多线程(初阶七:阻塞队列和生产者消费者模型)
目录
一、阻塞队列的简单介绍
二、生产者消费者模型
1、举个栗子:
2、引入生产者消费者模型的意义:
(1)解耦合
(2)削峰填谷
三、模拟实现阻塞队列
1、阻塞队列的简单介绍
2、实现阻塞队列
(1)实现普通队列
(2)加上线程安全
(3)加上阻塞功能
3、运用阻塞队列的生产者消费者模型
都看到这了,点个赞再走吧,谢谢谢谢谢
一、阻塞队列的简单介绍
首先,我们都知道,队列是先进先出的一种数据结构,而阻塞队列,是基于队列,做了一些扩展,在多线程有就非常有意义了
阻塞队列的特性:
(1)是线程安全的
(2)具有阻塞的特性
①当队列满了,这时不能往队列里放数据,就会阻塞等待,等队列的数据出队列后,这时队列没满,才能放数据。
②当队列空了,这时不能拿队列里的数据,就会阻塞等待,等有数据如队列了,这时队列不为空,才能拿数据。
这里,阻塞队列的用处非常大,基于阻塞队列的功能,就可以实现 “生产者消费者模型”。
二、生产者消费者模型
生产者消费者模型是一种很朴素的概念,描述的是一种多线程编程的方法。
1、举个栗子:
一家人包饺子,首先得和面,和完面就要开始擀饺子皮了,然后才开始包饺子,这里,因为一般家里也只有一个擀面杖,所以只能一个人擀饺子皮,其余的家人就会帮忙包饺子,假设一个人擀饺子皮,2个人包饺子,那么擀饺子皮的人就是生产者,包饺子的人就是消费者;这也就是消费者生产者模型。
一个桌子能发饺子皮的数量是有限的,当擀饺子皮的人比较快,桌子放满饺子皮后,就要等包饺子的人,消耗一些饺子皮来包饺子,才能继续擀饺子皮;而这也类似阻塞队列中队里满的情况。当包饺子的人包的比较快,桌子上的饺子皮都没了,就要等擀饺子皮的人擀了饺子皮后才能继续包饺子;而这也类似阻塞队列空的情况。不同的人分工不同,也类似多线程,各自干各自的事情。
2、引入生产者消费者模型的意义:
(1)解耦合
引入生产者消费者模型,就能更好的做到解耦合(把代码的耦合程度,从高降低,就称为解耦合)
在实际开发中,会涉及到 “分布式系统” ,服务器的整个功能不是又一个服务器完成实现的,而是由多个服务器,各自实现各自的一部分功能,再通过网络通信,把这些服务器联系起来,最终完成整个服务器的功能。粗糙流程如图:
而这时,入口服务器与A、B服务器的联系是密切相关的,请求要经过入口服务器,才能传达给A、B服务器,再A、B服务器拿到想要的数据,再返回给入口服务器,通过入口服务器,再把响应传给客户端。如果是这样,那如果请求突然骤升,这时超过入口服务器接收请求的峰值,这时入口服务器就挂了,入口服务器挂了后,A、B服务器拿不到请求,也会挂掉,这就体现了入口服务器和A、B服务器的耦合性比较高。
当我们在入口服务器和A、B服务器之间引入阻塞队列时,如图:
这时,如果入口服务器挂了,但是阻塞队列中还有请求的数据,至少不会因入口服务器挂了,A、B服务器也挂了,这样,入口服务器和A、B服务器的耦合性也就降低了。


(2)削峰填谷
如图,当客户端这边的请求突然骤增时,入口服务器都是比较能抗压的,但是也是有极限的,这时我们引入阻塞队列,就可以把这些请求数据都放进阻塞队列中,形成一个缓冲区,这样,即使外面的请求达到了峰值,也是由阻塞队列来承担,这样就形成了削峰填谷的效果。
注意:这时的阻塞队列,是基于阻塞队列这一数据结构,而实现的服务器程序,所以也叫消息队列
三、模拟实现阻塞队列
1、阻塞队列的简单介绍
在java标准库中,提供了现成的阻塞队列这一数据结构,如图:
是基于队列扩展而来的,队列有的,它也有;我们知道,入队列时可以用offer方法,出队列时可以用poll方法,在阻塞队列中,也有这两个方法,但是这两个方法是不带阻塞功能的;其中,在阻塞队列中,put是在阻塞功能的入队列,take方法是带阻塞功能的出队列。
代码案例:
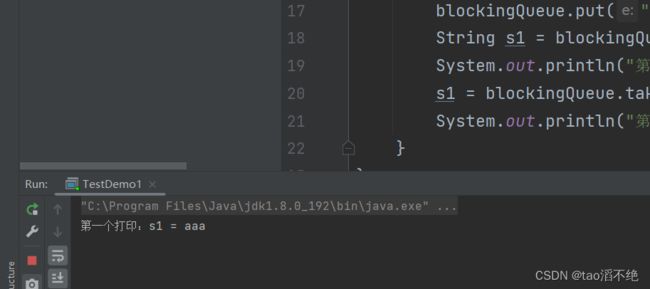
public class TestDemo1 { public static void main(String[] args) throws InterruptedException { BlockingQueueblockingQueue = new ArrayBlockingQueue<>(10); blockingQueue.put("aaa"); String s1 = blockingQueue.take(); System.out.println("第一个打印:s1 = " + s1); s1 = blockingQueue.take(); System.out.println("第二个打印:s1 = " + s1); } } 执行结果:
线程卡住不动了,原因是想要第二次出队列时,队列是空的,所以要等队列有元素入队列时,才能出队列,也就是说,这是带有阻塞功能的。

