IO流体系
输入流/输出流之间方法等都是相同的只是在进行读取的时候,读取的结构不同。
输入:从文件/磁盘/网络等写入(运行)内存。
输出:从(运行)内存等写入文件/磁盘/网络等
入门:Stream流
是jdk8开始新增的一套API可以用来操作集合或者数组的数据
优势:Stream流大量的集合了Lambda的语法风格来编程,提供了一种更加强大,操作更简单的集合或者数据的方法,代码更简洁
流只能够收集一次。

使用步骤:
可以直接进行创建Stream流对象:格式:Stream<数据类型> 标识符=Stream.of(储存的数据);
或者:

数据源(集合或者数据)
获取Stream流:代表一条流水线并能够和数据源建立连接
在其后调用Stream提供的方法对数组/集合进行处理,计算。 支持链式
获取处理结果:可以进行返回数据,遍历,统计,将其收集在一个新的容器中返回。
获取Stream流:




Stream流的常用中间方法:
中间方法指:在调用完成后会返回新的Stream流,但是可以继续使用处理(即支持链式编程)

//distinct去重复性,只能处理提供的官方数据类型的,如果需要处理自定义对象(认为内容一样就重复,则需要
在自定义对象类中重写equals和hashCode方法)
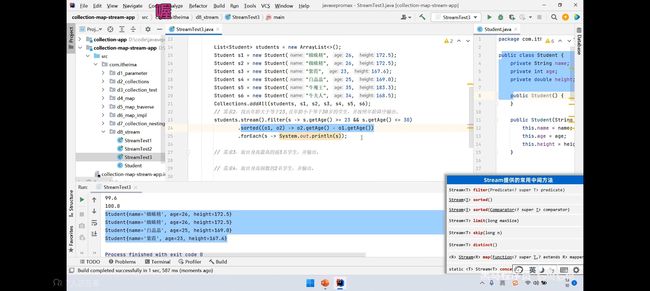
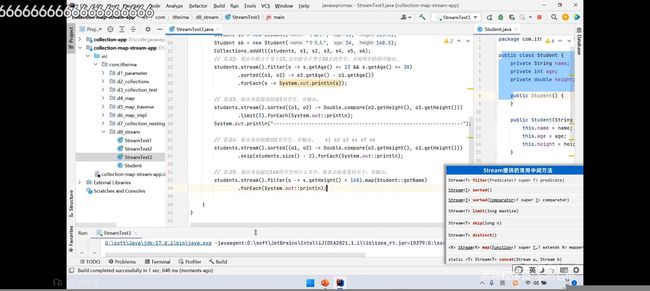
//一般来说需要合并的流类型应该相同如果不同则接收的流的数据类型应要能同时接受两种该数据类型。
Strem流常见的终结方法:
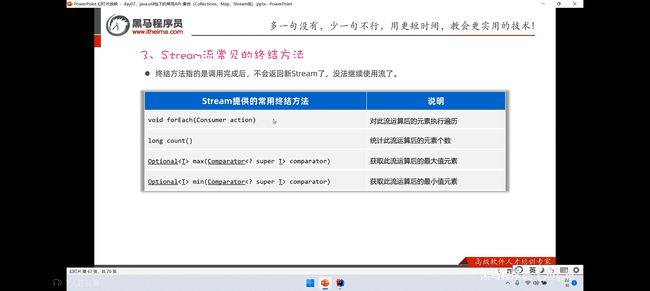
是由于在其使用后不会再返回新的Stream流
再max/min方法中的括号内指的是需要借用Coparator创建比较方式,可以进行新特性来进行简化。
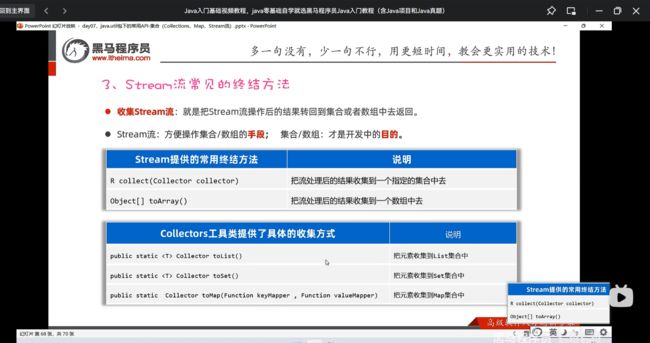
收集Stream流来结束:
IO流的浅入:
所有的流,在使用后如果没有进行终结,都需要用close()方法来释放资源。
流的关闭过程即相当于包括(刷新流)
前置:
此处为语雀内容卡片,点击链接查看:
I:Input,称为输入流:负责把数据(磁盘/网络)读到内存中
O:Ootput,称为输出流:负责把(内存/程序)数据写出去到(硬盘)/网络
文件的复制等,发信息也是IO流来实现的
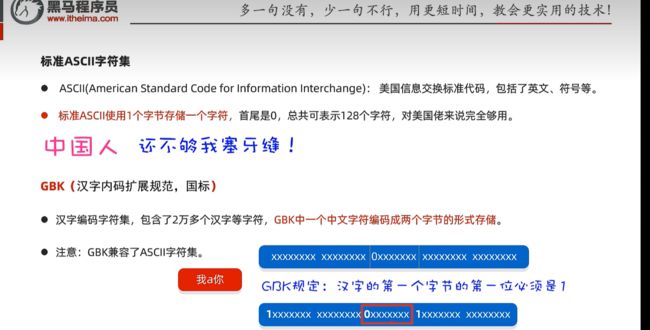
标准的字符集:
使用一个字节进行储存
首位都是0
GBK(我国自己的字符集):
汉字是使用两个字节进行储存的,汉字的第一个字节的第一位必须是1
GBK兼职了ACSII中的基本符号
Unicode(国际统一的字符集):但并不被所有接受,字节越多内存越大
UTF-8:是Unicode字符集的进化(分为1,2,3,4个字节区)
是可变长编码
英文,数字占一个字节;汉字占3个字节
在进行解码使用的时候会先进行匹配需要的字符集,选取对应的字节数

