机器学习实验二:决策树模型
系列文章目录
- 机器学习实验一:线性回归
- 机器学习实验二:决策树模型
- 机器学习实验三:支持向量机模型
- 机器学习实验四:贝叶斯分类器
- 机器学习实验五:集成学习
- 机器学习实验六:聚类
文章目录
- 系列文章目录
- 一、实验目的
- 二、实验原理
- 三、实验内容
- 四、实验步骤
-
- 1.数据集引入及分割
- 2. 训练决策树
- 3. 利用 CCP 进行后剪枝
- 总结
一、实验目的
(1)了解 pandas 和 sklearn 数据科学库功能;
(2)掌握决策树原理,包括划分选择中三种经典指标信息增益、增益率和基尼
指数的优缺点;
(3)掌握剪枝处理方法及作用;
(4)学会通过精确率、召回率和 F1 值度量模型性能。
二、实验原理
决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过
程,由节点和有向边组成,结点有 2 种结构:内部节点表示一个特征或属性,叶
节点表示一个类别。它可以认为是 if-then 规则的集合,也可以认为是定义在特
征空间与类空间上的条件概率分布。
学习时,利用训练数据根据损失函数最小化的原则建立决策树模型。预测时,
对新的数据,利用决策树模型进行分类。决策树学习通常包括 3 个步骤:特征选
择、决策树的生成和决策树的修剪。
三、实验内容
使用 Python 读取数据集信息并利用 sklearn 训练决策树模型,随后使用生
成的决策树实现分类预测,调整决策树划分方法及剪枝方法,并根据精确率、召
回率和 F1 值度量模型性能。
(1)实验数据介绍
实验数据为来自 UCI 的鸢尾花三分类数据集 Iris Plants Database。
数据集共包含 150 组数据,分为 3 类,每类 50 组数据。每组数据包括 4 个
参数和 1 个分类标签,4 个参数分别为:萼片长度 sepal length、萼片宽度 sepal
width、花瓣长度 petal length、花瓣宽度 petal width,单位均为厘米。分类
标签共有三种,分别为 Iris Setosa、Iris Versicolour 和 Iris Virginica。
数据集格式如下图所示:
为方便使用,也可以直接调用 sklearn.datasets 库中提供的 load_iris()
方法加载处理过的鸢尾花分类数据集。
(2)评价指标介绍
评价指标选择精确率 P、召回率 R、F1 度量值 F1。
具体代码实现时,可以直接调用 sklearn 库中的相应方法进行计算。
四、实验步骤
1.数据集引入及分割
将数据集按 2/3 训练集,1/3 测试集的比例进行随机分割。代码如下:
X = iris.data
y = iris.target
X_train,X_test,y_train,y_test =
train_test_split(X,y,test_size=1/3,random_state=0)
print(' 数 据 集 样 本 数 : {}, 训 练 样 本 数 : {}, 测 试 集 样 本 数 :
{}'.format(len(X),len(X_train),len(X_test)))
2. 训练决策树
利 用 sklearn 提供的 DecisionTreeClassifier() 方 法 构 造 决 策 树 ,
DecisionTreeClassifier()方法的常用参数如下:
划分准则 criterion,可选:基尼指数 gini、信息增益 entropy、对数损失
log_loss,默认 gini;
最大树深度 max_depth,整数型,默认为不限制;
最大叶节点数 max_leaf_nodes,整数型,默认为不限制;
最大代价复杂度 ccp_alphat,非负浮点型,默认为 0.0。
我们这里分别利用三种不同的划分准则,以 4 为最大深度对树进行前剪枝。
以使用基尼指数的决策树为例,训练并查看树结构,代码如下:
gini_model =
DecisionTreeClassifier(criterion='gini',max_depth=4,splitter='best')
gini_model.fit(X_train,y_train)
gini_y_pred = gini_model.predict(X_test)
tree.plot_tree(gini_model)
plt.show()
可以得到对应的树结构。可以看到,排除根节点,这棵决策树为 4 层的二叉
树,这也符合基尼指数划分方法的特点。计算该树的精确率、召回率和 F1 度量
值。
继续训练其他两种划分方式,在同等预剪枝条件下,对于信息增益 Entropy
方式划分,可以得到对应的决策树。
对于对数损失 log_loss 方式划分,能得到对应的决策树和性能结果。
3. 利用 CCP 进行后剪枝
CCP(Cost Complexity Pruning)为代价复杂度剪枝法,核心思想为在树构
建完成后,对树进行剪枝简化,使以下损失函数最小化: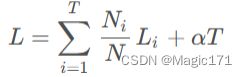
其中,T 为叶子节点个数,N 为所有样本个数,N_i 为第 i 个叶子节点上的
样本数,L_i 为第 i 个叶子节点的损失函数,α为待定系数,用于确定惩罚节点
个数,引导模型用更少的节点。
具体操作中,首先使用 cost_complexity_pruning_path()方法需要计算树
的 CCP 路径,得到 alpha 与树纯度的关系,具体代码如下:
pruning_path = gini_model.cost_complexity_pruning_path(X_train, y_train)
print("ccp_alphas:",pruning_path['ccp_alphas'])
print("impurities:",pruning_path['impurities'])
总结
以上就是今天要讲的内容,机器学习实验二:决策树模型