Java---Stream流技术(全网最详细)
流是Java 8 API添加的一个新的抽象,称为流Stream,以一种声明性方式处理数据集合(侧重对于源数据计算能力的封装,并且支持序列与并行两种操作方式)
Stream流是从支持数据处理操作的源生成的元素序列,源可以是数组、文件、集合、函数。流不是集合元素,它不是数据结构并不保存数据,它的主要目的在于计算
Stream流是对集合(Collection)对象功能的增强,与Lambda表达式结合,可以提高编程效率、间接性和程序可读性。
特点
1、代码简洁:函数式编程写出的代码简洁且意图明确,使用stream接口让你从此告别for循环
2、多核友好:Java函数式编程使得编写并行程序如此简单,就是调用一下方法
流程
1、将集合转换为Stream流(或者创建流)
2、操作Stream流(中间操作,终端操作)
stream流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果
接口继承关系
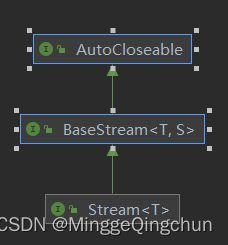
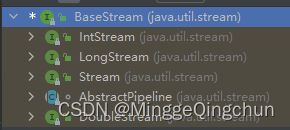
BaseStream:基础接口,声明了流管理的核心方法;
Stream:核心接口,声明了流操作的核心方法,其他接口为指定类型的适配
一、流创建操作
生成流的方式主要有五种
1、Stream创建
Stream stream1 = Stream.of(1,2,3,4,5); 2、Collection集合创建(应用中最常用的一种)
3、Array数组创建
int[] intArr = {1, 2, 3, 4, 5};
IntStream arrayStream = Arrays.stream(intArr);通过Arrays.stream方法生成流,并且该方法生成的流是数值流【即IntStream】而不是 Stream
注:
使用数值流可以避免计算过程中拆箱装箱,提高性能。
Stream API提供了mapToInt、mapToDouble、mapToLong三种方式将对象流【即Stream 】转换成对应的数值流,同时提供了boxed方法将数值流转换为对象流
4、文件创建
try {
Stream fileStream = Files.lines(Paths.get("data.txt"), Charset.defaultCharset());
} catch (IOException e) {
e.printStackTrace();
} 通过Files.line方法得到一个流,并且得到的每个流是给定文件中的一行
5、函数创建
iterator
Stream iterateStream = Stream.iterate(0, n -> n + 2).limit(5); iterate方法接受两个参数,第一个为初始化值,第二个为进行的函数操作,因为iterator生成的流为无限流,通过limit方法对流进行了截断,只生成5个偶数
generator
Stream generateStream = Stream.generate(Math::random).limit(5); generate方法接受一个参数,方法参数类型为Supplier ,由它为流提供值。generate生成的流也是无限流,因此通过limit对流进行了截断
二、操作符
流的操作类型主要分为两种:中间操作符、终端操作符
(一)中间操作符
通常对于Stream的中间操作,可以视为是源的查询,并且是懒惰式的设计,对于源数据进行的计算只有在需要时才会被执行,与数据库中视图的原理相似;
Stream流的强大之处便是在于提供了丰富的中间操作,相比集合或数组这类容器,极大的简化源数据的计算复杂度
一个流可以跟随零个或多个中间操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用
这类操作都是惰性化的,仅仅调用到这类方法,并没有真正开始流的遍历,真正的遍历需等到终端操作时,常见的中间操作有下面即将介绍的 filter、map 等
| 流方法 | 含义 | 示例 |
|---|---|---|
| filter | 用于通过设置的条件过滤出元素 | List strings = Arrays.asList(“abc”, “”, “bc”, “efg”, “abcd”,"", “jkl”); List filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList()); |
| map | 接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是“创建一个新版本”而不是去“修改”) | List strings = Arrays.asList(“abc”, “abc”, “bc”, “efg”, “abcd”,“jkl”, “jkl”); List mapped = strings.stream().map(str->str+"-IT").collect(Collectors.toList()); |
| distinct | 返回一个元素各异(根据流所生成元素的hashCode和equals方法实现)的流 | List numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);numbers.stream().filter(i -> i % 2 == 0).distinct().forEach(System.out::println); |
| sorted | 返回排序后的流 | List strings1 = Arrays.asList(“abc”, “abd”, “aba”, “efg”, “abcd”,“jkl”, “jkl”); List sorted1 = strings1.stream().sorted().collect(Collectors.toList()); |
| limit | 会返回一个不超过给定长度的流 | List strings = Arrays.asList(“abc”, “abc”, “bc”, “efg”, “abcd”,“jkl”, “jkl”); List limited = strings.stream().limit(3).collect(Collectors.toList()); |
