计算机视觉(P2)-计算机视觉任务和应用
一、说明
在本文中,我们将探讨主要的计算机视觉任务以及每个任务最流行的应用程序。
二、图像内容分类
2.1. 图像分类
图像分类是计算机视觉领域的主要任务之一[1]。在该任务中,经过训练的模型根据预定义的类集为图像分配特定的类。下图是著名的CIFAR-10数据集[1],它由十个类别的8000万张图像组成。在图像分类任务中,训练模型将输入图像分配给预定义的十个类别之一,如下图所示。

计算机以像素的形式分析图像。它通过将图像视为矩阵数组来实现这一点,矩阵的大小取决于图像分辨率。简而言之,从计算机的角度来看,图像分类就是使用算法对这些统计数据进行分析。在数字图像处理中,图像分类是通过自动将像素分组到指定的类别(即所谓的类)中来完成的。该算法将图像分为一系列最突出的特征,从而降低了最终分类器的工作量。这些特征使分类器了解图像代表什么以及它可能被视为哪个类别。特征提取过程是图像分类中最重要的步骤,因为其余步骤都依赖于它。
2.2 图像分类应用:
图像分类有很多实际应用[1]。
- 自动检测和质量控制:图像分类可用于自动检测装配线上的产品并识别不符合质量标准的产品。

- 皮肤癌的分类:图像分类在医疗保健领域的另一个应用是自动将皮肤图像分类为恶性和开始[1]。

- 土地利用制图:图像分类可用于自动绘制土地利用图并识别不同的土地类型。
- 安全和医学成像:最后,两个以上的监视是一个大问题。这种能够监控环境以确保人群安全的想法有多种原因。

- 这些是从西门子销售的用于进行港口监控的系统中截取的屏幕截图。只是为了知道是否有人在闲逛,或者车辆是否正在接近。这也是计算机视觉。对拥有计算机视觉的个人更直接的影响是医学成像方面的工作。好的,你看一个例子。有各种各样的 3D 成像、MRI、CAT 扫描,诸如此类的东西,但在这里你可以看到一些工作。这是不久前来自麻省理工学院的 Eric Grimson 实验室的,在屏幕上,计算机视觉系统正在记录头骨,它是桌子上有一个通过 3D 成像创建的模型。所以,当外科医生看着这个显示器时,他看到的是真人,顺便说一句,如果这里有手术刀,他会看到拿着手术刀或钻头或任何你用来打洞的手在人的头脑中。你想看到的各种结构都在下面,这也是计算机视觉。

三、物体识别
如前所述,图像分类的工作原理是从预定义的一组标签中为图片分配类别或标签,对象识别则识别该类别的特定实例。比如图像分类任务,重点是对人脸图片进行分类,物体识别任务,重点是对人进行识别并识别。因此,目标检测可以看作是一种聚类算法,用于将相似的实例彼此聚类[1]。
3.1 物体检测和定位
有时我们还需要提取图像中存在的物体的位置。这时我们可以使用对象检测,这是另一个众所周知且有用的计算机视觉任务 [2]

在这里,系统不仅提供标签,还为您提供边界框坐标,以告诉您对象在图像中的确切位置。

内容识别的另一个重要任务是对象检测。对象检测是检测图像中特定类别的对象实例的任务。对象检测通常是进一步计算之前的初步任务,例如在面部识别中,您必须首先检测面部并在识别之前对其进行裁剪 [1]。

分类系统及其变体有许多工业用例。一个流行的应用程序是面部识别。计算机程序可以通过分析图像中的人脸来识别和识别他们。从员工考勤到解锁手机,面部识别几乎无处不在。[2]

Facebook 甚至使用它来标记人员,它可以识别上传的图像/视频中的人员,并自动建议标记他们(如果他们在您共同的朋友中),等等 [2]。

如今另一件非常常见的事情是人脸检测。几乎您今天购买的任何数码相机,您拿起它,使用默认设置,它都会找到面孔。所以,这是一个例子。顺便说一句,最酷的事情之一是未来的一系列讲座,我们将讨论基本上正是这样做的技术。所以下一次,当我们谈到这些时,你拿起相机,它会找到面孔。你会说,哦,我知道他们是怎么做的。但实际上现在,相机可以做更多的事情。我想左边的那个,我想是来自网络,来自斐济,如果你给某人拍一张照片,他们会眨眼。你知道,这真的很烦人,它会告诉你他们眨眼了。也许更有趣的是,索尼有一种叫做“微笑快门”的东西,它可以监视人们。你按下它,然后说,现在拍一张照片。但实际上它会等到你,它看到那个人微笑。更进一步,如今,有些相机可以识别你是谁。这是从基于摄像头登录的镜头中截取的屏幕。所以它知道一群不同的人。你走到电脑前,你说,哟,电脑是我。其实你什么都不用说,电脑就会说,是你。它会让你登录。这就是人脸识别。我们还将稍微讨论一下人脸识别。尽管人脸检测技术属于技术范畴,但该技术对于该课程来说是更为基础的技术 [2]。