之后在进行解码时选对对应的字节段作为一个符号

字符集的解码和编码:
编码:将字符变为字节
解码:将字节变为字符


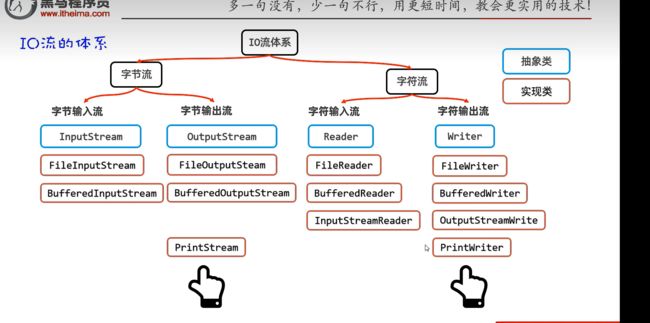
IO流的分类:

结合可以分为四个基本的流:字节输入流,字节输出流,字符输入流,字符输出流
IO流体系:

蓝色都是抽象类是其中一个代表
红色是他们的一个实现类
所有的流,在使用后如果没有进行终结,都需要用close()方法来释放资源。
以内存为基准,将磁盘的文件以字节的形式读取到内存中,文件读取是逐渐往后的,每次进行一次就会往后(类似迭代器,是一次性的)
- getBytes(String charsetName): 使用指定的字符集将字符串编码为 byte 序列,并将结果存储到一个新的 byte 数组中。
- getBytes(): 使用平台的默认字符集将字符串编码为 byte 序列,并将结果存储到一个新的 byte 数组中。
("")可以进行指定编码类型
- String 提供的
字节流:
字节流适合文件,文本的传输。
文件字节输入流:输入到运行内存中

每次读取一个字节:read()
读取汉字时会乱码(读取的是一个字节)
1.用FileInputStream创建接通文件的通道
创建文件字节输入流管道,与源文件接通。
// InputStream is = new FileInputStream(new File( "文件路径"));
//简化写法:推荐使用。
InputStream is = new FileInputStream(("文件路径"));
2.开始读取文件的字节数据。
// public int read(): 每次读取一个字节返回,返回的是ASCII码,如果需要返回字符需要转义为char(或使用String进行解码), 如果没有数据了, 返回-1.(如果数据是负数则会返回符号的ASCII和该数字的ASCII)
int b1 = is.read(); System. out . print1n((char)b1);
int b2 = is.read(); System. out. printLn((char) b2);
int b3 = is.read(); System. out. printLn(b3);
在经过循环设置后可以多次读取:
如果没有数据了, 返回-1.(如果数据是负数则会返回符号的ASCII和该数字的ASCII)

