Python爬虫实战,Request+urllib模块,批量下载爬取飙歌榜所有音乐文件
先看效果展示

前言
今天给大家介绍的是Python爬取飙歌榜所有音频数据并保存本地,在这里给需要的小伙伴们代码,并且给出一点小心得。
首先是爬取之前应该尽可能伪装成浏览器而不被识别出来是爬虫,基本的是加请求头,但是这样的纯文
本数据爬取的人会很多,所以我们需要考虑更换代理IP和随机更换请求头的方式来对音乐数据进行爬取。
在每次进行爬虫代码的编写之前,我们的第一步也是最重要的一步就是分析我们的网页。
通过分析我们发现在爬取过程中速度比较慢,所以我们还可以通过禁用谷歌浏览器图片、JavaScript等方式提升爬虫爬取速度。
开发工具
Python版本: 3.8
相关模块:
requests模块
re模块
urllib模块
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
思路分析
浏览器中打开我们要爬取的页面
按F12进入开发者工具,查看我们想要的音乐数据在哪里
这里我们需要页面数据就可以了


代码实现
# 存放音乐文件的文件夹
folder = r'F:\music'
if not isdir(folder):
mkdir(folder)
# 音乐飙升榜地址
url = 'https://music.163.com/discover/toplist?id=3779629'
# 模拟Chrome浏览器
headers = {'User-Agent': 'Chrome/88.0.4324.190'}
req = Request(url, headers=headers)
# 读取网页源代码
with urlopen(req) as fp:
content = fp.read().decode()
# 正则表达式,提取音乐id和名字
pattern = r'(.+?) '
for music_id, music_name in findall(pattern, content):
music_file = rf'{folder}\{music_name}.mp3'
if isfile(music_file):
print(f'文件已存在,跳过...{music_name}')
continue
# 下载地址
download_url = rf'https://music.163.com/song/media/outer/url?id={music_id}'
req = Request(download_url, headers=headers)
# 读取网络音乐文件数据,写入本地文件
with urlopen(req) as fp:
content = fp.read()
with open(music_file, 'wb') as fp:
fp.write(content)
print(f'下载完成...{music_name}')
最后
今天的分享到这里就结束了 ,感兴趣的朋友也可以去试试哈
对文章有问题的,或者有其他关于python的问题,可以在评论区留言或者私信我哦
觉得我分享的文章不错的话,可以关注一下我,或者给文章点赞(/≧▽≦)/
读者福利:知道你对Python感兴趣,便准备了这套python学习资料,
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python永久使用安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
Python学习路线汇总
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(学习教程文末领取哈)

Python必备开发工具

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
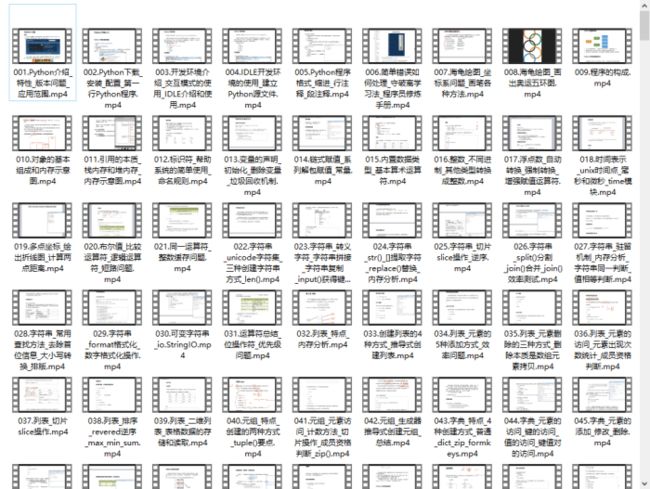
Python学习视频600合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

100道Python练习题
检查学习结果。
面试刷题


资料领取
这份完整版的Python全套学习资料已为大家备好,朋友们如果需要可以微信扫描下方二维码添加,输入"领取资料" 可免费领取全套资料【有什么需要协作的还可以随时联系我】朋友圈也会不定时的更新最前言python知识。

好文推荐
了解python的前景: https://blog.csdn.net/weixin_49892805/article/details/127196159
了解python的副业: https://blog.csdn.net/weixin_49892805/article/details/127214402