Spring Cloud—Eureka万字符长文介绍,收藏这一篇就够啦!
Spring Cloud中Eureka注册中心介绍
前面的博客(我上一节的内容)展示了模拟微服务的场景,也讲述了前面”微服务模拟”的优劣。那么延续后面的内容,我们首先需要动态管理这些url路径,让服务的调用方能够灵活的连接服务方以及统一管理服务配置等问题,此时就是展现Eureka的作用了。
1、Eureka介绍
1.1 初了解
我们就举一个典型的例子:比如说你要打车,打什么样的车?(拼客?车型?)然后你输入想去的目的地并到打车软件上。此时软件会自动找到安排一个符合你要求的车提供服务。
此时服务的调用者就好比此时打车的你,而Eureka就像是“获取你服务,并自动给你服务的指令器”。你不需要像平时一样随便到马路拦一辆出租车,在这儿只需要告知Eureka你所需要的服务即可。
1.2 Eureka原理

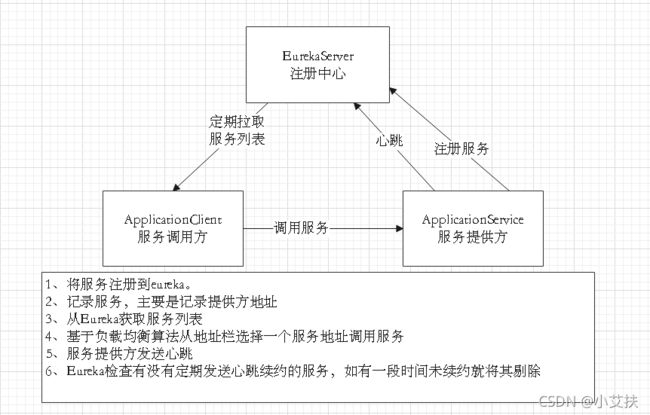
稍微看一下如上图所示,我们可以看到如下信息:
- Eureka:即服务注册中心(它可以是一个集群)。它对外暴露自己的地址
- 提供者:启动后向Eureka注册自己信息(地址,提供什么服务)
- 消费者:向Eureka订阅服务,Eureka会将对应服务的所有提供者地址列表发送给消费者,并且定期更新
- 心跳(续约):提供者定期通过HTTP方式向Eureka刷新自己的状态
当然顺序内容应该是这样的。
2、Eureka初尝试
在前面我们简单介绍了Eureka的原理,接下来就是编码部分的实现。编码步骤跟原理部分的实现步骤不一样,这里要稍微注意一下。
2.1 编写EurekaServer部分
1、首先我这儿创建好父工程,将EurekaServer放置父工程下,并且Maven配置如下:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>spring-cloud-projectartifactId>
<groupId>com.xafgroupId>
<version>1.0-SNAPSHOTversion>
parent>
<modelVersion>4.0.0modelVersion>
<artifactId>eureka-serverartifactId>
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-serverartifactId>
dependency>
dependencies>
project>
2、编写启动类
@EnableEurekaServer
@SpringBootApplication
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class,args);
}
}
3、编写application.yml
server:
port: 10000
spring:
application:
name: eureka-server
eureka:
client:
service-url:
#eureka可以是一个,也可以是集群。如果是集群的话就指定多个eureka地址
defaultZone: HTTP://127.0.0.1:10000/eureka
#不注册自己
register-with-eureka: false
#不拉取服务
fetch-registry: false
此时目录结构如下图所示:

打开http://127.0.0.1:10000后,如下介绍网页的各个列表信息:

