Vivado 综合属性实用命令
引言
本文记录一些用于 Vivado 综合约束的实用命令,欢迎补充~
本文会适当结合一些特定设计进行解释,并结合相关工程进行具体的综合实现分析,不只是理论知识还有实际操作。
演示使用的Vivado 版本:2018.3
FPGA芯片型号:xc7a35tfgg484-2
本篇博文,建议在电脑端网页/pad上查看~
综合阶段
综合设置
综合设置的打开方式:

注意:凡是出现在综合设置区的设置均为 全局设置 ,即对设计工程中的所有模块都有效。
-flatten_hierarchy
解释说明
对于此设置项,Vivado给出 3 个可选项:full、none、rebuilt(默认)

那么此设置选项是什么意思呢?
flatten:打平、压平的意思
hierarchy:层次化的意思
连起来,此设置项表示将工程中的设计模块之间的层次打平(主要在LUT映射期间),是不同模块之间的层次化边界变得模糊,这有利于工具对我们写的RTL代码进行最大程度的优化。
对于此设置项的不同取值,在这里做简单解释:
取值 |
含义 |
full |
将原始设计打平,只保留顶层设计,执行边界优化 |
none |
完全保留原始设计的层次,不执行边界优化 |
rebuilt |
将原始设计打平,执行边界优化,将网表文件按照原始设计层次显示,故与原始设计层次相同 |
如果希望某个模块的层次优化策略与 -flatten_hierarchy中选择的值不同,可以使用综合属性中的 KEEP_HIERARCHY ,其仅可在RTL代码中使用,优先级高于 -flatten_hierarchy 中的设置值。KEEP_HIERARCHY 指保留层级结构,不被优化。
KEEP_HIERARCHY 的 使用方法(Verilog HDL ,示例):
(* KEEP_HIERARCHY = "yes" *) module UART_TX_MDL( );
对于-flatten_hierarchy ,通常保持默认值 rebuilt 即可。使用 rebuilt 的益处在于,使用内嵌的逻辑分析仪(ILA时),可以快速地根据层级找到待观测信号。
KEEP_HIERARCHY 的优先级高于 -flatten_hierarchy ,可根据需要对某些层次设置此属性。
设计实践
此处我想用一个运算模块来试验-flatten_hierarchy 在不同设置特性下综合的结果,同时也验证 KEEP_HIERARCHY 的设置功能。
顶层模块实现:Y = (A + B) * C - D;其中操作数 A B C D 均为有符号 16位数据;
设计源码
加法模块
// | ============================== 有符号加法运算模块 ==============================
// | 作者:Xu Y. B.(CSDN 用户名:在路上,正出发)
// | 时间:2023-01-05
// | 功能:实现同位宽的两个有符号数相加
// | ================================================================================
`timescale 1ns / 1ps
module SIGNED_ADD_MDL #(
// 模块参数声明
parameter P_OPR_DATA_WIDTH = 32'd16
)(
// 输入输出端口声明
input I_OPR_CLK,
input I_OPR_RSTN,
input [P_OPR_DATA_WIDTH-1:0] I_OPR_DATA_A,
input [P_OPR_DATA_WIDTH-1:0] I_OPR_DATA_B,
input I_OPR_DATA_VAL,
output reg [P_OPR_DATA_WIDTH:0] O_ADD_RES,
output reg O_ADD_RES_VAL
);
always @ (posedge I_OPR_CLK)
begin
if(~I_OPR_RSTN)
begin
O_ADD_RES <= {(P_OPR_DATA_WIDTH+1){1'b0}};
O_ADD_RES_VAL <= 1'b0;
end
else
begin
if(I_OPR_DATA_VAL)
begin
O_ADD_RES <= {I_OPR_DATA_A[P_OPR_DATA_WIDTH-1],I_OPR_DATA_A} + {I_OPR_DATA_B[P_OPR_DATA_WIDTH-1],I_OPR_DATA_B};
O_ADD_RES_VAL <= I_OPR_DATA_VAL;
end
else
begin
O_ADD_RES <= {(P_OPR_DATA_WIDTH+1){1'b0}};
O_ADD_RES_VAL <= 1'b0;
end
end
end
endmodule
减法模块
// | ============================== 有符号减法运算模块 ==============================
// | 作者:Xu Y. B.(CSDN 用户名:在路上,正出发)
// | 时间:2023-01-05
// | 功能:实现同位宽的两个有符号数相减
// | ================================================================================
`timescale 1ns / 1ps
module SIGNED_SUB_MDL #(
// 模块参数声明
parameter P_OPR_DATA_WIDTH = 32'd16
)(
// 输入输出端口声明
input I_OPR_CLK,
input I_OPR_RSTN,
input [P_OPR_DATA_WIDTH-1:0] I_OPR_DATA_A,
input [P_OPR_DATA_WIDTH-1:0] I_OPR_DATA_B,
input I_OPR_DATA_VAL,
output reg [P_OPR_DATA_WIDTH:0] O_SUB_RES,
output reg O_SUB_RES_VAL
);
always @ (posedge I_OPR_CLK)
begin
if(~I_OPR_RSTN)
begin
O_SUB_RES <= {(P_OPR_DATA_WIDTH+1){1'b0}};
O_SUB_RES_VAL <= 1'b0;
end
else
begin
if(I_OPR_DATA_VAL)
begin
O_SUB_RES <= {I_OPR_DATA_A[P_OPR_DATA_WIDTH-1],I_OPR_DATA_A} - {I_OPR_DATA_B[P_OPR_DATA_WIDTH-1],I_OPR_DATA_B};
O_SUB_RES_VAL <= I_OPR_DATA_VAL;
end
else
begin
O_SUB_RES <= {(P_OPR_DATA_WIDTH+1){1'b0}};
O_SUB_RES_VAL <= 1'b0;
end
end
end
endmodule
乘法模块
// | ============================== 有符号乘法运算模块 ==============================
// | 作者:Xu Y. B.(CSDN 用户名:在路上,正出发)
// | 时间:2023-01-05
// | 功能:实现不同位宽的两个有符号数相乘
// | ================================================================================
`timescale 1ns / 1ps
module SIGNED_MULT_MDL #(
// 模块参数声明
parameter P_OPR_DATA_WIDTH_A = 32'd16,
parameter P_OPR_DATA_WIDTH_B = 32'd16
)(
// 输入输出端口声明
input I_OPR_CLK,
input I_OPR_RSTN,
input [P_OPR_DATA_WIDTH_A-1:0] I_OPR_DATA_A,
input [P_OPR_DATA_WIDTH_B-1:0] I_OPR_DATA_B,
input I_OPR_DATA_VAL,
output reg [P_OPR_DATA_WIDTH_A+P_OPR_DATA_WIDTH_B-1:0] O_MULT_RES,
output reg O_MULT_RES_VAL
);
always @ (posedge I_OPR_CLK)
begin
if(~I_OPR_RSTN)
begin
O_MULT_RES <= {(P_OPR_DATA_WIDTH_A+P_OPR_DATA_WIDTH_B){1'b0}};
O_MULT_RES_VAL <= 1'b0;
end
else
begin
if(I_OPR_DATA_VAL)
begin
O_MULT_RES <= {{(P_OPR_DATA_WIDTH_B){I_OPR_DATA_A[P_OPR_DATA_WIDTH_A-1]}},I_OPR_DATA_A} * {{(P_OPR_DATA_WIDTH_A){I_OPR_DATA_B[P_OPR_DATA_WIDTH_B-1]}},I_OPR_DATA_B};
