Yolov3学习笔记
前言
终于更新下YOLOv3,别问干啥,问就是去项目上打标签了…
人工智能有多智能,背后就有多少人工。
而我就是那个人工-.-。
1.YOLOv3算法思想
YOLOv3的作者自从写完YOLOv3后就不再更新,因为开源算法会被用来干不好的事情,这样确实很遗憾,但后面依然有人接手,现在已经到V8。开源这东西,真的很伟大,但确实是更容易被利用。
原文地址:https://arxiv.org/pdf/1804.02767.pdf
文章写的很随意,性能上再次有了提升,还是那样,直接放结构图,原文中是没有总图的。

简单来讲就是输入一张416×416的图像,得到三个不同尺度的特征图,由于尺度不同,这也更加方便检测不同大小的物体。
52×52的特征图,更适合于检测小目标。26×26更适合中等目标,13×13适合大目标。
下面看一下有哪些提升吧。
1.1 改进一:Bounding Box Prediction(先验框的预测)
同YOLOv2一样,YOLOv3预测框依然是利用聚类的方法确定anchors的大小和数量。
不同的是,YOLOv3使用逻辑回归预测每个边界框的对象得分,根据这个得分情况来判断正、负、忽略样本。
正样本是先验框与真实框IOU最大的,置信度设置为1。
忽略样本:与GT的重叠虽然不是IOU最大,当IOU大于阈值0.5时,设置忽略样本。
负样本:若没有跟任何GT发生重叠对应,则为0。
这样的方法显示是因为有三个尺度的特征图,每个尺度特征图产生三个预测框,但每个grid cell只会保留一个预测框,同时不同尺度的特征图可能会出现重叠,那么忽略样本解决了这一难题。正样本确定为1是更合理的,因为计算的得分情况是很小的,不利于小目标检测。
通过如下图的这种计算,来实现。
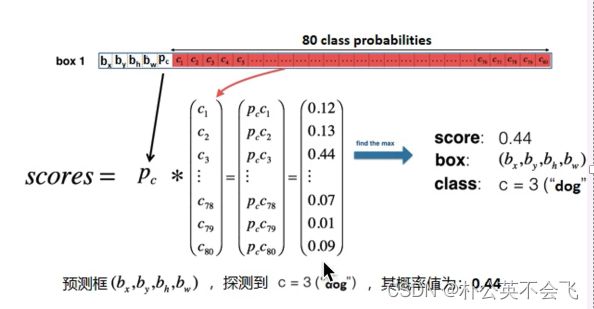
1.2 改进二:Class Prediction(类别的预测)
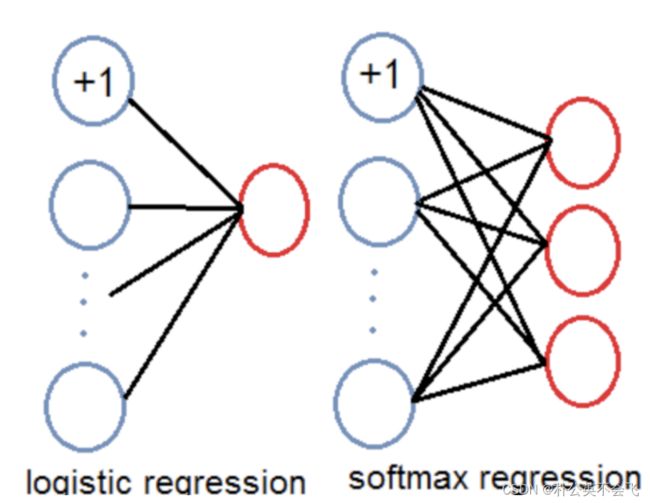
类的预测从单类改为多分类。
如20个类别中,全是互斥,那么softmax也许是一个好的选择。但是如果存在不互斥的呢。
如橘猫、蓝猫、布偶,如果仅仅区分别cat,那也太草率了。为了区分更多类别,采用了逻辑回归。
logistic regression。
1.3 改进三:Predictions Across Scales(多尺度检测)
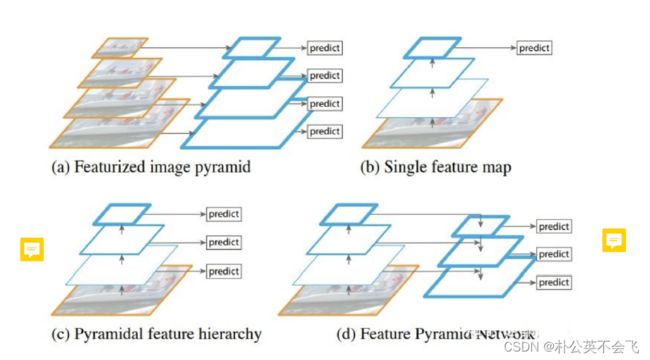
多尺度检测。其实从刚开始的结构图中就可以发现了,三个尺度来对应检测不同大小的物体。
不同尺度的灵感来源于特征金字塔,d图是本文利用的模型。它更好的利用了前层的特征信息,该方法允许从上采样特征中获得更有意义的语义信息,并从早期的特征映射中获得更细粒度的信息。
文章是在COCO数据集上做了测试,9个聚类的先验框大小分别为:(10×13)、(16×30)、(33×23)、(30×61)、(62×45)、(59× 119)、(116 × 90)、(156 × 198)、(373 × 326)。再将这9个划分到三个不同尺度上。
1.4 改进四:Feature Extractor(特征提取)
特征提取应该是变化最大的,从YOLOv2的Darknet-19(有19个卷积层和5个MaxPooling层)变换为Darknet-53。
作者通过实验发现,Darknet与最先进的网络相比,在保持精度的情况下,依然保持速度。
这对工程来说是非常棒的了。
top1:预测labels中,最后的概率向量中取最大的作为预测结果,如果最大的那个预测的分类结果正确就正确,若不正确则不正确。一般情况下默认是top1。
top5:预测labels中,最后的概率向量中取最大的前五个,这五个中,如果有一个预测正确,则预测分类结果正确。只有这五个预测全部错误,则预测分类结果错误。
Bn Ops和BFLOP/s的解释分别是“billions of operations”和“billion floating point operations per second
文章中是用硬件平台Titan x做的实验,这两个参数可以看出在相同硬件平台下的计算效率,进而用FPS来判断。由于ResNet结构层数非常多,所以其实效率是不高的,但是YOLOv3其实是兼顾了准确度和效率的。