上图展示的是系统状态。比如我在这儿的创建时间是9:15等等…

上图展示的是eureka集群,这里就是刚刚注册的url。
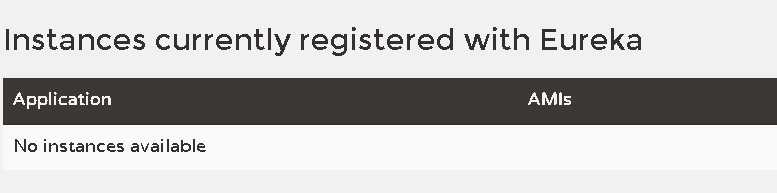
上图展示的是注册到Eureka的服务的列表,显然我们暂时还没有注册服务。
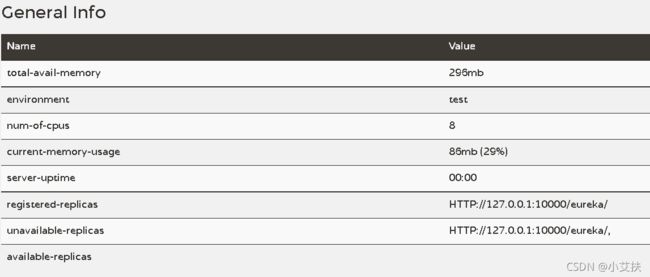
上图展示的是基本信息。
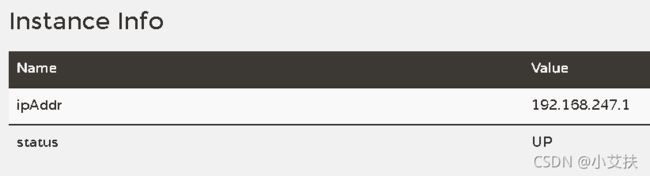
上图展示的是eureka的实例化的状态,比如此时状态是status:up。
2.2 服务的注册
1、在服务提供方上添加Eureka客户端依赖,这里注意一下不要将eureka-server上的依赖直接复制粘贴。
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
2、启动器:
@SpringBootApplication
@MapperScan("com.xaf.mapper")
@EnableDiscoveryClient
//上面是开启Eureka客户端发现功能
public class UserApplication {
public static void main(String[] args) {
SpringApplication.run(UserApplication.class,args);
}
}
3、application.yml配置文件
server:
port: 9000
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/user
username: root
password: root
application:
name: user-service
mybatis:
type-aliases-package: com.xaf.pojo
eureka:
client:
service-url:
defaultZone: HTTP://127.0.0.1:10000/eureka
这里稍微注意一下:
这里我们添加了spring.application.name属性来指定应用名称,这里是将来会作为应用的id使用。
不用指定register-with-eureka和fetch-registry,因为默认是true。
4、此时打开Eureka启动类的基础上再启动服务提供方user-service启动类

此时再看,已经成功注册到user-service。
2.3 服务的发现
在服务的调用&消费方添加Eureka客户端的依赖,依然可以使用@DiscoveryClient注解完成。
1、添加依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
2、启动类
@SpringBootApplication
@EnableDiscoveryClient //开启Eureka客户端
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
3、配置文件
spring:
application:
name: consumer-demo
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10000/eureka
4、对于消费方,需要获取服务提供方的相对应url并且以负载均衡的方式进行服务调用。(负载均衡暂略)
@RestController
@RequestMapping("/consumer")
public class ConsumerController {
@Autowired
private RestTemplate restTemplate;
@Autowired
private DiscoveryClient discoveryClient;
@GetMapping("/{id}")
public User queryById(@PathVariable Long id){
//String url = "http://localhost:9091/user/" + id;
/**
* 1、接收方&消费方获取来自user-service的url(可以是集群所以是list)信息
*/
List<ServiceInstance> serviceInstances = discoveryClient.getInstances("user-service");
/**
* 2、这里我们只注册一个url,取get(0)即可
*/
ServiceInstance serviceInstance = serviceInstances.get(0);
/**
* 3、将字符信息分别插在url上(host名和port名)
*/
url = "http://" + serviceInstance.getHost() + ":" + serviceInstance.getPort() + "/user/" + id;
return restTemplate.getForObject(url, User.class);
}
}
此时完成服务的发现内容,打开网址成功。