| skip | 返回一个扔掉了前n个元素的流 | List strings = Arrays.asList(“abc”, “abc”, “bc”, “efg”, “abcd”,“jkl”, “jkl”); List skiped = strings.stream().skip(3).collect(Collectors.toList()); |
| flatMap | 使用flatMap方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。所有使用map(Arrays::stream)时生成的单个流都被合并起来,即扁平化为一个流 | List strings = Arrays.asList(“abc”, “abc”, “bc”, “efg”, “abcd”,“jkl”, “jkl”); Stream flatMap = strings.stream().flatMap(Java8StreamTest::getCharacterByString); |
| peek | 对元素进行遍历处理 | List strings = Arrays.asList(“abc”, “abc”, “bc”, “efg”, “abcd”,“jkl”, “jkl”); strings .stream().peek(str-> str + "a").forEach(System.out::println); |
public static void main(String[] args) {
List userList = getUserList();
}
private static List getUserList() {
List userList = new ArrayList<>();
userList.add(new User(1,"张三",18,"上海"));
userList.add(new User(2,"王五",16,"上海"));
userList.add(new User(3,"李四",20,"上海"));
userList.add(new User(4,"张雷",22,"北京"));
userList.add(new User(5,"张超",15,"深圳"));
userList.add(new User(6,"李雷",24,"北京"));
userList.add(new User(7,"王爷",21,"上海"));
userList.add(new User(8,"张三丰",18,"广州"));
userList.add(new User(9,"赵六",16,"广州"));
userList.add(new User(10,"赵无极",26,"深圳"));
return userList;
} 1、filter;过滤
用于通过设置的条件过滤出元素
//1、filter:输出ID大于6的user对象
List filetrUserList = userList.stream().filter(user -> user.getId() > 6).collect(Collectors.toList());
filetrUserList.forEach(System.out::println); 
2、map
接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是“创建一个新版本”而不是去“修改”)
//2、map
List mapUserList = userList.stream().map(user -> user.getName() + "用户").collect(Collectors.toList());
mapUserList.forEach(System.out::println); 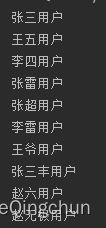
3、distinct:去重
返回一个元素各异(根据流所生成元素的hashCode和equals方法实现)的流
//3、distinct:去重
List distinctUsers = userList.stream().map(User::getCity).distinct().collect(Collectors.toList());
distinctUsers.forEach(System.out::println); 
4、sorted
返回排序后的流
//4、sorted:排序,根据名字倒序
userList.stream().sorted(Comparator.comparing(User::getName).reversed()).collect(Collectors.toList()).forEach(System.out::println);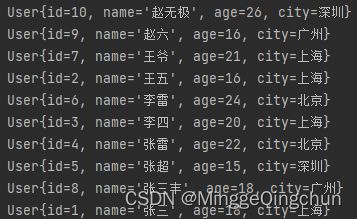
5、limit
会返回一个不超过给定长度的流
//5、limit:取前5条数据
userList.stream().limit(5).collect(Collectors.toList()).forEach(System.out::println);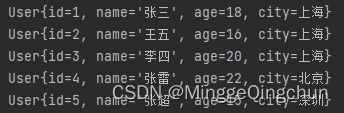
6、skip
返回一个扔掉了前n个元素的流
//6、skip:跳过第几条取后几条
userList.stream().skip(7).collect(Collectors.toList()).forEach(System.out::println);
7、flatMap
使用flatMap方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。所有使用map(Arrays::stream)时生成的单个流都被合并起来,即扁平化为一个流
//7、flatMap:数据拆分一对多映射
userList.stream().flatMap(user -> Arrays.stream(user.getCity().split(","))).forEach(System.out::println);map:对流中每一个元素进行处理
flatMap:流扁平化,让你把一个流中的“每个值”都换成另一个流,然后把所有的流连接起来成为一个流
