探索Selenium的规避检测策略
Selenium之规避检测
背景
目前很多大网站有对selenium采取了监测机制。在正常情况下我们用浏览器访问相关网站的window.navigator.webdriver的值为 undefined或者为false。而使用selenium访问则该值为true。我们如何伪装,防止被检测出来呢?
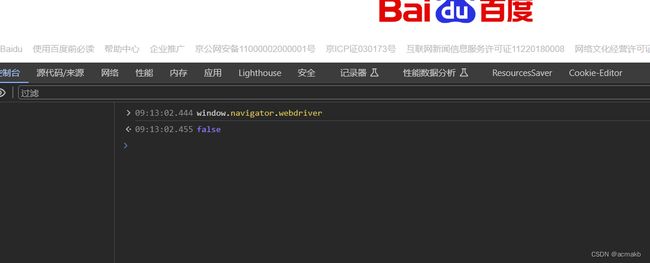
这是正常浏览器访问,接下来我们看一下selenium的。
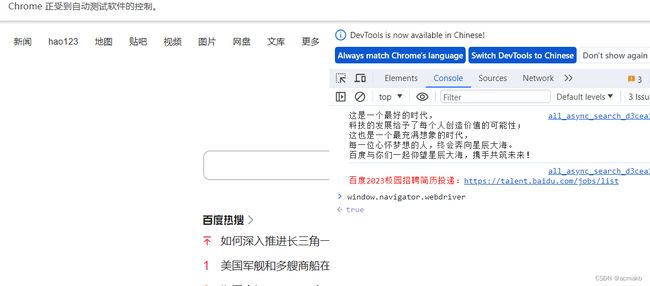
怎么样,是不是被检测出来呢 ?被检测出来的话,可能会不给你数据,弹出一些警告等等,会影响网页的布局等等
应对措施:
使用随机的User-Agent:
网站通常会根据User-Agent标识来判断请求是否来自真实的浏览器。通过设置随机的User-Agent,可以模拟多种浏览器行为。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import random
# 创建浏览器对象
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
# 设置随机User-Agent
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36",
# 添加其他User-Agent...
]
options.add_argument(f"user-agent={random.choice(user_agents)}")
# 创建浏览器对象
driver = webdriver.Chrome(options=options)
我们使用了Options对象来配置浏览器选项,通过add_argument()方法设置随机的User-Agent。您可以在user_agents列表中添加多个常见的浏览器User-Agent,然后使用random.choice()方法随机选择一个User-Agent作为请求头。
当然我们也可以使用python自带的UA库,不需要自己找一些UA了。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from fake_useragent import UserAgent
# 创建UserAgent对象
ua = UserAgent()
# 生成随机User-Agent
user_agent = ua.random
# 创建浏览器选项
options = Options()
options.add_argument(f"user-agent={user_agent}")
# 创建浏览器对象
driver = webdriver.Chrome(options=options)
设置窗口大小和位置
有些网站可能会根据窗口的大小和位置来检测自动化行为。可以使用set_window_size()和set_window_position()方法设置浏览器窗口的大小和位置。
# 设置窗口大小和位置
driver.set_window_size(1024, 768)
driver.set_window_position(0, 0)
通过设置合理的窗口大小和位置,可以使浏览器窗口看起来更像是由真实用户操作的。
延时操作
加适量的延时操作可以模拟人类用户的行为模式。
import time
import random
# 等待随机时间
time.sleep(random.uniform(1, 3))
# 执行点击操作
element.click()
# 等待一段时间
time.sleep(2)
在执行某些操作之前等待一段随机的时间,或在执行点击操作后等待一小段时间,可以降低被检测的风险。
注入js脚本:
使用 execute_script() 方法修改 window.navigator.webdriver 的值。
from selenium import webdriver
# 创建浏览器对象
driver = webdriver.Chrome()
# 执行 JavaScript 代码修改 window.navigator.webdriver 的值
driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
# 打开网页
driver.get("https://www.taobao.com")
# 继续执行其他操作...
# 关闭浏览器
driver.quit()
```
在上述代码中,我们使用 execute_script() 方法执行 JavaScript 代码来修改 window.navigator.webdriver 的值为 undefined,以欺骗网站的检测机制。
使用 ChromeOptions 添加 excludeSwitches 选项:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 创建浏览器选项
options = Options()
# 添加 excludeSwitches 选项,禁用 webdriver
options.add_experimental_option("excludeSwitches", ["enable-automation"])
# 创建浏览器对象
driver = webdriver.Chrome(options=options)
# 打开网页
driver.get("https://www.taobao.com")
# 继续执行其他操作...
# 关闭浏览器
driver.quit()
在上述代码中,我们使用 add_experimental_option() 方法添加 excludeSwitches 选项,并设置为 ["enable-automation"],以禁用 WebDriver,从而绕过网站的检测。
终极策略:
from selenium.webdriver import ActionChains
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
driver = Chrome('./chromedriver',options=chrome_options)
with open('./stealth.min.js') as f:
js = f.read()
#进行js注入
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get('https://www.baidu.com')
大家如果想要这个js文件,可以上Github上找一下,这里我就分享了。

温馨提示:
这些方法并不能保证适用于所有网站,因为不同的网站可能采取不同的检测机制。应该注意的是,规避网站的检测机制可能违反网站的使用条款或法律法规。在使用 Selenium 进行自动化脚本时,请确保遵守相关法律法规,并尊重网站的规则和限制。