Pandas进阶指南:10个基本函数搞定数据处理(上)
大家好,在当今这个数据驱动的世界中,数据分析和洞察力可以帮助人们充分利用数据并做出更好的决策,数据提供了极大的竞争优势。本文将探索最强大的Python库pandas,讨论该库中对于数据分析而言最重要的函数。
导入数据
【数据集链接】:https://www.kaggle.com/datasets/kyanyoga/sample-sales-data
import pandas as pd
df = pd.read_csv("kaggle_sales_data.csv", encoding="Latin-1") # 加载数据
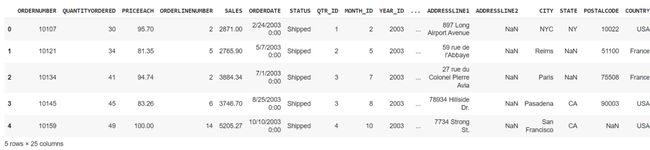
df.head() # 显示前五行
输出:
数据探索
本节将讨论各种函数,这些函数可以帮助用户更好地了解数据信息,如查看数据、获取平均值、平均数、最小/最大值或获取有关数据帧的信息等。
1.数据查看
df.head()显示数据的前五行:
显示数据的后五行:

df.sample(n):显示数据中的随机n行。
df.sample(6)

df.shape:显示数据的行数和列数(维度)。
(2823, 25)
这表示本文的示例数据集有2823行,每行包含25列。
2.统计
本节包含帮助用户在数据上执行平均值、最小/最大值和四分位数等统计操作的函数。
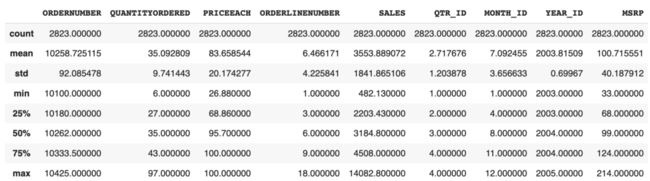
df.describe():获取示例数据每列的基本统计信息。
df.info():获取所使用的各种数据类型信息和每列的非空值计数。

