOLOv8模型在训练中的最后10个epoch 停止使用Mosaic数据增强。
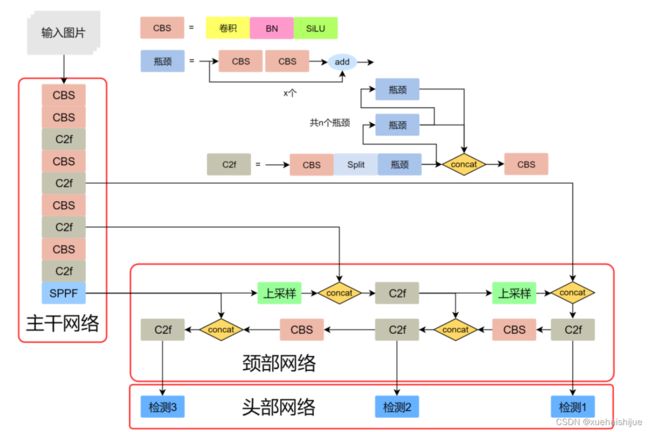
在网络结构上,首先主干网络的改变不大,主要是将C3模块替换为了C2f模块,该模块的结构在上图中已示出。C2f模块在C3模块的思路基础上,引入了YOLOv7中 ELAN的思路,引入了更多的跳层连接,这有助于该模块获得更丰富的梯度流信息,而且模型的轻量化得到了保证。依然保留了SPPF,效果不变的同时减少了该模块的执行时间。
在颈部网络中,也是将所有的C3模块更改为C2f模块,同时删除了两处上采样之前的卷积连接层。
在头部网络中,采用了YOLOX中使用的解耦头的思路,两条并行的分支分别提取类别和位置特征。由于分类任务更注重于分析特征图中提取到的特征与已输入图片的部分,由于发现 Mosaic数据增强尽管这有助于提升模型的鲁棒性和泛化性,但是,在一定程度上,也会破坏数据的真实分布,使得模型学习到一些不好的信息。所以YOLOv8模型在训练中的最后10个epoch停止使用Mosaic数据增强。
在网络结构上,首先主干网络的改变不大,主要是将C3模块替换为了C2f模块,该模块的结构在上图中已示出。C2f模块在C3模块的思路基础上,引入了YOLOv7中ELAN的思路,引入了更多的跳层连接,这有助于该模块获得更丰富的梯度流信息,而且模型的轻量化得到了保证。依然保留了SPPF,效果不变的同时减少了该模块的执行时间。
在颈部网络中,也是将所有的C3模块更改为C2f模块,同时删除了两处上采样之前的卷积连接层。
在头部网络中,采用了YOLOX中使用的解耦头的思路,两条并行的分支分别提取类别和位置特征。由于分类任务更注重于分析特征图中提取到的特征与已有类别中的哪一种更为相似,而定位任务更关注边界框与真值框的位置关系,并据此对边界框的坐标进行调整。侧重点的不同使得在使用两个检测头时收敛的速度和预测的精度有所提高。而且使用了无锚框结构,直接预测目标的中心,并使用TAL (Task Alignment Learning,任务对齐学习)来区分正负样本,引入了分类分数和IOU的高次幂乘积作为衡量任务对齐程度的指标,认为同时拥有好的定位和分类评价的在分类和定位损失函数中也引入了这项指标。
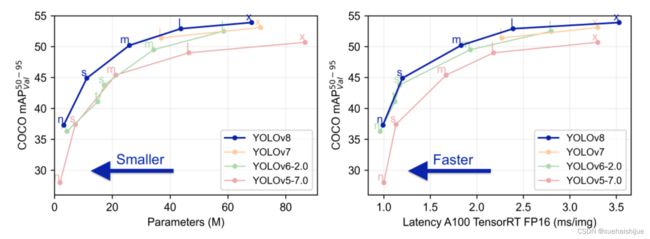
在模型的检测结果上,YOLOv8模型也取得了较好的成果,图为官方在coCO数据集上 YOLOv8模型的模型尺寸大小和检测的mAP50-95对比图。mAP50-95指的是IOU的值从50%取到95%,步长为5%,然后算在这些IOU下的mAP的均值。图的 a)图展示了YOLOv8在同尺寸下模型中参数没有较大增加的前提下取得了比其他模型更好的精度,图2-17的b)图展示了YOLOv8比其他YOLO系列模型在同尺寸时,推理速度更快且精度没有太大下降。
8.视觉transformer(ViT)简介
视觉transformer(ViT)最近在各种计算机视觉任务中证明了巨大的成功,并受到了相当多的关注。与卷积神经网络(CNNs)相比,ViT具有更强的全局信息捕获能力和远程交互能力,表现出优于CNNs的准确性,特别是在扩大训练数据大小和模型大小时[An image is worth 16x16 words: Transformers for image recognition at scale,Coatnet]。
尽管ViT在低分辨率和高计算领域取得了巨大成功,但在高分辨率和低计算场景下,ViT仍不如cnn。例如,下图(左)比较了COCO数据集上当前基于cnn和基于vit的一级检测器。基于vit的检测器(160G mac)和基于cnn的检测器(6G mac)之间的效率差距超过一个数量级。这阻碍了在边缘设备的实时高分辨率视觉应用程序上部署ViT。