3.2 物体检测应用:
物体检测是现实生活中最常用的计算机视觉应用之一。它已在大多数领域得到应用,例如[1]:
- 安全和监控中的危险检测:视频监控中的广泛安全应用都基于对象检测,例如,检测受限或危险区域中的人员、预防自杀或利用计算机视觉在远程位置自动执行检查任务。
- 运输和物流领域的人工智能车辆检测:物体检测用于检测和统计车辆以进行交通分析或检测停在危险区域(例如十字路口或高速公路)的汽车。
- 医疗保健领域的医疗特征检测:对象检测帮助医疗保健领域取得了许多突破。由于医学诊断在很大程度上依赖于图像、扫描和照片的研究,因此涉及 CT 和 MRI 扫描的对象检测对于诊断疾病变得非常有用,例如,使用 ML 算法进行肿瘤检测。
- 自动驾驶汽车依靠对象检测技术来确定人、交通标志等对象的位置。如果有对象接近或太靠近,该信息会告诉汽车停下来。[2]

- 这家公司,Evolution Robotics,开发了一种叫做 Lane Hawk 的东西,它基本上阻止了你们中的一些人。你们都没有。将东西放在篮子底部,然后将其推出,却忘记向收银员提及它在那里。这其实是一个很大的问题。至于系统,你可以在这里看到相机[2]。

- 是的,看,下面有一个摄像机,正在看这个。我想知道我们是否必须抹去那是啤酒。是的,你看,现在没人能看到了。好吧,你不知道那是什么。好的。它可以检测到那是什么,这不仅很酷。但如果你访问他们的网站,他们会告诉你五年后,该产品被另一家公司购买了。所以,计算机视觉是可以赚钱的。去做一个非常酷的创业公司。物体识别过去需要大量的计算能力[2]。

- 就是,计算能力变小了。它使我们现在能够以更小的封装进行操作。所以,这就是移动设备的增强现实和物体识别的整个领域。所以,这是一个系统,你可以向它展示这座雕像的图片。它可以识别这是谁以及纪念碑是什么。这是诺基亚的旧图片,您实际上可以在其中访问网络,提取信息并将其显示给您。所以有一段时间我们一直在谈论在智能手机上做到这一点,现在它就在你的脸上了。我是萨德·斯塔纳教授,也是佐治亚理工学院的教授。他在谷歌眼镜的开发中发挥了重要作用。眼镜所做的一件事就是让你有一个摄像头来观察你所看到的东西。并且可以通过相同的对象识别方法为您提供有关您正在查看的内容的信息。这也是计算机视觉的一部分[2]。

- 智能汽车:
您知道,最近真正蓬勃发展的另一个领域是计算机视觉在汽车中的应用。这是一个网站,网页图片取自 Mobileye,这是一家以色列公司。他们开发了与汽车相关的各种使用计算机视觉的技术。从自动识别标志到(这里有点难以看到)红色轮廓,一切应有尽有。系统会自动识别行人所在位置。他们有一个系统,如果行人靠近而你似乎走得太快,它会提醒你。您还可以构建制动或减速等系统。但我们的想法是,计算机视觉确实已经进入了智能汽车领域。

事实上,智能汽车就在这里。你们中有些人知道,这辆车就是斯坦利。斯坦利就是斯坦福大学。就是那个红色的小S。参加 DARPA 举办的城市大挑战赛。它是由. 斯坦利是由这个人管理的。他叫什么名字?哦,是的,特伦什么的,我不认识塞巴斯蒂安。他也是 Udacity 的创始人。他是那种缺乏成就感、没有野心的人。他们赢了。然后是塞巴斯蒂安,因为他就在那里,

说服谷歌参与汽车制造过程。自动驾驶汽车,大多数人都听说过。这是在高速公路上拍摄的照片。这些东西今天在这里的真正标志是。各州现在开始通过立法,帮助详细说明如果在特定道路上发生事故并且是自动驾驶汽车,谁应该承担责任。所以这就是技术开始影响政策和经济的地方,那时你就知道它是真实的

四、 对象和实例分割
图像分割是一种将数字图像划分为称为图像片段的子组的方法,从而降低图像的复杂性并能够对每个图像片段进行进一步处理或分析。从技术上讲,分割是将标签分配给像素以识别图像中的对象、人物或其他重要元素。在下图中,图像被分割,每个实例都会被赋予一定的颜色,如图[1]所示:

4.1 对象和实例分割应用程序
图像分割是计算机视觉技术和算法的关键组成部分。它用于许多实际应用,包括医学图像分析、自动驾驶车辆的计算机视觉、人脸识别和检测、视频监控和卫星图像分析[1]。
五、姿势估计
根据目标任务的不同,姿势估计可以具有不同的含义。对于刚性物体,通常意味着在 3D 空间中估计物体相对于相机的位置和方向。这对于机器人特别有用,以便它们可以与环境交互(物体拾取、避免碰撞等)。它也经常用于增强现实中,将 3D 信息叠加在对象之上 [1]

对于非刚性元素,位姿估计也可以意味着其子部分相对于彼此的位置的估计。更具体地说,当将人类视为非刚性目标时,典型的应用是识别人类姿势(站立、坐着、跑步等)或理解手语[1]。
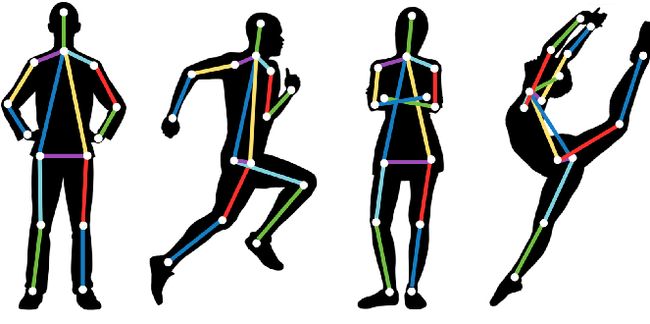
。
六、- OCR(光学字符识别)
有趣的问题是,现在计算机视觉的最新技术是什么?人们用计算机视觉做了哪些事情?这与人类的视觉方式相比如何?这是一个简单的例子,实际上过去被认为是困难的,但现在实际上是相当标准的。那么我们来谈谈简单的光学字符识别。这是一些车牌读取器的示例。而且车牌更容易一些,因为有固定的字体。事实上,不久前进行 OCR 还被认为是非常困难的。如今,如果您有扫描仪,或者如果您有 Adobe Acrobat,它就会内置 OCR。因为它无处不在且简单易用。更具挑战性的是,你们中的许多人可能已经开始使用自动柜员机。您可以在那里存入带有手写数字(金额)的银行支票。而且,很长一段时间以来,邮局一直在使用机器识别邮政编码。再次,在手写信封上。这是计算机视觉提取含义的一个例子。那里的数字是多少?[2]。


七、 视频分析
计算机视觉算法不仅应用于单个图像,还应用于视频。有些任务需要将视频的图像序列作为一个整体来考虑,以便考虑时间和空间的一致性。我们将探索最著名的视频计算机视觉任务和应用[1]。
7.1 物体追踪
对象跟踪是计算机能够检测、理解和关注图像或视频流中的对象的过程。它是人工智能 (AI) 和机器学习 (ML) 最广泛的应用之一,使您的视觉数据处理需求能够实现最大程度的自动化和简化。底层的深度学习算法从我们的生物神经系统中汲取灵感,形成了一个分层而复杂的数据传输和学习能力网络[1]。
对象跟踪解决方案使我们能够对通过不同类型的相机获得的视觉数据执行有意义的操作。使用合适的对象检测算法与跟踪模型相结合,您可以训练机器不仅识别特定图像中的一个或多个独特的对象或人,还可以在后续帧中识别它们并跟踪它们在视频流中的轨迹 [1]。
物体跟踪的应用
- 监控用例:借助能够实时跟踪视频中对象的复杂算法,企业可以显着增强其安全部门[1]。
- 零售市场:物体追踪在零售行业的一个极具创新性的实际应用可以在Amazon Go商店中看到。亚马逊融合了各种计算机视觉和人工智能流程,为其超市引入了无收银员结账系统:
- 自动驾驶:自动驾驶汽车可能是人工智能驱动的物体检测和跟踪最著名的应用。由于您必须跟踪道路和周围的物体,因此物体检测对于该行业的进步非常重要[1]。
八、动作识别
动作识别是识别图像或视频中的人何时执行给定动作的任务。它属于只能在图像序列上执行的任务列表。这与我们无法仅从一个单词理解一个句子,我们也无法从一张图像识别动作非常相似。计算机视觉算法可以经过训练来识别各种动作,从跑步、睡觉到喝酒、跌倒或骑自行车 [1]。
动作识别的应用:
- 监控:动作识别的应用领域之一是监控行业,例如检测可疑或异常行为
- 人机交互:动作识别的另一个应用领域是人机交互,例如手势控制设备。
九、运动估计
运动估计检查图像序列中对象的运动,以尝试获得表示估计运动的矢量。这对于专注于估计视频中捕获的实际速度或轨迹的应用程序非常重要。
运动估计在不同行业中非常有用,例如交通管理以估计汽车的速度,并且在娱乐行业中捕捉运动以对其应用视觉效果或在电视流或广播上叠加 3D 信息。
十、内容感知图像编辑
计算机视觉算法不仅用于分析图像的内容(如前所示),还用于提高图像的质量和内容。如今,基本的图像处理和增强工具(例如使用更智能的方法进行过滤)使用图像内容的先验知识来提高图像的视觉质量。例如,如果训练模型了解鸟类通常的样子,那么它可以应用这些知识,用鸟类图片中的连贯像素替换噪声像素。这个概念可以应用于图像恢复或分辨率增强。下图显示了使用 Nividia 内容感知填充工具恢复的像素[1].a