O_MULT_RES_VAL <= I_OPR_DATA_VAL;
end
else
begin
O_MULT_RES <= {(P_OPR_DATA_WIDTH_A+P_OPR_DATA_WIDTH_B){1'b0}};
O_MULT_RES_VAL <= 1'b0;
end
end
end
endmodule
顶层模块
// | ============================== 有符号运算测试顶层模块 ==============================
// | 作者:Xu Y. B.(CSDN 用户名:在路上,正出发)
// | 时间:2023-01-05
// | 功能:实现有符号数混合运算 (A+B)*C-D
// | ====================================================================================
`timescale 1ns / 1ps
module SIGNED_CAL_TOP_MDL(
// 输入输出端口声明
input I_OPR_CLK,
input I_OPR_RSTN,
input [15:0] I_OPR_DATA_A,
input I_OPR_VAL_A,
input [15:0] I_OPR_DATA_B,
input I_OPR_VAL_B,
input [15:0] I_OPR_DATA_C,
input I_OPR_VAL_C,
input [15:0] I_OPR_DATA_D,
input I_OPR_VAL_D,
output [33:0] O_OPR_RES,
output O_OPR_RES_VAL
);
wire [16:0] W_ADD_RES;
wire W_ADD_RES_VAL;
reg [15:0] R_I_OPR_DATA_C;
reg R_I_OPR_VAL_C;
wire [32:0] W_MULT_RES;
wire W_MULT_RES_VAL;
reg [15:0] R_I_OPR_DATA_D[1:0];
reg [1:0] R_I_OPR_VAL_D;
always @ (posedge I_OPR_CLK)
begin
if(~I_OPR_RSTN)
begin
R_I_OPR_DATA_C <= 16'd0;
R_I_OPR_VAL_C <= 1'b0;
R_I_OPR_DATA_D[0] <= 16'd0;
R_I_OPR_DATA_D[1] <= 16'd0;
R_I_OPR_VAL_D <= 2'b0;
end
else
begin
R_I_OPR_DATA_C <= I_OPR_DATA_C;
R_I_OPR_VAL_C <= I_OPR_VAL_C;
R_I_OPR_DATA_D[0] <= I_OPR_DATA_D;
R_I_OPR_DATA_D[1] <= R_I_OPR_DATA_D[0];
R_I_OPR_VAL_D <= {R_I_OPR_VAL_D[0],I_OPR_VAL_D};
end
end
SIGNED_ADD_MDL #(
.P_OPR_DATA_WIDTH(32'd16)
) INST_SIGNED_ADD_MDL (
.I_OPR_CLK (I_OPR_CLK),
.I_OPR_RSTN (I_OPR_RSTN),
.I_OPR_DATA_A (I_OPR_DATA_A),
.I_OPR_DATA_B (I_OPR_DATA_B),
.I_OPR_DATA_VAL (I_OPR_VAL_A & I_OPR_VAL_B),
.O_ADD_RES (W_ADD_RES),
.O_ADD_RES_VAL (W_ADD_RES_VAL)
);
SIGNED_SUB_MDL #(
.P_OPR_DATA_WIDTH(32'd33)
) INST_SIGNED_SUB_MDL (
.I_OPR_CLK (I_OPR_CLK),
.I_OPR_RSTN (I_OPR_RSTN),
.I_OPR_DATA_A (W_MULT_RES),
.I_OPR_DATA_B ({{17{R_I_OPR_DATA_D[1][15]}},R_I_OPR_DATA_D[1]}),
.I_OPR_DATA_VAL (R_I_OPR_VAL_D[1] & W_MULT_RES_VAL),
.O_SUB_RES (O_OPR_RES),
.O_SUB_RES_VAL (O_OPR_RES_VAL)
);
SIGNED_MULT_MDL #(
.P_OPR_DATA_WIDTH_A(32'd17),
.P_OPR_DATA_WIDTH_B(32'd16)
) INST_SIGNED_MULT_MDL (
.I_OPR_CLK (I_OPR_CLK),
.I_OPR_RSTN (I_OPR_RSTN),
.I_OPR_DATA_A (W_ADD_RES),
.I_OPR_DATA_B (R_I_OPR_DATA_C),
.I_OPR_DATA_VAL (W_ADD_RES_VAL & R_I_OPR_VAL_C),
.O_MULT_RES (W_MULT_RES),
.O_MULT_RES_VAL (W_MULT_RES_VAL)
);
endmodule
仿真文件
编写测试文件:
`timescale 1ns / 1ps
module TB_SIGNED_CAL_TOP_MDL();
// 输入输出端口声明
reg I_OPR_CLK;
reg I_OPR_RSTN;
reg [15:0] I_OPR_DATA_A;
reg I_OPR_VAL_A;
reg [15:0] I_OPR_DATA_B;
reg I_OPR_VAL_B;
reg [15:0] I_OPR_DATA_C;
reg I_OPR_VAL_C;
reg [15:0] I_OPR_DATA_D;
reg I_OPR_VAL_D;
wire [33:0] O_OPR_RES;
wire O_OPR_RES_VAL;
initial I_OPR_CLK = 1'b0;
always #10 I_OPR_CLK = ~I_OPR_CLK;
initial
begin
I_OPR_RSTN = 1'b0;
I_OPR_DATA_A = 16'd0;
I_OPR_VAL_A = 1'b0;
I_OPR_DATA_B = 16'd0;
I_OPR_VAL_B = 1'b0;
I_OPR_DATA_C = 16'd0;
I_OPR_VAL_C = 1'b0;
I_OPR_DATA_D = 16'd0;
I_OPR_VAL_D = 1'b0;
#204;
I_OPR_RSTN = 1;
#100;
TASK_SIM(16'd100,-16'd120,-16'd200,16'd390);
TASK_SIM(16'd10,-16'd1200,-16'd200,16'd390);
TASK_SIM(16'd50,-16'd120,-16'd200,16'd3900);
TASK_SIM(16'd1000,-16'd12,-16'd200,16'd390);
TASK_SIM(16'd120,-16'd120,-16'd210,16'd390);
TASK_SIM(16'd180,-16'd120,-16'd250,16'd390);
$finish;
end
SIGNED_CAL_TOP_MDL INST_SIGNED_CAL_TOP_MDL
(
.I_OPR_CLK (I_OPR_CLK),
.I_OPR_RSTN (I_OPR_RSTN),
.I_OPR_DATA_A (I_OPR_DATA_A),
.I_OPR_VAL_A (I_OPR_VAL_A),
.I_OPR_DATA_B (I_OPR_DATA_B),
.I_OPR_VAL_B (I_OPR_VAL_B),
.I_OPR_DATA_C (I_OPR_DATA_C),
.I_OPR_VAL_C (I_OPR_VAL_C),
.I_OPR_DATA_D (I_OPR_DATA_D),
.I_OPR_VAL_D (I_OPR_VAL_D),
.O_OPR_RES (O_OPR_RES),
.O_OPR_RES_VAL (O_OPR_RES_VAL)
);
task TASK_SIM;
input [15:0] I_A;
input [15:0] I_B;
input [15:0] I_C;
input [15:0] I_D;
begin
@(posedge I_OPR_CLK)
I_OPR_DATA_A <= I_A;
I_OPR_VAL_A <= 1'b1;
I_OPR_DATA_B <= I_B;
I_OPR_VAL_B <= 1'b1;
I_OPR_DATA_C <= I_C;
I_OPR_VAL_C <= 1'b1;
I_OPR_DATA_D <= I_D;
I_OPR_VAL_D <= 1'b1;
@(posedge I_OPR_CLK)
I_OPR_DATA_A <= 16'd0;
I_OPR_VAL_A <= 1'b0;
I_OPR_DATA_B <= 16'd0;
I_OPR_VAL_B <= 1'b0;
I_OPR_DATA_C <= 16'd0;
I_OPR_VAL_C <= 1'b0;
I_OPR_DATA_D <= 16'd0;
I_OPR_VAL_D <= 1'b0;
#120;
end
endtask
endmodule
仿真结果
仿真波形:

综合分析
仿真发现功能准确后,对RTL代码进行综合:
对于-flatten_hierarchy执行不同的综合策略选项:
如何切换不同策略?

点击 Apply 以后会跳出如下对话框:
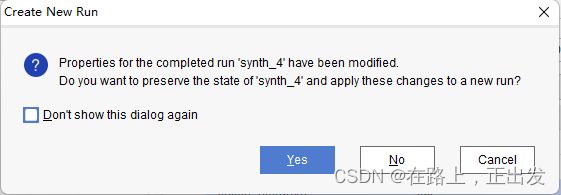
我的建议是选择 No,否则每切换一次综合策略就会生成一个新的综合文件夹,导致垃圾文件堆积。
rebuilt

none

full
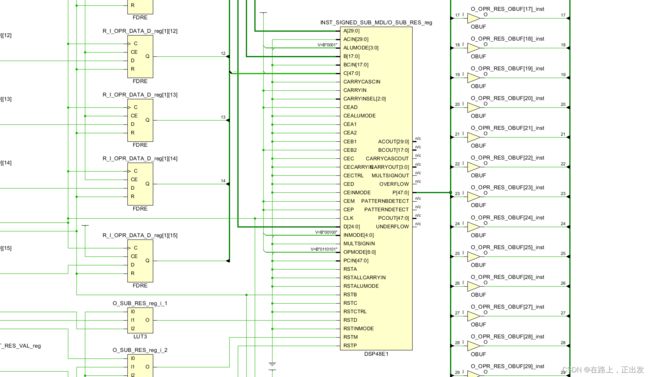
通过上面对同一RTL源代码,进行不同策略的综合分析,当 -flatten_hierarchy的综合策略为full时,会将原本模块与模块之间的界限打破,从综合的结果来看,仅剩一个DSP48E1。而其余两个均在网表中保留了原本RTL设计中的模块层次界限。
(*KEEP_HIERARCHY = "yes"*)
在 -flatten_hierarchy的综合策略为full的情况下,使用综合属性 (*KEEP_HIERARCHY = "yes"*) 对加法运算模块进行约束,综合后的网表结果:

可以看到加法模块的层级仍然保留,其他模块的层级不见了,乘法和减法用DSP48E1代替了。
总结
对于-flatten_hierarchy ,通常保持默认值 rebuilt 即可。使用 rebuilt 的益处在于,使用内嵌的逻辑分析仪(ILA时),可以快速地根据层级找到待观测信号。
KEEP_HIERARCHY 的优先级高于 -flatten_hierarchy ,可根据需要对某些层次设置此属性。对于此属性在 Verilog HDL 中的使用再补充两点:
(*KEEP_HIERARCHY = "yes"*) 可以约束在 设计文件 中,类似下图这种,当约束在设计文件中时,该模块在任何一个地方例化,都会保持原本的层级结构。
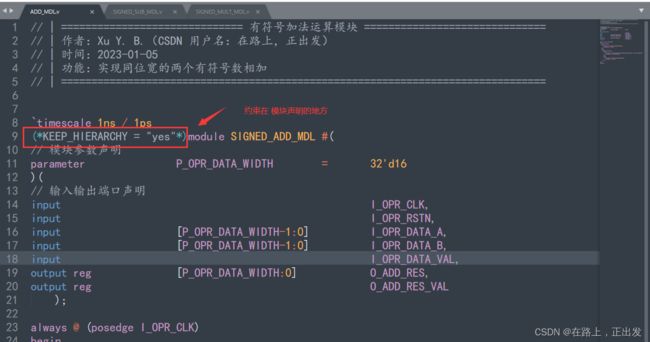
(*KEEP_HIERARCHY = "yes"*) 也可以约束在 模块例化 时,类似下图这种,当约束在模块例化处时,仅对约束的例化模块有效。

上述代码的综合结果:

-control_set_opt_threshold
解释说明
对于此设置项,Vivado给出18个可选项:0~16,auto(默认)
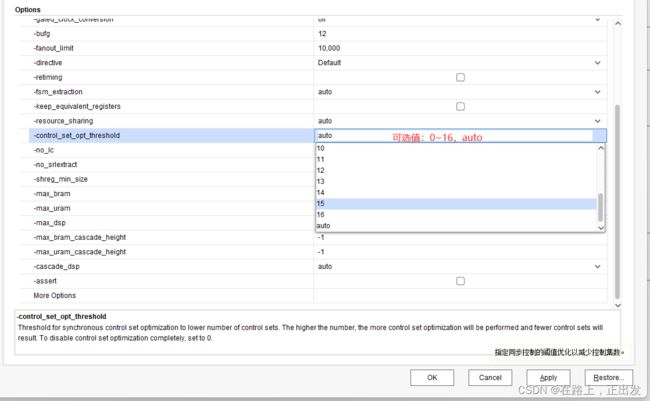
官方的说法是:

Threshold for synchronous control set optimization to lower number of control sets .The higher the number, the more control set optimization will be performed and fewer control sets will result.To disable control set optimization completely, set to 0.
百度翻译的结果:
用于同步控制集优化的阈值,以减少控制集的数量。数量越高,将执行的控制集优化越多,产生的控制集越少。若要完全禁用控制集优化,请设置为0。
介绍这个概念之前先说一下触发器控制集的概念,触发器的控制集由 时钟信号、复位/置位信号 、使能信号 。通常只有 {clk , rst/set , ce}均相同的触发器才能被放在同一个SLICE中。对于同步复位、同步置位、同步使能信号,Vivado 根据 -control_set_opt_threshold 的设置进行优化,目的在于减少控制集个数。
-control_set_opt_threshold 的值为控制信号(非时钟)的扇出个数,综合工具会对小于此值的同步信号进行优化。此综合选项的数值越大,被优化的寄存器数量越多,被占用的 LUT也越多。若此值置为零,则不进行任何优化。通常情况下,此值保持默认选项(auto)即可。
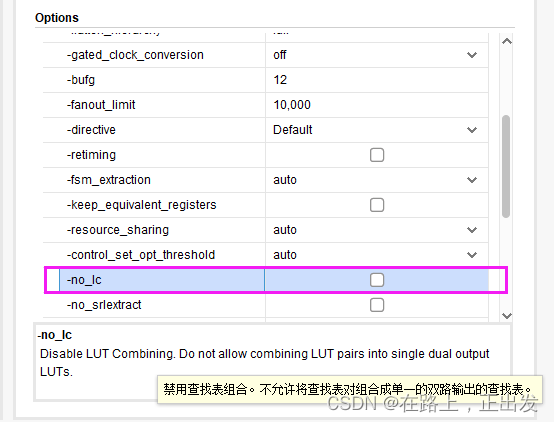
-no_lc
解释说明
对于此设置项,可以选择使能(打上对勾),也可以选择不使能。使能时表示,允许LUT组合,即允许综合工具将LUT对组合成单一的双路输出的查找表。
允许LUT整合的优点:减少LUT的使用;缺点:导致布线拥挤。
资源不紧张的前提下不建议使用。
-keep_equivalent_registers
解释说明
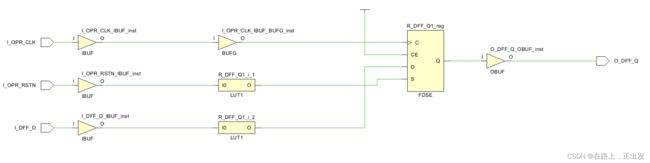
Vivado中,此综合设置的位置如下图所示。如果勾选此设置,Vivado综合工具对设计进行综合时,会保留所有的同源寄存器不被优化。否则,会优化掉设计中包含的全部同源寄存器。
何谓同源寄存器?即共享时钟、数据端口的寄存器。
一般来说,此综合属性不予使能,对于那些特意构造的同源寄存器,可以用KEEP综合约束属性对其进行约束,使其不被综合工具优化。