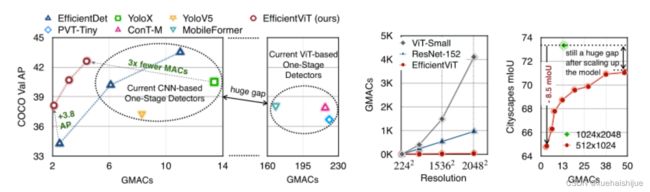
左图:现有的基于vit的一级检测器在实时目标检测方面仍然不如当前基于cnn的一级检测器,需要的计算量多出一个数量级。本文引入了第一个基于vit的实时对象检测器来弥补这一差距。在COCO上,efficientvit的AP比efficientdet高3.8,而mac较低。与YoloX相比,efficient ViT节省67.2%的计算成本,同时提供更高的AP。
中:随着输入分辨率的增加,计算成本呈二次增长,无法有效处理高分辨率的视觉应用。
右图:高分辨率对图像分割很重要。当输入分辨率从1024x2048降低到512x1024时,MobileNetV2的mIoU减少12% (8.5 mIoU)。在不提高分辨率的情况下,只提高模型尺寸是无法缩小性能差距的。
ViT的根本计算瓶颈是softmax注意模块,其计算成本随输入分辨率的增加呈二次增长。例如,如上图(中)所示,随着输入分辨率的增加,vit- small[Pytorch image models. https://github.com/rwightman/ pytorch-image-models]的计算成本迅速显著大于ResNet-152的计算成本。
解决这个问题的一个直接方法是降低输入分辨率。然而,高分辨率的视觉识别在许多现实世界的计算机视觉应用中是必不可少的,如自动驾驶,医疗图像处理等。当输入分辨率降低时,图像中的小物体和精细细节会消失,导致目标检测和语义分割性能显著下降。
上图(右)显示了在cityscape数据集上不同输入分辨率和宽度乘法器下MobileNetV2的性能。例如,将输入分辨率从1024x2048降低到512x1024会使cityscape的性能降低12% (8.5 mIoU)。即使是3.6倍高的mac,只放大模型尺寸而不增加分辨率也无法弥补这一性能损失。
除了降低分辨率外,另一种代表性的方法是限制softmax注意,方法是将其范围限制在固定大小的局部窗口内[Swin transformer,Swin transformer v2]或降低键/值张量的维数[Pyramid vision transformer,Segformer]。然而,它损害了ViT的非局部注意能力,降低了全局接受域(ViT最重要的优点),使得ViT与大内核cnn的区别更小[A convnet for the 2020s,Scaling up your kernels to 31x31: Revisiting large kernel design in cnns,Lite pose: Efficient architecture design for 2d human pose estimation]。
本文介绍了一个有效的ViT体系结构,以解决这些挑战。发现没有必要坚持softmax注意力。本文建议用线性注意[Transformers are rnns: Fast autoregressive transformers with linear attention]代替softmax注意。
线性注意的关键好处是,它保持了完整的n 2 n^2n 2
注意映射,就像softmax注意。同时,它利用矩阵乘法的联想特性,避免显式计算完整的注意映射,同时保持相同的功能。因此,它保持了softmax注意力的全局特征提取能力,且计算复杂度仅为线性。线性注意的另一个关键优点是它避免了softmax,这使得它在移动设备上更有效(下图左)。
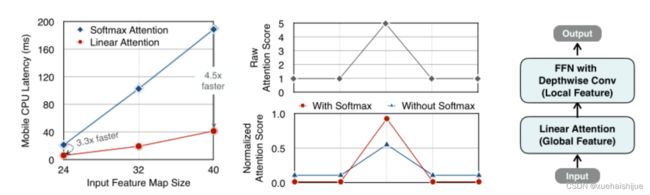
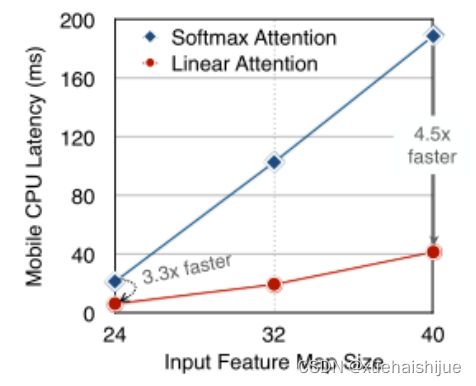