(但读取时还是较慢(实质仍是一个字节进行读取))
每次读取多个字节:read(byte[] buffer)
该方法也不能避免汉字读取时乱码
每次进行读取字节数组时会返回每次读取的字节数。(使用通道的read读取该字节数组buffer(字节数组的标识符)),此时在进行后字节数据会储存转载数组中
package ex0000;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class ex000000000 {
public static void main(String[] args) throws IOException {
InputStream ex0 = new FileInputStream("src/sss");
byte[] ex = new byte[3];
int a1 = ex0.read(ex);
//每次读取的返回值是读取的字节数
String s1 = new String(ex);
String s2 = new String(ex,0,2);
//将字节转换为字符串,相当于解码,也可以将其用char将ASCII转码(但由于是数组需要先获取每个元素才可进行)
System.out.println(s1);//输出解码值
System.out.println(s2);//输出指定索引解码值
System.out.println(a1);//输出解码的字节数
int a2 = ex0.read(ex);//第二次获取
String s3 = new String(ex);//第二次解码
System.out.println(a2);
System.out.println(s3);//由于剩余字节数少于(不是一个没有)所能一次获取的字节数(获取时字节数组相当于替换过程),但实际上理解为多层蛋糕,上层露出更好,未能"替换"的字节还会按照上一次获取的数据进行输出
} 如果是一个没有,则会返回-1
}
当每次使用同一个字节数组(桶)来进行读写时,这个过程"相当于"是按照顺序将数据替换给原字节数组的,(实际上理解为多层蛋糕更好,上层露出了)如果最后一次读取时,所剩余的字节数小于。字节数组能读取的字节数组是,则未进行替换的仍为上一次读取的数据。
如果是一个没有,则会返回-1
为了解决此问题可以使用String提供的读取数据从索引进行(读取的数据)。(包括前索引,不包括后索引)
以上过程也是可以用循环来进行。(可以用字节读取的返回值(该次读取的字节数)与每次能读取字节数进行比较,来判断什么时候结束,也可以用字节返回值为-1时)。
解决读取中文时乱码:一次读取所有字节
●方式一:自己定义一个字节数组与被读取的文件大小一样大,然后使用该字节数组,一 次读完文件的全部字节。
方法名称:public int read(byte[] buffer);(即,还是要用到用字节数组来进行)
每次用一个字节数组去读取,返回字节数组读取了多少个字节,如果发现没有数据可读会返回-1.
需要进行获取文件字节数。(用File提供的)(但由于文件和内存的大小原因,储存的长度类型不同,需要进行强转),此方法最多读取的为int类型

package zijieSR;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class test2 {
public static void main(String[] args) throws IOException {
File file=new File("src/zijieSR/date");
int length=(int)file.length();//获取文件的字节数
// InputStream in=new FileInputStream("src/zijieSR/date");//创建连接文件的通道
InputStream in=new FileInputStream(file);//创建连接文件的通道
byte[] By=new byte [length];//直接创建获取文件字节长度的的读取字节数组
int le0=in.read(By);
System.out.println(le0);
System.out.println(new String(By));
}●方式二: (从JDK9才开始拥有)Java官方为InputStream提供了如下方法,可以直接把文件的全部字节读取到-一个字节数组中返回。(但也可能出现文件过大无法读取)
方法名称:public byte[] readAllBytes() throws IOException
说明 :直接将当前字节输入流对应的文件对象的字节数据装到一个字节数组返回

package zijietest2;
import java.io.FileInputStream;
import java.io.InputStream;
public class 特殊t {
public static void main(String[] args) throws Exception {
InputStream in=new FileInputStream("src/zijietest2/date0");
byte [] Date=in.readAllBytes();
System.out.println(new String(Date));
System.out.println(Date.length);
}
}字节输出(从运行内存中写入硬盘(储存)中)流:
文件在进行写入的时候是不会换行的,这时如果要换行可以使用转移符号来写入对应码在进行输出即可\n(部分系统不可) \r\n(任何系统都可)
文件输出流在进行创建的时候会自动创建不需要先手动创建文件,也可以接入写好的文件的路径
也可以储存在file对象中(即new 时参数不为路径而是文件对象)