设计实践
此处设计一个案例,构造一组同源寄存器:
module TEST_CTRL_SET(
// 输入输出端口
input I_OPR_CLK,
input I_OPR_RSTN,
input I_DFF_D,
output O_DFF_Q
);
reg R_DFF_Q1;
// (*KEEP = "TRUE"*)
reg R_DFF_Q2;
assign O_DFF_Q = R_DFF_Q1;
always @ (posedge I_OPR_CLK)
begin
if(~I_OPR_RSTN)
begin
R_DFF_Q2 <= 1'b1;
end
else
begin
R_DFF_Q2 <= ~I_DFF_D;
end
end
always @ (posedge I_OPR_CLK)
begin
if(~I_OPR_RSTN)
begin
R_DFF_Q1 <= 1'b1;
end
else
begin
R_DFF_Q1 <= ~I_DFF_D;
end
end
endmodule
保持该综合设置选项不使能,综合结果:
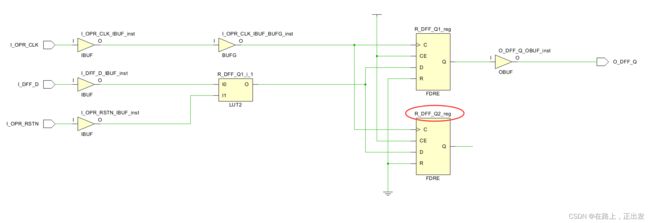
保持该综合设置选项不使能,使用 KEEP 综合属性:

此处 TRUE 大小写均可以。
综合结果:
总结
一般来说,此综合属性不予使能,对于那些特意构造的同源寄存器,可以用KEEP综合约束属性对其进行约束,使其不被综合工具优化。
-resource_sharing
解释说明
Vivado 给出的可选项:auto(默认)、on、off

综合设置 -resource_sharing 的作用是 对算数运算(加法、乘法)实现资源共享。
设计实践
// | ============================ -resource_sharing 综合策略测试模块 ============================
// | 作者:Xu Y. B.(CSDN 用户名:在路上,正出发)
// | 时间:2023-01-09
// | 功能:
// | ============================================================================================
`timescale 1ns / 1ps
module SRC_SHARE(
input I_OPR_SEL,
input [3:0] I_OPR_DATA_A,
input [3:0] I_OPR_DATA_B,
output [4:0] O_OPR_RES
);
assign O_OPR_RES = I_OPR_SEL ? I_OPR_DATA_A +I_OPR_DATA_B
:I_OPR_DATA_A -I_OPR_DATA_B;
endmodule
-resource_sharing 设置为 on,综合结果:
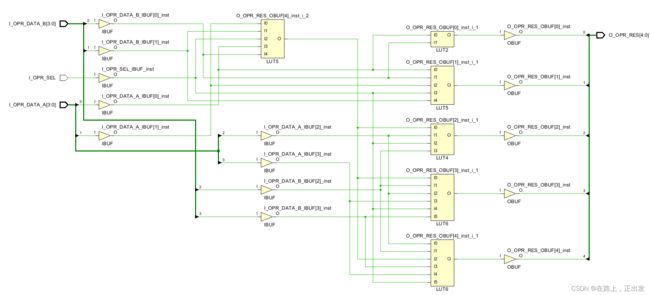
LUT资源消耗:

-resource_sharing 设置为 off,综合结果:
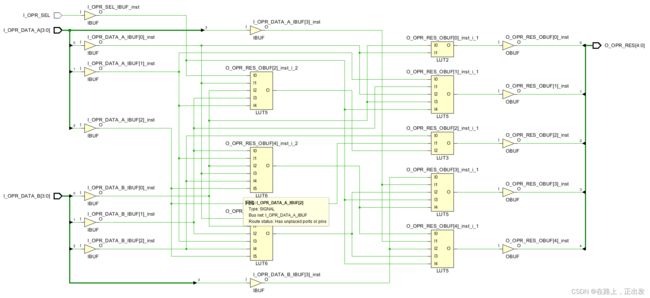
LUT资源消耗:

总结
此设置项一般保持auto即可。
-gated_clock_conversion
解释说明
Vovado中 -gated_clock_conversion 的设置:
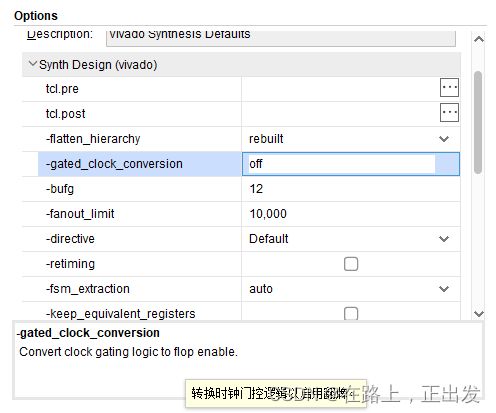
-gated_clock_conversion 设置项用于管理门控时钟,将门控时钟转化为寄存器使能。门控时钟由RTL逻辑代码设计,不是专用时钟资源产生的输出。门控时钟可能会给设计带来较大影响:时钟毛刺、时钟歪斜更严重。另外,Vivado综合工具不会对门控时钟插入全局缓冲器(BUFG)。-gated_clock_conversion 设置项 使能时,可将门控时钟信号变为使能信号。
设计实践
// | ============================ -gated_clock_conversion 综合策略测试模块 ============================
// | 作者:Xu Y. B.(CSDN 用户名:在路上,正出发)
// | 时间:2023-01-09
// | 功能:
// | ==================================================================================================
`timescale 1ns / 1ps
module GATE_CLK(
input I_CLK,
input I_CLK_EN,
input I_RSTN,
output reg [3:0] O_CNT
);
wire W_GATE_CLK = I_CLK & I_CLK_EN;
always @ (posedge W_GATE_CLK)
begin
if(~I_RSTN)
O_CNT <= 4'd0;
else
O_CNT <= O_CNT + 1;
end
endmodule
XDC文件里面创建时钟:
create_clock -period 10 [get_ports I_CLK]设置项关闭时,综合结果:
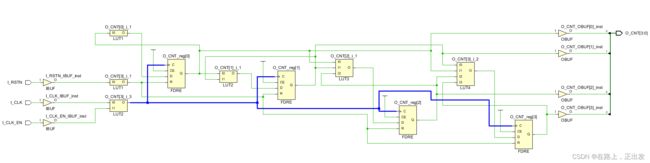
设置项为 auto 时,综合结果:

此时,不仅插入了BUFG,而且移除了时钟门控。
总结
设计存在时钟门控时,将此设置项置为 auto 让综合工具自行推断并转化。
如果将设置项置为 on ,在RTL代码中需要用 GATED_CLOCK 综合属性设为 TRUE 以声明门控时钟(必须在输入端口声明,否则无效),否则综合工具不予处理。
如此处举例的代码,只将 -gated_clock_conversion 设置为 on ,而不在代码里声明门控时钟,综合结果为:
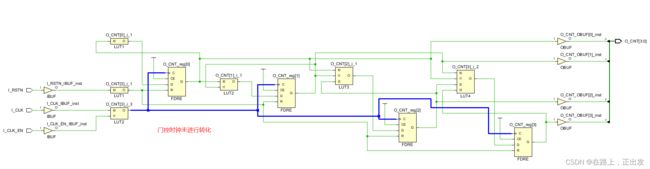
如下的RTL代码:
// | ============================ -gated_clock_conversion 综合策略测试模块 ============================
// | 作者:Xu Y. B.(CSDN 用户名:在路上,正出发)
// | 时间:2023-01-09
// | 功能:
// | ==================================================================================================
`timescale 1ns / 1ps
module GATE_CLK(
(* GATED_CLOCK = "TRUE" *)
input I_CLK,
input I_CLK_EN,
input I_RSTN,
output reg [3:0] O_CNT
);
wire W_GATE_CLK ;
assign W_GATE_CLK = I_CLK & I_CLK_EN;
always @ (posedge W_GATE_CLK)
begin
if(~I_RSTN)
O_CNT <= 4'd0;
else
O_CNT <= O_CNT + 1;
end
endmodule-gated_clock_conversion 设置为 on 的综合结果:

-fanout_limit
解释说明
Vivado中的该综合设置是全局设置,用于设置信号最大的扇出系数,默认值为10000。此设置项对设计中的控制信号,如置位/复位/使能信号无效。

总结
1、对于此设置项,一般保持默认选择就可以。
2、此设置项对设计中的控制信号,如置位/复位/使能信号无效。
3、对于明确需要降低扇出系数的信号,可以使用 MAX_FANOUT 综合属性对信号进行约束。对某一信号或寄存器单独设置MAX_FANOUT属性会忽视-fanout_limit的限制
MAX_FANOUT 综合属性的设置方式(Verilog 语言):
(* MAX_FANOUT = 50 *) reg R_EN;
-shreg_min_size、-no_srlextract
解释说明
-no_srlextract 如果勾选则表示:禁止移位寄存器提取,使其作为简单寄存器实现。
-shreg_min_size 设置了被映射为SRL的移位寄存器链的最小长度。默认值:3

Xilinx的FPGA中,LUT可以配置为移位寄存器。有两种方式:一是通过 SRL16E或SRLC32E实现;二是通过RTL代码实现。对于第一种方式,SRL16E和SRLC32E主要区别在于二者深度不同,且SRLC32E提供了级联端口 Q31。
当移位寄存器长度小于等于 -shreg_min_size 时,最终实现的方式为触发器级联;
当深度大于 -shreg_min_size 时,采用 FF+LUT+FF的实现形式。
-no_srlextract 用于阻止将移位寄存器映射为 LUT,优先级高于 -shreg_min_size 。
要想用LUT实现移位寄存器,RTL设计时不能有移位寄存器复位功能,否则综合工具不会将移位寄存器映射为FF+LUT+FF的结构。此处后再后面的实践环节验证。
设计实践
有复位端口的移位寄存器模块,无论 -shreg_min_size 如何配置(-no_srlextract 不使能),综合工具均将移位寄存器映射为全触发器:
// | ========================================================
// | 作者:Xu Y. B.(CSDN 用户名:在路上,正出发)
// | 时间:2023-01-09
// | 功能:左移移位寄存器
// | ========================================================
`timescale 1ns / 1ps
module SHIFT #(
parameter P_SHIFT_LENGTH = 32'd16
)(
input I_CLK,
input I_RSTN,
input I_EN,
input I_SHIFT,
output O_SHIFT
);
reg [P_SHIFT_LENGTH-1:0] R_SHIFT;
always @ (posedge I_CLK)
begin
if(~I_RSTN)
begin
R_SHIFT <= {(P_SHIFT_LENGTH){1'b0}};
end
else
// if(I_EN)
begin
R_SHIFT <= {R_SHIFT[0+:P_SHIFT_LENGTH-1],I_SHIFT};
end
end
assign O_SHIFT = R_SHIFT[P_SHIFT_LENGTH-1];
endmodule此时,-shreg_min_size 配置为 10。-no_srlextract 不使能,综合结果:

综合结果全为寄存器。
将代码做如下更改,取消复位:
// | ========================================================
// | 作者:Xu Y. B.(CSDN 用户名:在路上,正出发)
// | 时间:2023-01-09
// | 功能:左移移位寄存器
// | ========================================================
`timescale 1ns / 1ps
module SHIFT #(
parameter P_SHIFT_LENGTH = 32'd16
)(
input I_CLK,
input I_RSTN,
input I_EN,
input I_SHIFT,
output O_SHIFT
);
reg [P_SHIFT_LENGTH-1:0] R_SHIFT;
always @ (posedge I_CLK)
begin
// if(~I_RSTN)
// begin
// R_SHIFT <= {(P_SHIFT_LENGTH){1'b0}};
// end
// else
if(I_EN)
begin
R_SHIFT <= {R_SHIFT[0+:P_SHIFT_LENGTH-1],I_SHIFT};
end
end
assign O_SHIFT = R_SHIFT[P_SHIFT_LENGTH-1];
endmodule此时,-shreg_min_size 配置为 10。-no_srlextract 不使能,综合结果:
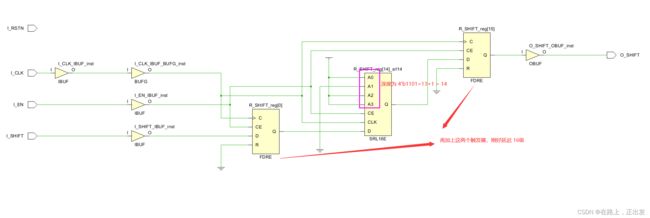
此时,综合工具综合的结果:FF+LUT+FF。同样用修改后的RTL代码,此时将 -no_srlextract 勾选,综合结果:

此时,综合的结果仍为全寄存器,印证了上面的结论。
总结
1、当移位寄存器长度小于等于 -shreg_min_size 时,最终实现的方式为触发器级联;
当深度大于 -shreg_min_size 时,采用 FF+LUT+FF的实现形式。
2、-no_srlextract 用于阻止将移位寄存器映射为 LUT,优先级高于 -shreg_min_size 。
3、要想用LUT实现移位寄存器,RTL设计时不能有移位寄存器复位功能,否则综合工具不会将移位寄存 器映射为FF+LUT+FF的结构。
-fsm_extraction
解释说明
-fsm_extraction用于设置状态机的编码方式。可选值如下:

-fsm_extraction 设置项的优先级高于 RTL 代码中指定的编码方式;
可选参数有独热码(one_hot)、顺序编码(sequential)、johnson编码(johnson)、格雷码(gray)、自动(auto)和无(none)。默认为auto。同样也可以用综合属性 FSM_ENCODING 来设置。
设计实践
这里随便写一个一段式简单状态机。
// 一个简单状态机
`timescale 1ns / 1ps
module FSM(
input I_CLK,
input I_RSTN,
input I_EN,
output reg O_WAVE
);
reg [3:0] R_CNT1;
reg [4:0] R_CNT2;
reg [2:0] R_CNT3;
reg [3:0] R_STATE;
// RTL 中用独热码编码
localparam LP_ST_S0 = 4'b0001;
localparam LP_ST_S1 = 4'b0010;
localparam LP_ST_S2 = 4'b0100;
localparam LP_ST_S3 = 4'b1000;
always @ (posedge I_CLK)
begin
if(~I_RSTN)
begin
R_STATE <= 4'd0;
R_CNT1 <= 4'd0;
R_CNT2 <= 5'd0;
R_CNT3 <= 3'd0;
O_WAVE <= 1'b0;
end
else
begin
case(R_STATE)
LP_ST_S0:
begin
R_CNT1 <= 4'd0;
R_CNT2 <= 5'd0;
R_CNT3 <= 3'd0;
if(I_EN)
begin
R_STATE <= LP_ST_S1;
O_WAVE <= 1'b1;
end
else
begin
R_STATE <= LP_ST_S0;
O_WAVE <= 1'b0;
end
end
LP_ST_S1:
begin
if(I_EN)
begin
if(&R_CNT1)
begin
R_CNT1 <= 4'd0;
R_STATE <= LP_ST_S2;
O_WAVE <= 1'b0;
end
else
begin
R_STATE <= LP_ST_S1;
R_CNT1 <= R_CNT1 + 1;
O_WAVE <= 1'b1;
end
end
else
begin
R_STATE <= LP_ST_S0;
end
end
LP_ST_S2:
begin
if(I_EN)
begin
if(&R_CNT2)
begin
R_CNT2 <= 4'd0;
R_STATE <= LP_ST_S3;
O_WAVE <= 1'b1;
end
else
begin
R_STATE <= LP_ST_S2;
R_CNT2 <= R_CNT2 + 1;
O_WAVE <= 1'b0;
end
end
else
begin
R_STATE <= LP_ST_S0;
end
end
LP_ST_S3:
begin
if(I_EN)
begin
if(&R_CNT3)
begin
R_CNT3 <= 4'd0;
R_STATE <= LP_ST_S1;
O_WAVE <= 1'b0;
end
else
begin
R_STATE <= LP_ST_S3;
R_CNT3 <= R_CNT3 + 1;
O_WAVE <= 1'b1;
end
end
else
begin
R_STATE <= LP_ST_S0;
end
end
default :
begin
R_STATE <= LP_ST_S0;
end
endcase
end
end
endmodule代码里面其实采用的独热码编码,在 -fsm_extraction 设置为 auto 的情况下,综合结果:
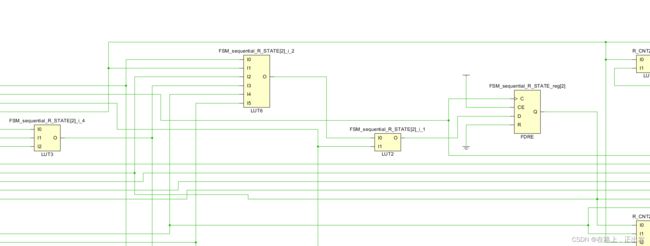
状态机的只有3bit,实际代码里面使用的 4 bit,并且状态信号的命名里面有sequential 这是为什么呢?打开综合日志文件就发现了猫腻。
综合日志文件相对路径:
...\<工程文件夹>\<工程文件夹>.runs\synth_1\runme.log
注意 synth_1(也可能是 synth_2、synth_3、synth_4……) 不是绝对的,如果有多种综合策略,请选择与之对应的文件夹。