2、实现阻塞队列
阻塞队列是通过循环队列实现的,而队列是依靠数组来实现的,这里的阻塞队列,我们只模拟实现其中的put和take方法。
(1)实现普通队列
代码:
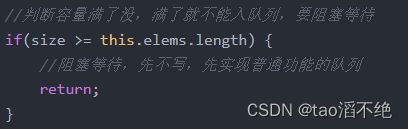
// 为了简单, 不写作泛型的形式. 考虑存储的元素就是单纯的 String class MyBlockingQueue { private String elems[] = null; private int head = 0;//记录头结点 private int tail = 0;//记录尾结点 private int size = 0;//队列元素个数 //构造方法,定义队列的容量大小 public MyBlockingQueue(int capacity) { this.elems = new String[capacity]; } //入队列 public void put(String elem) { //判断容量满了没,满了就不能入队列,要阻塞等待 if(size >= this.elems.length) { //阻塞等待,先不写,先实现普通功能的队列 return; } //入队列 elems[tail] = elem; tail++; //因为是循环队列,所以要判断尾巴有没有超过容量大小下标,超过了就要从0开始了 if(tail > elems.length) { tail = 0; } //队列元素要++ size++; } //出队列 public String take() { String elem = null; //要判断队列是不是空的,空就不能出队列了,要阻塞等待 if(size == 0) { //阻塞等待,因为是先实现普通队列的功能,所以后面再补充 return null; } elem = elems[head]; head++; //因为是循环队列,所以要判断头结点有没有超过容量大小下标,超过了就要0开始了 if(head >= elems.length) { head = 0; } //出队列后,队列元素要-- size--; return elem; } }每个步骤说明代码中有注释。
测试一下可不可以用,如图:
是可以用的,这样,普通的队列就已经搞好了

(2)加上线程安全
我们想想put和take里面要给哪里上锁,首先,写操作肯定是要加锁的,因为多线程同时执行写操作,肯定是线程不安全的,也就是下面这段代码:
接下来,我们讨论一下这两个代码要不要加锁,以take为例,如图:
我们画一下图,会比较好理解:
如果size = -1,是不符合我们预期的,size最小也只可能是0,不可能是-1,所以我要上面的判断条件也要加锁。
而put也一样,判断条件也要加锁。
代码:
class MyBlockingQueue { Object locker = new Object(); private String elems[] = null; private int head = 0;//记录头结点 private int tail = 0;//记录尾结点 private int size = 0;//队列元素个数 //构造方法,定义队列的容量大小 public MyBlockingQueue(int capacity) { this.elems = new String[capacity]; } //入队列 public void put(String elem) { synchronized (locker) { //判断容量满了没,满了就不能入队列,要阻塞等待 if(size >= this.elems.length) { //阻塞等待,先不写,先实现普通功能的队列 return; } //因为这些都是写操作,也有读操作,多线程并发执行时,写操作是线程不安全的,要把这些打包成一个原子,加锁 synchronized (locker) { //入队列 elems[tail] = elem; tail++; //因为是循环队列,所以要判断尾巴有没有超过容量大小下标,超过了就要从0开始了 if(tail > elems.length) { tail = 0; } //队列元素要++ size++; } } } //出队列 public String take() { String elem = null; //因为这些都是写操作,也有读操作,多线程并发执行时,写操作是线程不安全的,要把这些打包成一个原子,加锁 synchronized (locker) { //要判断队列是不是空的,空就不能出队列了,要阻塞等待 if(size == 0) { //阻塞等待,因为是先实现普通队列的功能,所以后面再补充 return null; } elem = elems[head]; head++; //因为是循环队列,所以要判断头结点有没有超过容量大小下标,超过了就要0开始了 if(head >= elems.length) { head = 0; } //出队列后,队列元素要-- size--; return elem; } } }