左图:线性注意比类似mac下的softmax注意快3.3-4.5倍,这是因为去掉了硬件效率不高的softmax功能。延迟是在Qualcomm Snapdragon 855 CPU和TensorFlow-Lite上测量的。本文增加线性注意的头部数量,以确保它具有与softmax注意相似的mac。
中:然而,如果没有softmax注意中使用的非线性注意评分归一化,线性注意无法有效集中其注意分布,削弱了其局部特征提取能力。后文提供了可视化。
右图:本文用深度卷积增强线性注意,以解决线性注意的局限性。深度卷积可以有效地捕捉局部特征,而线性注意可以专注于捕捉全局信息。增强的线性注意在保持线性注意的效率和简单性的同时,表现出在各种视觉任务上的强大表现(图4)。
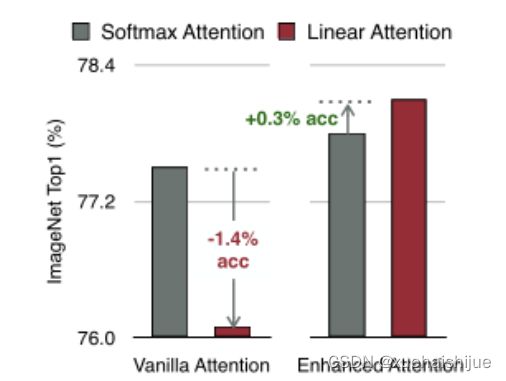
然而,直接应用线性注意也有缺点。以往的研究表明线性注意和softmax注意之间存在显著的性能差距(下图中间)。
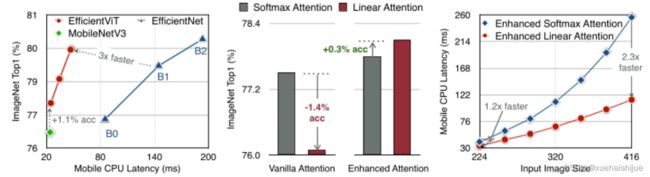
左:高通骁龙855上的精度和延迟权衡。效率vit比效率网快3倍,精度更高。中:ImageNet上softmax注意与线性注意的比较。在相同的计算条件下,本文观察到softmax注意与线性注意之间存在显著的精度差距。而深度卷积增强模型后,线性注意的精度有明显提高。
相比之下,softmax注意的精度变化不大。在相同MAC约束下,增强线性注意比增强软最大注意提高了0.3%的精度。右图:与增强的softmax注意相比,增强的线性注意硬件效率更高,随着分辨率的增加,延迟增长更慢。
深入研究线性注意和softmax注意的详细公式,一个关键的区别是线性注意缺乏非线性注意评分归一化方案。这使得线性注意无法有效地将注意力分布集中在局部模式产生的高注意分数上,从而削弱了其局部特征提取能力。
本文认为这是线性注意的主要限制,使其性能不如softmax注意。本文提出了一个简单而有效的解决方案来解决这一限制,同时保持线性注意在低复杂度和低硬件延迟方面的优势。具体来说,本文建议通过在每个FFN层中插入额外的深度卷积来增强线性注意。因此,本文不需要依赖线性注意进行局部特征提取,避免了线性注意在捕捉局部特征方面的不足,并利用了线性注意在捕捉全局特征方面的优势。
本文广泛评估了efficient vit在低计算预算下对各种视觉任务的有效性,包括COCO对象检测、城市景观语义分割和ImageNet分类。本文想要突出高效的主干设计,所以没有包括任何正交的附加技术(例如,知识蒸馏,神经架构搜索)。尽管如此,在COCO val2017上,efficientvit的AP比efficientdet - d1高2.4倍,同时节省27.9%的计算成本。在cityscape上,efficientvit提供了比SegFormer高2.5个mIoU,同时降低了69.6%的计算成本。在ImageNet上,efficientvit在584M mac上实现了79.7%的top1精度,优于efficientnet - b1的精度,同时节省了16.6%的计算成本。
与现有的以减少参数大小或mac为目标的移动ViT模型[Mobile-former,Mobilevit,NASVit]不同,本文的目标是减少移动设备上的延迟。本文的模型不涉及复杂的依赖或硬件低效操作。因此,本文减少的计算成本可以很容易地转化为移动设备上的延迟减少。
在高通骁龙855 CPU上,efficient vit运行速度比efficientnet快3倍,同时提供更高的ImageNet精度。本文的代码和预训练的模型将在出版后向公众发布。
9.Efficient Vision Transformer.