Eureka初尝试完成。
3、Eureka详细了解
3.1 高可用的Eureka
在上面我强调过Eureka可以是一个集群。事实上,Eureka Server是一个web应用,可以启动多个实例(配置不同端口)保证Eureka Server的高可用。这就涉及到服务同步的内容。
服务同步:
- 它在于多个Eureka Server之间也会相互注册为服务。
- 当服务提供者注册到Eureka Server集群中的某个节点时,该节点会把服务的信息同步给集群中的每个节点,从而实现数据同步。
- 因此,无论客户端访问到Eureka Server集群中的任 意一个节点,都可以获取到完整的服务列表信息。 当然而作为客户端,需要把信息注册到每个Eureka中才行。
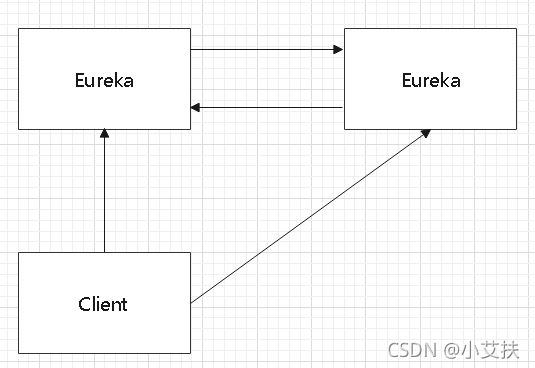
如上图所示,那么如果假设有三个Eureka,则每一个Eureka都需要再注册到其他几个Eureka服务中。比如有三个分别为10000、10001、10002,那么:
- 10000要注册到10001和10002上
- 10001要注册到10000和10002上
- 10002要注册到10000和10001上
3.2 搭建高可用Eureka
1、首先修改原来的EurekaServer的配置
server:
port: ${port:10000}
spring:
application:
name: eureka-server
eureka:
client:
service-url:
#eureka可以是一个,也可以是集群。如果是集群的话就指定多个eureka地址
defaultZone: ${defaultZone:HTTP://127.0.0.1:10000/eureka}
#不注册自己
#register-with-eureka: false
#不拉取服务
#fetch-registry: false
先说明以上改动:
- 首先是默认了注册自己和拉取服务为True,这样自己就会注册到注册中心上去了。
- 将service-url值改成另一台的Eureka地址而非自己。
2、配置新的Eureka

首先拷贝一份之前的调试配置,修改Name和VM option如上图所示。
-Dport=xxxxx -DdefaultZone=http://127.0.0.1:10000/eureka
此时运行两个Eureka后,在10000端口完成自身注册和对端口号为10001的注册。