(3)加上阻塞功能
我们要加上阻塞功能,就要在这两条件判断上加上wait,我们用locker的对象给他wait,而且wait必须要在synchronized内使用,这里的locker正好能对应上;当这个队列满时,就阻塞等待,等take方法拿走一个数据时,才给他唤醒。
加上阻塞功能后的代码如下:(不是最终代码,里面还是存在线程安全问题)
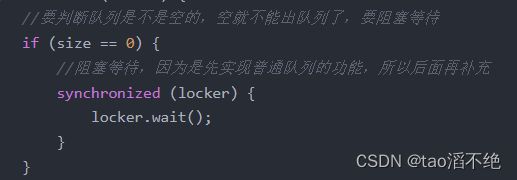
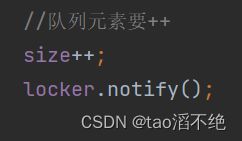
class MyBlockingQueue { Object locker = new Object(); private String elems[] = null; private int head = 0;//记录头结点 private int tail = 0;//记录尾结点 private int size = 0;//队列元素个数 //构造方法,定义队列的容量大小 public MyBlockingQueue(int capacity) { this.elems = new String[capacity]; } //入队列 public void put(String elem) throws InterruptedException { synchronized (locker) { //判断容量满了没,满了就不能入队列,要阻塞等待 if (size >= this.elems.length) { //阻塞等待,先不写,先实现普通功能的队列 synchronized (locker) { locker.wait(); } } //因为这些都是写操作,也有读操作,多线程并发执行时,写操作是线程不安全的,要把这些打包成一个原子,加锁 synchronized (locker) { //入队列 elems[tail] = elem; tail++; //因为是循环队列,所以要判断尾巴有没有超过容量大小下标,超过了就要从0开始了 if(tail > elems.length) { tail = 0; } //队列元素要++ size++; locker.notify(); } } } //出队列 public String take() throws InterruptedException { String elem = null; //因为这些都是写操作,也有读操作,多线程并发执行时,写操作是线程不安全的,要把这些打包成一个原子,加锁 synchronized (locker) { //要判断队列是不是空的,空就不能出队列了,要阻塞等待 if (size == 0) { //阻塞等待,因为是先实现普通队列的功能,所以后面再补充 synchronized (locker) { locker.wait(); } } elem = elems[head]; head++; //因为是循环队列,所以要判断头结点有没有超过容量大小下标,超过了就要0开始了 if(head >= elems.length) { head = 0; } //出队列后,队列元素要-- size--; locker.notify(); return elem; } } }加上阻塞功能的判断语句
与其对应的,一定要记住put和take后要notify,不然就会一直阻塞下去,导致程序动不了,如图:
现在进行代码分析:
当put时,队列满了,就要阻塞等待,等take这队列后,就会唤醒put操作,接着put就能入队列了;如果是take就相反,这是符合我们预期的。如果不满也不空时,每次put和take都会notify一次,这时会有影响吗?答案肯定是否定的,不会有影响,因为就算没有其他线程在等待,唤醒也没有事,不会对程序造成啥影响。而且我们现在的代码,一定是要么满,要么空,要么不满也不空。
但是,如果有两个线程同时put,现在队列是满的,A线程先阻塞,B线程也阻塞,这时有第三个线程take一次,把A线程的wait唤醒了,等A执行到下面的notify,A线程里put的notify就会唤醒B线程里的wait,但是因为A线程put了,和第三个线程的take一取一放抵消了,此时队列还是满的,因为A线程里的put把B线程里的wait唤醒了,这时已经是满了的队列还往里放元素,就造成了线程安全问题。