提高ViT的效率对于在资源受限的边缘平台上部署ViT至关重要,如手机、物联网设备等。尽管ViT在高计算区域提供了令人印象深刻的性能,但在针对低计算区域时,它通常不如以前高效的cnn[Efficientnet, mobilenetv3,Once for all: Train one network and specialize it for efficient deployment]。为了缩小差距,MobileViT建议结合CNN和ViT的长处,使用transformer将卷积中的局部处理替换为全局处理。MobileFormer提出了在MobileNet和Transformer之间建立双向桥以实现特征融合的并行化。NASViT提出利用神经架构搜索来搜索高效的ViT架构。
这些模型在ImageNet上提供了极具竞争力的准确性和效率的权衡。然而,它们并不适合高分辨率的视觉任务,因为它们仍然依赖于softmax注意力。
在本节中,本文首先回顾了自然语言处理中的线性注意,并讨论了它的优缺点。接下来,本文介绍了一个简单而有效的解决方案来克服线性注意的局限性。最后,给出了efficient vit的详细架构。
为可学习投影矩阵。Oi表示矩阵O的第i行。Sim(·,·)为相似度函数。
虽然softmax注意力在视觉和NLP方面非常成功,但它并不是唯一的选择。例如,线性注意提出了如下相似度函数:

其中,φ(·)为核函数。在本工作中,本文选择了ReLU作为内核函数,因为它对硬件来说是友好的。当Sim(Q, K) = φ(Q)φ(K)T时,式(1)可改写为:
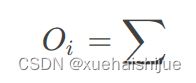
线性注意的一个关键优点是,它允许利用矩阵乘法的结合律,在不改变功能的情况下,将计算复杂度从二次型降低到线性型:

除了线性复杂度之外,线性注意的另一个关键优点是它不涉及注意模块中的softmax。Softmax在硬件上效率非常低。避免它可以显著减少延迟。例如,下图(左)显示了softmax注意和线性注意之间的延迟比较。在类似的mac上,线性注意力比移动设备上的softmax注意力要快得多。
EfficientViT
Enhancing Linear Attention with Depthwise Convolution
虽然线性注意在计算复杂度和硬件延迟方面优于softmax注意,但线性注意也有局限性。以往的研究[Luna: Linear unified nested attention,Random feature attention,Combiner: Full attention transformer with sparse computation cost,cosformer: Rethinking softmax in attention]表明,在NLP中线性注意和softmax注意之间通常存在显著的性能差距。对于视觉任务,之前的研究[Visual correspondence hallucination,Quadtree attention for vision transformers]也表明线性注意不如softmax注意。在本文的实验中,本文也有类似的观察结果(图中)。
本文对这一假设提出了质疑,认为线性注意的低劣性能主要是由于局部特征提取能力的丧失。如果没有在softmax注意中使用的非线性评分归一化,线性注意很难像softmax注意那样集中其注意分布。下图(中间)提供了这种差异的示例。

在相同的原始注意力得分下,使用softmax比不使用softmax更能集中注意力。因此,线性注意不能有效地聚焦于局部模式产生的高注意分数(下图),削弱了其局部特征提取能力。
注意图的可视化显示了线性注意的局限性。通过非线性注意归一化,softmax注意可以产生清晰的注意分布,如中间行所示。相比之下,线性注意的分布相对平滑,使得线性注意在捕捉局部细节方面的能力较弱,造成了显著的精度损失。本文通过深度卷积增强线性注意来解决这一限制,并有效提高了准确性。
介绍了一个简单而有效的解决方案来解决这个限制。本文的想法是用卷积增强线性注意,这在局部特征提取中是非常有效的。这样,本文就不需要依赖于线性注意来捕捉局部特征,而可以专注于全局特征提取。具体来说,为了保持线性注意的效率和简单性,本文建议在每个FFN层中插入一个深度卷积,这样计算开销很小,同时极大地提高了线性注意的局部特征提取能力。
Building Block
下图(右)展示了增强线性注意的详细架构,它包括一个线性注意层和一个FFN层,在FFN的中间插入深度卷积。