在 auto 模式下,综合工具会对其进行优化,改变状态机的编码方式。
现在将 -fsm_extraction 设置为 one-hot,再次执行综合,状态机的编码方式变为独热码:
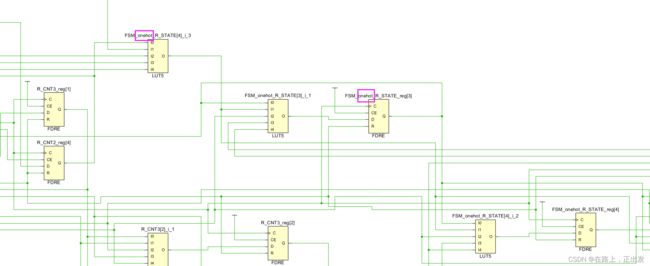
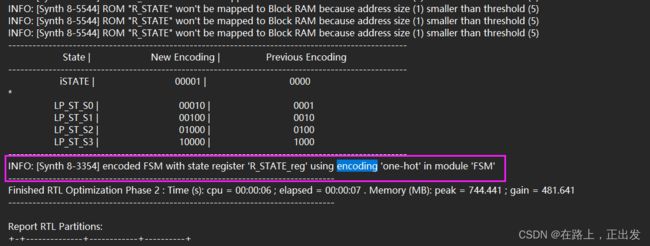
综合日志:
在保持 -fsm_extraction 设置为 one-hot 的情况下,利用综合属性进行约束:
总结
综合选项 -fsm_extraction 的优先级高于 RTL代码中所写的编码;
建议综合时直接更改 -fsm_extraction 的设置。
在综合的log文件中 ,搜索 encoding 或 synth 8-3354 可以查看对应的编码方式。
综合属性
ASYNC_REG
解释说明
单比特控制信号跨时钟域处理时,一般都会选择打拍。(* ASYNC_REG = "TRUE" *)将2级(或者3级)同步器的触发器放置于同一个SLICE中。减少线延迟对时序的影响。
设计实践
// 单比特信号跨时钟域
`timescale 1ns / 1ps
module CDC(
input I_CLK,
input I_RSTN,
input I_CTRL,
output O_CTRL
);
(*ASYNC_REG = "TRUE"*)reg [1:0] R_CTRL;
always @ (posedge I_CLK)
begin
if(~I_RSTN)
begin
R_CTRL <= 2'b00;
end
else
begin
R_CTRL <= {R_CTRL[0],I_CTRL};
end
end
assign O_CTRL = R_CTRL[1];
endmodule实现后的器件布局,两个同步寄存器放置在同一个SLICEL中。

总结
对于跨时钟域的单比特信号,对多级同步器添加综合属性:(* ASYNC_REG = "TRUE" *)
MAX_FANOUT
该综合属性可用于 XDC文件或者RTL代码中,例如:
RTL代码中:
(*MAX_FANOUT = 30*) reg R_TEST;XDC约束中:
set_property MAX_FANOUT 30 [get_cell R_TEST_reg]-flatten_hierarchy综合属性的设置对 MAX_FANOUT 属性的生效产生如下限制:
情形 |
-flatten_hierarchy属性 |
是否生效 |
MAX_FANOUT作用对象与其负载在同一层次 |
full、rebuilt、none |
是 |
MAX_FANOUT作用对象与其负载不在同一层次 |
full、rebuilt、 |
是 |
MAX_FANOUT作用对象与其负载不在同一层次 |
none |
否 |
主要是因为 MAX_FANOUT属性的约束必须要求作用对象及其负载在同一层次。
对于XILINX IP CORE的内部信号作用此属性时,可能会产生不生效的结果,可用如下方式优化:
phys_opt_design -force_replication_on_nets [get_nets net_name]SRL_STYLE、SHREG_EXTRACT
解释说明
SRL_STYLE
其用于指导综合工具Vivado将 SRL 移位寄存器,映射为何种形式。可选值:
register、srl、srl_reg、reg_srl、reg_srl_reg、block;
SHREG_EXTRACT
有两个设置值:yes 和 no 。设置为 yes 时,等效于 SRL_STYLE 设置为 reg_srl_reg ,设置为 no 时等效于 SHREG_EXTRACT 设置为 register。
总结
对于较大深度的移位寄存器,可以将其设置为 block ram ,即 将SRL_STYLE 的值设置为 block。否则会消耗过多的LUT。
不建议将时序的终点设置为移位寄存器,尤其在高速设计中。
USE_DSP
解释说明
默认情况下,用HDL代码描述的乘法、乘加、乘减、乘累加以及预加相乘运算都会映射为DSP48。但是加减运算默认情况下都会映射为LUT以及进位链资源。但是如果加减运算也想映射为DSP48,就需要用到综合属性,USE_DSP,该属性有4个值:simd,logic,yes,no。simd(Single Instruction Multiple Data)模式,可以使得位宽为48bit的ALU配置为4个12位的ALU,或者2个24比特位宽的ALU。此时DSP48内部的乘法器是无法使用的。
RAM_STYLE、ROM_STYLE
解释说明
这两个综合属性都是针对于手写RAM或者ROM时使用。
RAM_STYLE有4个值:block(将RAM映射为Block RAM),distributed(将RAM映射为分布式资源),registers(将RAM映射为寄存器),ultra(针对ultrascale plus 芯片,将RAM映射为UltraRAM)。
ROM_STYLE有两个取值:block 和 distributed。
EXTRACT_ENABLE、EXTRACT_RESET
解释说明
EXTRACT_ENABLE 可控制寄存器是否使用使能信号,当为 yes 时使能端口被使用,当为no时,是能端口将恒为高。
通常情况下,连接到触发器D端口的延迟小于 CE ,R,S 端口的延迟。
EXTRACT_RESET用于控制寄存器是否使用复位信号,注意此处的复位必须是同步复位。
总结
当使能端口的路径为关键路径时,可以尝试用EXTRACT_ENABLE属性将相应逻辑移至数据端口。
MARK_DEBUG
解释说明
在抓取FPGA内部信号时,可以将需要的信号设置为 (*MARK_DEBUG = "TRUE"*)。
附
查看逻辑级数 tcl 脚本命令:
report_design_analysis -logic_level_distribution -logic_level_dist_paths 5000 -name design_analysis_prePlace参考声明
【1】高亚军,Vivado 从此开始(进阶篇).北京:电子工业出版社. 2020.1