解决方案:把条件判断if换成while循环语句,不是只判断一次,当有其他线程把wait唤醒后,还要再判断一次这个队列是不是满的或者是空的,如果不是满的或者不是空的,才释放这个wait,不然就要继续wait,这样问题也就解决了。
最终代码:
class MyBlockingQueue { Object locker = new Object(); private String elems[] = null; private int head = 0;//记录头结点 private int tail = 0;//记录尾结点 private int size = 0;//队列元素个数 //构造方法,定义队列的容量大小 public MyBlockingQueue(int capacity) { this.elems = new String[capacity]; } //入队列 public void put(String elem) throws InterruptedException { synchronized (locker) { //判断容量满了没,满了就不能入队列,要阻塞等待 while (size >= this.elems.length) { //阻塞等待,先不写,先实现普通功能的队列 synchronized (locker) { locker.wait(); } } //因为这些都是写操作,也有读操作,多线程并发执行时,写操作是线程不安全的,要把这些打包成一个原子,加锁 synchronized (locker) { //入队列 elems[tail] = elem; tail++; //因为是循环队列,所以要判断尾巴有没有超过容量大小下标,超过了就要从0开始了 if(tail > elems.length) { tail = 0; } //队列元素要++ size++; locker.notify(); } } } //出队列 public String take() throws InterruptedException { String elem = null; //因为这些都是写操作,也有读操作,多线程并发执行时,写操作是线程不安全的,要把这些打包成一个原子,加锁 synchronized (locker) { //要判断队列是不是空的,空就不能出队列了,要阻塞等待 while (size == 0) { //阻塞等待,因为是先实现普通队列的功能,所以后面再补充 synchronized (locker) { locker.wait(); } } elem = elems[head]; head++; //因为是循环队列,所以要判断头结点有没有超过容量大小下标,超过了就要0开始了 if(head >= elems.length) { head = 0; } //出队列后,队列元素要-- size--; locker.notify(); return elem; } } }我们看看wait内部,可以看到它内部也是会有说明wait可能会提前被唤醒,就要我们多加一次判断,这样,用while会比用if更好,如图:



在实际开发中,生产者消费者模型,往往是多个生产者,多个消费者;这里的生产者和消费者往往不仅仅是一个线程,也可能是一个独立的服务器,甚至是一组服务器程序。
但生产者消费者模型,最核心的部分还是阻塞队列,可以使用synchronized和wait / notify 达到线程安全与阻塞。
3、运用阻塞队列的生产者消费者模型
简单的生产者消费者模型代码:
public class Test { public static void main(String[] args) { BlockingQueuequeue = new ArrayBlockingQueue<>(10); //生产者 Thread t1 = new Thread(() -> { int n = 1; while (true) { try { queue.put(n); System.out.println("生产者元素:" + n); n++; Thread.sleep(1000); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); //消费者 Thread t2 = new Thread(() -> { while (true) { try { int n = queue.take(); System.out.println("消费者元素:" + n); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); t1.start(); t2.start(); } } 执行结果:
可以看到生产者生产一个,消费者就消费一个,继续等待生产者生产元素后再消费。