本质区别:map是对一级元素进行操作,flatmap是对二级元素操作map返回一个值;flatmap返回一个流,多个值
应用场景:map对集合中每个元素加工,返回加工后结果;flatmap对集合中每个元素加工后,做扁平化处理后(拆分层级,放到同一层)然后返回
8、peek
对元素进行遍历处理
//8、peek:对元素进行遍历处理,每个用户ID加1输出
userList.stream().peek(user -> user.setId(user.getId()+1)).forEach(System.out::println);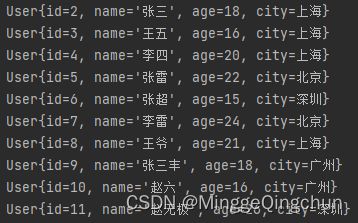
(二)终端操作符
Stream流执行完终端操作之后,无法再执行其他动作,否则会报状态异常,提示该流已经被执行操作或者被关闭,想要再次执行操作必须重新创建Stream流
一个流有且只能有一个终端操作,当这个操作执行后,流就被关闭了,无法再被操作,因此一个流只能被遍历一次,若想在遍历需要通过源数据在生成流。
终端操作的执行,才会真正开始流的遍历。如 count、collect 等
| 流方法 | 含义 | 示例 |
|---|---|---|
| collect | 收集器,将流转换为其他形式 | List strings = Arrays.asList(“cv”, “abd”, “aba”, “efg”, “abcd”,“jkl”, “jkl”); Set set = strings.stream().collect(Collectors.toSet()); List list = strings.stream().collect(Collectors.toList()); Map |
| forEach | 遍历流 | List strings = Arrays.asList(“cv”, “abd”, “aba”, “efg”, “abcd”,“jkl”, “jkl”);strings.stream().forEach(s -> out.println(s)); |
| findFirst | 返回第一个元素 | List strings = Arrays.asList(“cv”, “abd”, “aba”, “efg”, “abcd”,“jkl”, “jkl”); Optional first = strings.stream().findFirst(); |
| findAny | 将返回当前流中的任意元素 | List strings = Arrays.asList(“cv”, “abd”, “aba”, “efg”, “abcd”,“jkl”, “jkl”); Optional any = strings.stream().findAny(); |
| count | 返回流中元素总数 | List strings = Arrays.asList(“cv”, “abd”, “aba”, “efg”, “abcd”,“jkl”, “jkl”); long count = strings.stream().count(); |
| sum | 求和 | int sum = userList.stream().mapToInt(User::getId).sum(); |
| max | 最大值 | int max = userList.stream().max(Comparator.comparingInt(User::getId)).get().getId(); |
| min | 最小值 | int min = userList.stream().min(Comparator.comparingInt(User::getId)).get().getId(); |
| anyMatch | 检查是否至少匹配一个元素,返回boolean | List strings = Arrays.asList(“abc”, “abd”, “aba”, “efg”, “abcd”,“jkl”, “jkl”); boolean b = strings.stream().anyMatch(s -> s == “abc”); |
| allMatch | 检查是否匹配所有元素,返回boolean | List strings = Arrays.asList(“abc”, “abd”, “aba”, “efg”, “abcd”,“jkl”, “jkl”); boolean b = strings.stream().allMatch(s -> s == “abc”); |
| noneMatch | 检查是否没有匹配所有元素,返回boolean | List strings = Arrays.asList(“abc”, “abd”, “aba”, “efg”, “abcd”,“jkl”, “jkl”); boolean b = strings.stream().noneMatch(s -> s == “abc”); |
| reduce | 可以将流中元素反复结合起来,得到一个值 | List strings = Arrays.asList(“cv”, “abd”, “aba”, “efg”, “abcd”,“jkl”, “jkl”); Optional reduce = strings.stream().reduce((acc,item) -> {return acc+item;});if(reduce.isPresent())out.println(reduce.get()); |
1、collect
收集器,将流转换为其他形式
//1、collect:收集器,将流转换为其他形式
Set set = userList.stream().collect(Collectors.toSet());
set.forEach(System.out::println);
System.out.println("--------------------------");
List list = userList.stream().collect(Collectors.toList());
list.forEach(System.out::println);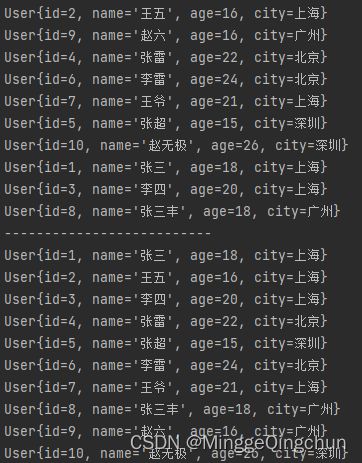
2、forEach
遍历流