当然,因为EurekaServer不止一个,因此注册服务的时候,service-url参数需要变化:
eureka:
client:
service-url:
# EurekaServer地址,多个地址以','隔开
defaultZone:http://127.0.0.1:10086/eureka,http://127.0.0.1:10087/eureka
4、Eureka客户端和服务端的其他配置
完成如上的内容,我们了解从服务注册到获取服务url列表并调用服务。但是还有一些细节的配置需要了解。
首先是客户端内容
user-service服务提供:
- 服务地址的续约
- IP地址的使用
consumer服务调用:
- 获取服务地址的频率
其次是服务端Eureka内容
- 失效剔除
- 自我保护
接下来就从服务提供、服务调用和服务端三个内容讲一下配置。
4.1 服务提供
4.1.1 服务的IP地址使用
服务提供者在启动时,会检测配置属性中的: eureka.client.register-with-erueka=true 参数是否为true,事实上它默认就是true。
如果值确实为true,则会向EurekaServer发起一个Rest请求,并携带自己的元数据信息, EurekaServer会把这些信息保存到一个双层Map结构中。
- 第一层Map的Key是服务id,即一般是配置中的spring.application.name属性。比如user-service。
- 第二层Map的Key是服务的实例id,一般是以HostName+serviceId(第一层id)+port。比如我的就是
localhost:user-service:10000。 - 值则是服务的实例对象,也就是一个服务本身。因为是以双层Map数据结构存在,那么也就是可以同时启动多个不同的实例,甚至是形成一个集群。
首先注册默认使用主机名或者localhost。如果是用ip进行注册就可以配置如下:
eureka:
instance:
ip-address: 127.0.0.1 # ip地址
prefer-ip-address: true # 更倾向ip而非host
什么意思呢?原来应该是以localhost的形式,现在只是变成127.0.0.1形式。不会影响Eureka的显示。
4.1.2 服务的续约
在注册服务完成以后,服务提供者会维持一个心跳,即定时向EurekaServer发起Rest请求。它告诉 EurekaServer自己还是“活着的”。这个就称为服务的续约(renew)。
eureka:
instance:
lease-expiration-duration-in-seconds: 90
lease-renewal-interval-in-seconds: 30
根据翻译可得:
- lease-renewal-interval-in-seconds:服务续约(renew)的间隔,默认为30秒
- lease-expiration-duration-in-seconds:服务失效时间,默认值90秒
意思就是默认情况下每30秒,服务会向注册中心发送一次心跳以证明自己还活着。
如果超过90秒没有发送心跳,EurekaServer就会认为该服务宕机,会从服务列表中移除。
一般来说,这两个值直接默认就好了(这里应该是因人而异好了,对于像我这样的学习者就默认)。
4.2 服务调用
4.2.1 获取服务列表
当服务消费者启动时,会检测 eureka.client.fetch-registry=true 参数的值,如果为true,则会从Eureka Server服务的列表拉取只读备份,然后缓存在本地。比如如下:
eureka:
client:
registry-fetch-interval-seconds: 30
这个意思也很简单,就是每隔30秒来获取服务的订阅。一般来说,这两个值直接默认就好了(对于像我这样的学习者而言)。当然越小获取服务的最新信息就越快。
4.3 服务端Eureka
4.3.1 失效剔除
首先先说一下服务的下线概念:即一个服务的正常关闭或者关机操作,他会触发一个服务下线的REST请求发给Eureka,即告知Eureka自己已经下线。此时注册中心将其置于下线状态。
其次是失效剔除:其实一个服务的失效按理来说应该有很多因素存在。比如说有网络的故障等等就或多或少会影响Eureka收到服务的心跳。Eureka会默认每隔一段时间 (默认为60秒)将当前清单中超时(默认为90秒)没有续约的服务剔除,这个操作被称为失效剔除。
此时使用eureka.server.eviction-interval-timer-in-ms 参数对其进行修改,单位是毫秒。
4.3.2 自我关停
再假设一个场景。在一个网络延迟很高的环境下,Eureka会以一段时间内统计一个服务实例的心跳失败的比重是否超过一个范围。当然因为服务是必要的并没有宕机,并且在网络延迟很高的环境下显然是“情有可原”的,Eureka就会把当前服务实力的注册信息保护起来不进行剔除。
eureka:
server:
enable-self-preservation: false # 关闭自我保护模式(缺省为打开)
eviction-interval-timer-in-ms: 1000 # 扫描失效服务的间隔时间(缺省为60*1000ms)
一般而言应该是会关闭自我保护的状态。具体原因暂时还不是很明确(后续还是得靠大佬多补充补充)
总结
首先我们了解了Eureka基础的原理,并且通过Eureka实现了上一个部分"因为硬编码造成的高度耦合"的问题。了解高可发的Eureka内容部分以及Eureka的一些步骤在实际开发上的详细介绍。有些地方还是查找资料分享(但是内容全程手敲+图片原创),在此感谢大佬的回访阅读,并且还请大佬多多批评指正。