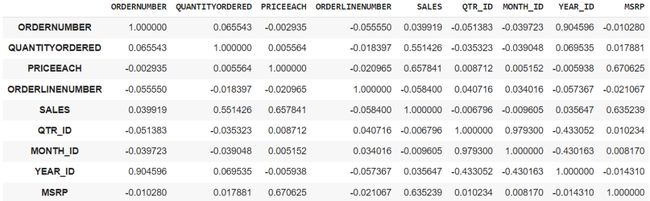
df.corr():给出数据帧中所有整数列之间的相关矩阵。
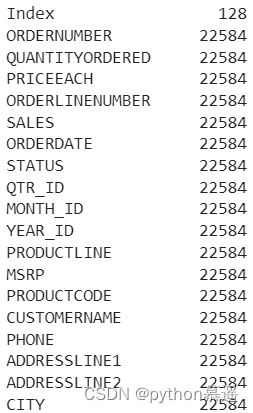
df.memory_usage():指示每一列消耗的内存量。
3. 数据选择
可以选择任何特定行、列甚至多个列的数据。
df.iloc[row_num]:根据索引选择特定行。
df.iloc[0]
df[col_name]:选择特定列。
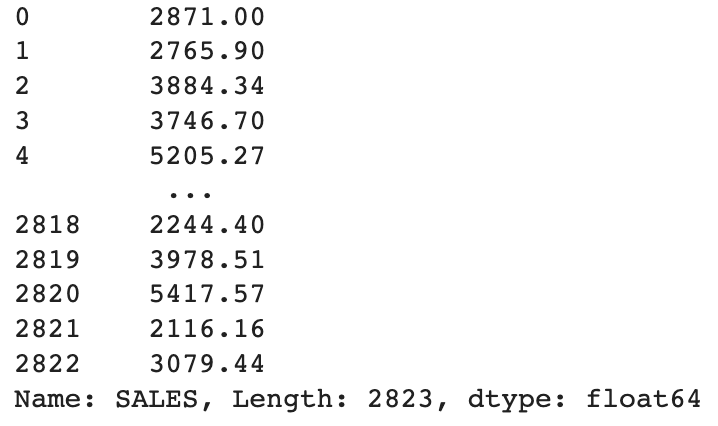
df["SALES"]
输出:
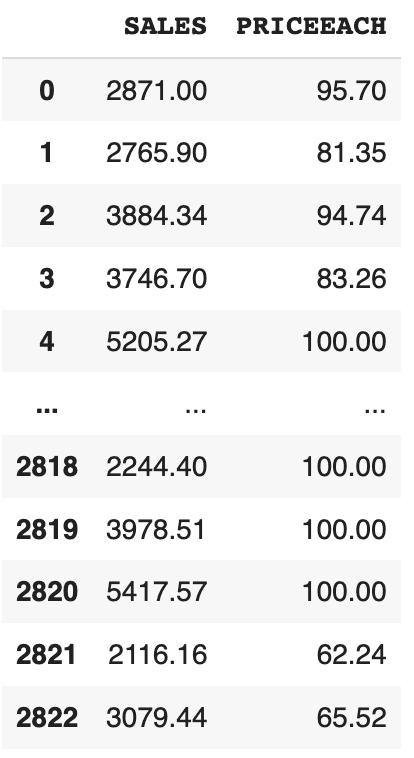
df[['col1', 'col2']]:选择给定的多个列。
df[["SALES", "PRICEEACH"]]
4.数据清洗
清洗函数用于处理缺失数据。数据中的某些行包含一些空值和垃圾值,这可能会影响训练好的模型的性能。因此,最好是纠正或删除这些缺失值。
-
df.isnull():识别数据帧中的缺失值。 -
df.dropna():删除任意列中包含缺失值的行。 -
df.fillna(val):用参数中给定的val填充缺失值。 -
df['col'].astype(new_data_type):将所选列的数据类型转换为不同的数据类型。
例如:
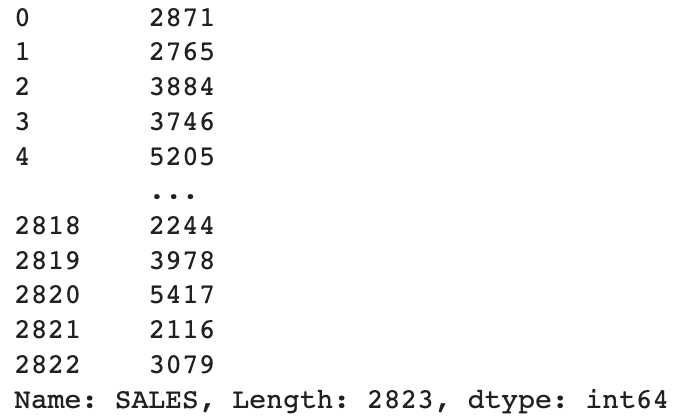
df["SALES"].astype(int)
本示例正在将SALES列的数据类型从浮点型转换为整型。
5.数据分析
本节介绍一些数据分析中实用的函数,如分组、排序和过滤。
5.1 聚合函数
可以根据名称对列进行分组,然后应用一些聚合函数,如求和、最小/最大值、平均值等。
df.groupby("col_name_1").agg({"col_name_2": "sum"})
例如:
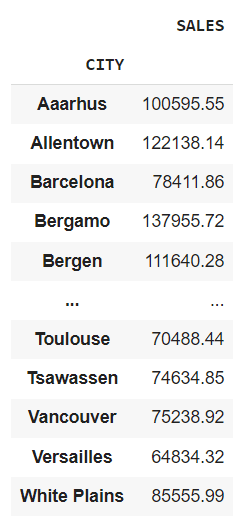
df.groupby("CITY").agg({"SALES": "sum"})
这将提供每个城市的总销售额。
如果想同时应用多个聚合函数,可以像这样编写代码:
aggregation = df.agg({"SALES": "sum", "QUANTITYORDERED": "mean"})
输出:
SALES 1.003263e+07
QUANTITYORDERED 3.509281e+01
dtype: float64
5.2 数据过滤
根据特定的值或条件过滤行中的数据:
df[df["SALES"] > 5000]
显示销售额大于5000的行,还可以使用query()函数过滤数据帧,它也将生成与上述类似的输出结果。
df.query("SALES" > 5000)
5.3 数据排序
根据特定列按升序或降序对数据进行排序:
df.sort_values("SALES", ascending=False) # Sorts the data in descending order
5.4 数据透视表
使用特定列创建汇总数据的数据透视表,当只想考虑特定列的影响时,这对分析数据非常有用。
pd.pivot_table(df, values="SALES", index="CITY", columns="YEAR_ID", aggfunc="sum")
详细解释如下:
values:它包含要填充表格单元格的列。
index:用于创建数据透视表行索引的列,该列的每个唯一类别都将成为数据透视表中的一行。
columns:它包含数据透视表的标题,每个唯一元素将成为数据透视表中的列。
aggfunc:这与之前讨论过的聚合器函数相同。
输出:

该输出显示的图表描述了特定城市在特定年份的销售总额。
我们已介绍了5个数据处理基本函数,Pandas进阶指南:10个基本函数搞定数据处理(下)将介绍其他5个基本函数。