//2、forEach:遍历流
userList.stream().forEach(user -> System.out.println(user));
userList.stream().filter(user -> "上海".equals(user.getCity())).forEach(System.out::println);3、findFirst
返回第一个元素
//3、findFirst:返回第一个元素
User firstUser = userList.stream().findFirst().get();
User firstUser1 = userList.stream().filter(user -> "上海".equals(user.getCity())).findFirst().get();
4、findAny
将返回当前流中的任意元素
//4、findAny:将返回当前流中的任意元素
User findUser = userList.stream().findAny().get();
User findUser1 = userList.stream().filter(user -> "上海".equals(user.getCity())).findAny().get();

5、count
返回流中元素总数
//5、count:返回流中元素总数
long count = userList.stream().filter(user -> user.getAge() > 20).count();
System.out.println(count);6、sum
求和
//6、sum:求和
int sum = userList.stream().mapToInt(User::getId).sum();7、max
最大值
//7、max:最大值
int max = userList.stream().max(Comparator.comparingInt(User::getId)).get().getId();8、min
最小值
//8、min:最小值
int min = userList.stream().min(Comparator.comparingInt(User::getId)).get().getId();9、anyMatch
检查是否至少匹配一个元素,返回boolean
//9、anyMatch:检查是否至少匹配一个元素
boolean matchAny = userList.stream().anyMatch(user -> "北京".equals(user.getCity()));10、allMatch
检查是否匹配所有元素,返回boolean
//10、allMatch:检查是否匹配所有元素
boolean matchAll = userList.stream().allMatch(user -> "北京".equals(user.getCity()));11、noneMatch
检查是否没有匹配所有元素,返回boolean
//11、noneMatch:检查是否没有匹配所有元素,返回boolean
boolean nonaMatch = userList.stream().allMatch(user -> "云南".equals(user.getCity()));12、reduce
可以将流中元素反复结合起来,得到一个值
//12、reduce:将流中元素反复结合起来,得到一个值
Optional reduce = userList.stream().reduce((user, user2) -> {
return user;
});
if(reduce.isPresent()) System.out.println(reduce.get());三、Collect收集
Collector:结果收集策略的核心接口,具备将指定元素累加存放到结果容器中的能力;并在Collectors工具中提供了Collector接口的实现类
1、toList
将用户ID存放到List集合中
List idList = userList.stream().map(User::getId).collect(Collectors.toList()) ;
2、toMap
将用户ID和Name以Key-Value形式存放到Map集合中
Map userMap = userList.stream().collect(Collectors.toMap(User::getId,User::getName));
3、toSet
将用户所在城市存放到Set集合中
Set citySet = userList.stream().map(User::getCity).collect(Collectors.toSet());
4、counting
符合条件的用户总数
long count = userList.stream().filter(user -> user.getId()>1).collect(Collectors.counting());
5、summingInt
对结果元素即用户ID求和
Integer sumInt = userList.stream().filter(user -> user.getId()>2).collect(Collectors.summingInt(User::getId)) ;
6、minBy
筛选元素中ID最小的用户
User maxId = userList.stream().collect(Collectors.minBy(Comparator.comparingInt(User::getId))).get() ;
7、joining
将用户所在城市,以指定分隔符链接成字符串;
String joinCity = userList.stream().map(User::getCity).collect(Collectors.joining("||"));
8、groupingBy
按条件分组,以城市对用户进行分组;
Map> groupCity = userList.stream().collect(Collectors.groupingBy(User::getCity)); 1、orElse(null)
/**
* Return the value if present, otherwise return {@code other}.