十一、场景重建
场景重建是根据对象的图片或扫描重建现实世界对象的 3D 数字版本的过程。这是一个非常复杂的问题,有大量的研究历史、悬而未决的问题和可能的解决方案。在此过程中,来自不同视点的场景的两个图像之间的对应关系可以推导出每个可视化元素的距离。更先进的方法采用多张图像并将其内容匹配在一起,以获得目标场景的 3D 模型 [1]。

应用
特效和 3D 建模:人们对计算机视觉的一个领域知之甚少。它在特效中被大量使用,从捕捉某人的形状到扫描某人的脸部,无论是激光还是其他方式。你建立模型,然后你可以制作很多这样的人,你可以从不同侧面和不同方向照亮他们,因为你有一个完整的 3D 模型。
同样,动作捕捉,所以如果你看《加勒比海盗》,那个脸上有各种奇怪东西的人,当然,你知道,这都是 CGI,但问题是,他们怎么知道他的脸和所有东西到底该放在哪里?嗯,这些相机正在跟踪佩戴的这些标记。他们必须弄清楚三维几何形状,这也是计算机视觉的一种形式。

另一个区域已经成为,但这实际上是来自谷歌地球的镜头,这是来自微软的虚拟地球。谷歌地球是它的另一个版本。基本上,他们可以拍摄图像,所以这里是图像,航空图像。而且,他们还可以用它来找出建筑物的模型。把这些三维模型放在那里,然后你就可以随心所欲地围绕它们飞行。这是一种使用大量图像、序列来恢复三维结构的运动方法的结构。我们只会稍微讨论一下这个问题。我们将主要关注几张图像。
十二、游戏
5.1-基于视觉的交互
最近真正发生变化的另一件事是将计算机视觉推向视频游戏。因此,任天堂 Wii 是最先做到这一点的地方之一。遥控器实际上内置了一个摄像头系统,可以跟踪传感器条上的两个点并报告该信息。

但就计算机视觉参与游戏而言,真正的游戏规则改变者是 Microsoft Kinect。Microsoft Kinect是一种深度传感器。我的意思是它可以产生这样一个场景,也就是说它可以,它可以从一个场景中产生这样一个图像。

这是深度图像,对吧?所以距离越远,颜色越暗。而且越亮越近。灰色介于两者之间。
所以从技术角度来说。从原始技术的角度来看,大多数人认为 Kinect 的重要之处在于它创建了深度图像。
Kinect 的重要之处在于它可以生成骨骼描述。微软的人员将机器学习技术应用于计算机视觉,而这来自英国的微软剑桥。能够从深度图像中恢复人的骨骼几何形状。顺便说一下,他们是立即完成的。每一帧,他们的做法都不同。他们甚至不跟踪它,他们只是一次一帧地进行。就是这么坚固。

正确的?因为他们可以获得骨架信息,所以您可以构建非常酷的用户界面。所以你可以知道,做驾驶游戏,然后像这样驾驶你的车。
当然,更有趣的是和机器人一起玩。你看,这是西蒙,在佐治亚理工学院安德里亚·托马斯的实验室。西蒙之所以向这个学生挥手,是因为在西蒙身后,有一个 Kinect 正在看着那个挥手的学生。并正在获取深度信息。然后,骨架信息会根据人类正在做什么来解释骨架信息。而这反过来又允许机器人决定机器人想要做什么。
因此,尽管 Kinect 是作为一种影响游戏的方式而被推广和发明的。早期,微软对于是否要开放该系统并让人们使用它存在一些不确定性。他们很快意识到这是每个人都想使用的东西。它确实彻底改变了人们对深度成像以及计算机视觉应用于深度图像的思考方式。
请关注课程教学以查看此故事的最新更新
如果您想了解有关这些主题的更多信息:Python、机器学习数据科学、机器学习统计、机器学习线性代数计算机视觉和研究
然后登录并注册Courseseach以获取数据字段中的精彩内容。
请继续关注我们即将发表的文章,我们将更详细地探讨与计算机视觉相关的特定主题!
请记住,学习是一个持续的过程。因此,继续学习,继续创造并与他人分享!✌️
参考
1-计算机视觉任务和应用概述
2-计算机视觉简介
3-什么是计算机视觉 — 一个非常简单的解释(第 2 集 | CVFE)