与之前的方法[Swin transformer,Coatnet]不同,本文在efficientvit中没有使用相对位置偏差。相对位置偏差虽然可以改善模型的性能,但它使模型容易受到分辨率变化[Segformer]的影响。多分辨率训练或新分辨率下的测试在检测和分割中很常见。去除相对位置偏差使高效率vit对输入分辨率更加灵活。
与之前低计算CNNs[Mobilenetv2,mobilenetv3]的设计不同,本文为下采样块添加了额外的下采样快捷方式。每个下采样快捷方式由一个平均池和一个1x1卷积组成。在本文的实验中,这些额外的下采样快捷方式可以稳定训练效率,提高性能。
Macro Architecture
下图说明了efficientvit的宏观体系结构。它由输入 stem 和4级组成。最近的研究[Coatnet,Levit,Early convolutions help transformers see better]表明在早期阶段使用卷积对ViT更好。本文遵循这个设计,在第三阶段开始使用增强的线性注意。
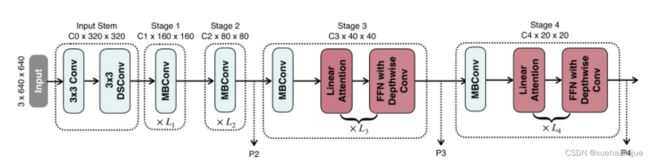
EfficientViT宏观架构。本文从第三阶段开始使用增强的线性注意。P2、P3和P4形成了一个金字塔特征图,用于检测和分割。P4用于分类。
为了突出高效的主干本身,本文对MBConv和FFN使用相同的扩展比e (e = 4)保持超参数简单,对所有深度卷积使用相同的内核大小k(除了输入stem),对所有层使用相同的激活函数(hard swish)。
P2、P3和P4表示阶段2、3和4的输出,形成了特征图的金字塔。本文按照惯例将P2、P3和P4送至检测头。本文使用Yolov8进行检测。为了分割,本文融合了P2和P4。融合特征被馈送到一个轻量级头,包括几个卷积层,遵循Fast-SCNN。为了分类,本文将P4输入到轻量级头部,与MobileNetV3相同。
10.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《【改进YOLOV8】融合EfficientViT骨干网络的车辆颜色车牌识别系统》
11.参考文献
[1]王静.基于深度卷积神经网络的垃圾分类研究[J].长江信息通信.2022,35(1).DOI:10.3969/j.issn.1673-1131.2022.01.023 .
[2]张伟,刘娜,江洋,等.基于YOLO神经网络的垃圾检测与分类[J].电子科技.2022,35(10).DOI:10.16180/j.cnki.issn1007-7820.2022.10.008 .
[3]周志霄,王宸,张秀峰,等.基于机器视觉与改进遗传算法的机械手分拣方法研究[J].制造技术与机床.2022,(2).DOI:10.19287/j.cnki.1005-2402.2022.02.004 .
[4]龙诗科,蒋奇航,包友南,等.基于Jetson Nano视觉应用平台设计[J].传感器与微系统.2022,41(9).DOI:10.13873/J.1000-9787(2022)09-0099-03 .
[5]梅志敏,陈艳,胡杭,等.机器人与机器视觉的垃圾分拣系统设计[J].机械设计与制造.2022,374(4).DOI:10.3969/j.issn.1001-3997.2022.04.062 .
[6]李庆,龚远强,张玮,等.用于智能垃圾分拣的注意力YOLOv4算法[J].计算机工程与应用.2022,58(11).DOI:10.3778/j.issn.1002-8331.2111-0098 .
[7]王慧,蒋朝根.基于深度学习的智能垃圾分拣车系统[J].电子技术应用.2022,48(1).DOI:10.16157/j.issn.0258-7998.211795 .
[8]朱炜义,王喜社,吴冠林.基于机器视觉的自动分类垃圾桶设计[J].产业与科技论坛.2022,21(7).DOI:10.3969/j.issn.1673-5641.2022.07.021 .
[9]陈艺海,黎莲花,谢昊璋,等.基于机器视觉的垃圾分拣机器人[J].仪器仪表与分析监测.2022,(1).DOI:10.3969/j.issn.1002-3720.2022.01.007 .
[10]王成军,韦志文,严晨.基于机器视觉技术的分拣机器人研究综述[J].科学技术与工程.2022,22(3).DOI:10.3969/j.issn.1671-1815.2022.03.004 .