*
* @param other the value to be returned if there is no value present, may
* be null
* @return the value, if present, otherwise {@code other}
* 返回值,如果存在,否则返回其他
*/
public T orElse(T other) {
return value != null ? value : other;
}表示如果一个都没找到返回null(orElse()中可以塞默认值。如果找不到就会返回orElse中设置的默认值)
2、orElseGet(null)
/**
* Return the value if present, otherwise invoke {@code other} and return
* the result of that invocation.
*
* @param other a {@code Supplier} whose result is returned if no value
* is present
* @return the value if present otherwise the result of {@code other.get()}
* @throws NullPointerException if value is not present and {@code other} is
* null
* 返回值如果存在,否则调用其他值并返回该调用的结果
*/
public T orElseGet(Supplier other) {
return value != null ? value : other.get();
}表示如果一个都没找到返回null(orElseGet()中可以塞默认值。如果找不到就会返回orElseGet中设置的默认值)
orElse() 接受类型T的 任何参数,而orElseGet()接受类型为Supplier的函数接口,该接口返回类型为T的对象
orElse(null)和orElseGet(null)区别:
1、当返回Optional的值是空值null时,无论orElse还是orElseGet都会执行
2、而当返回的Optional有值时,orElse会执行,而orElseGet不会执行
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
public class TestStream {
public static void main(String[] args) {
List list = new ArrayList<>();
//定义三个用户对象
User user1 = new User();
user1.setUserName("admin");
user1.setAge(16);
user1.setSex("男");
User user2 = new User();
user2.setUserName("root");
user2.setAge(20);
user2.setSex("女");
User user3 = new User();
user3.setUserName("admin");
user3.setAge(18);
user3.setSex("男");
User user4 = new User();
user4.setUserName("admin11");
user4.setAge(22);
user4.setSex("女");
//添加用户到集合中
list.add(user1);
list.add(user2);
list.add(user3);
list.add(user4);
/*
在集合中查询用户名包含admin的集合
*/
List userList = list.stream().filter(user -> user.getUserName().contains("admin")
&& user.getAge() <= 20).collect(Collectors.toList());
System.out.println(userList);
/*
在集合中查询出第一个用户名为admin的用户
*/
Optional user = list.stream().filter(userTemp -> "admin".equals(userTemp.getUserName())).findFirst();
System.out.println(user);
/*
orElse(null)表示如果一个都没找到返回null(orElse()中可以塞默认值。如果找不到就会返回orElse中设置的默认值)
orElseGet(null)表示如果一个都没找到返回null(orElseGet()中可以塞默认值。如果找不到就会返回orElseGet中设置的默认值)
orElse()和orElseGet()区别:在使用方法时,即使没有值 也会执行 orElse 内的方法, 而 orElseGet则不会
*/
//没值
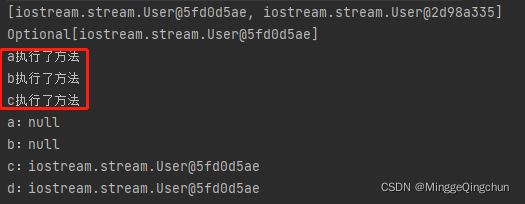
User a = list.stream().filter(userT-> userT.getAge() == 12).findFirst().orElse(getMethod("a"));
User b = list.stream().filter(userT11-> userT11.getAge() == 12).findFirst().orElseGet(()->getMethod("b"));
//有值
User c = list.stream().filter(userT2-> userT2.getAge() == 16).findFirst().orElse(getMethod("c"));
User d = list.stream().filter(userT22-> userT22.getAge() == 16).findFirst().orElseGet(()->getMethod("d"));
System.out.println("a:"+a);
System.out.println("b:"+b);
System.out.println("c:"+c);
System.out.println("d:"+d);
}
public static User getMethod(String name){
System.out.println(name + "执行了方法");
return null;
}
} 
参考链接
Java 8 Stream | 菜鸟教程
Java基础|Stream流原理与用法总结
Java中的Stream流详解_DJL_DJL_DJL的博客-CSDN博客_java中streamS