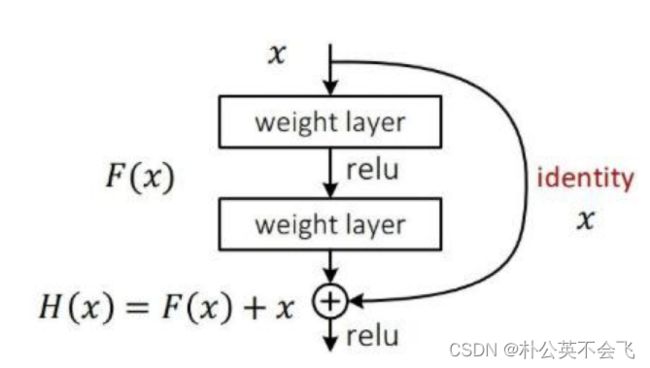
Darknet53网络结构是引用了残差模块的,使得模型可以更深而不会出现梯度消失问题。
在小破站看视频学习看到一个评论通俗易懂的讲残差模块。

1.5 Training
我们仍然在完整的图像上训练,没有硬的负面挖掘或任何类似的东西。我们使用多尺度训练,大量的数据增强,批处理归一化,所有标准的东西。我们使用Darknet神经网络框架进行训练和测试。
这里可以看出作者依然是使用了一些之前标准化的技术,数据增强,批量归一化等。
1.6 实验
后续实验,作者对比了其他当时顶尖的算法,获得成功。
总结来说就是,精度接近顶尖,推理速度却快的飞起。


作者退出,就是为了世界和平。放一段作者的心声吧。
But computer vision is already being put to questionable use and as researchers we have a responsibility to at least consider the harm our work might be doing and think of ways to mitigate it. We owe the world that much。
世界就是不公平和不公正的,但也有人在努力,不是吗。
部分引用链接:
https://blog.csdn.net/qq_40373651/article/details/118704010
https://cloud.tencent.com/developer/article/1494963