由方法图,也可以看到写入文件时默认时覆盖的,如果需要进行追加写入文件则需要在创建输出流时,写入,true(append默认是false)
一个字节输出流:
public FileOutputStream(file file)
文件在写入时会默认会覆盖原文件,需要进行添加true来解决。

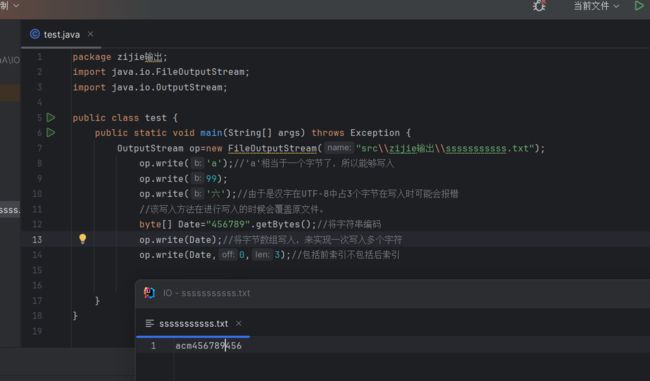
package zijie输出;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class test {
public static void main(String[] args) throws Exception {
OutputStream op=new FileOutputStream("src\\zijie输出\\sssssssssss.txt");
op.write('a');//'a'相当于一个字节了,所以能够写入
op.write(99);
op.write('撒');//由于是汉字在UTF-8中占3个字节在写入时可能会报错
//该写入方法在进行写入的时候会覆盖原文件。
byte[] Date="亲爱的小溪".getBytes();//将字符串编码
op.write(Date);//将字节数组写入,来实现一次写入多个字符,也可以以解决汉字可能乱码的问题(每次编码写入时是刚好对应字节的)
}
}
包括前索引,不包括后索引

写入文件时默认时覆盖的,如果需要进行追加写入文件则需要在创建输出流时,写入,true(append默认是false):

OutputStream op=new FileOutputStream("src\\zijie输出\\sssssssssss.txt",true);//写入true实现文件是追加写入
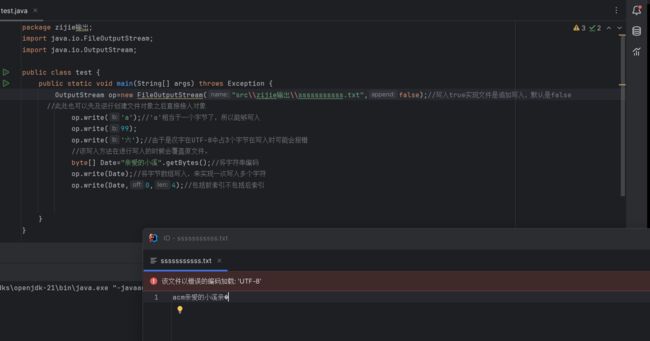
OutputStream op=new FileOutputStream("src\\zijie输出\\sssssssssss.txt",false);//写入true实现文件是追加写入,默认是false
字符流:
输入流之间方法等都是相同的只是在进行读取的时候,读取的结构不同
字符流是读取的字符,字节流读取的字节。
字符在进行读取,输出的时候由于是一个字符一个字符的进行的,所以可以读取所有文本
即,字符流适合文本
由于是字符所以需要用到char来进行
文件字符输入流:FileReader (读取到运行内存中)
读取完毕时返回的数据时-1

文件字符输出流:FileWriter(写入到文件中)
文件同样是不需要进行创建的,此方法在写入文件名时,会直接进行创建(也可以写入写好的文件路径)
也可以写入文件对象,输出也是有一个是否需要进行追加的。(默认是false,也需要在管道后写,true)

注意事项:(字符流的特殊优化之处)

字符流在进行写出数据的时候是先写入在一个中间缓冲区的,只有刷新流,或者关闭流才能写出成功。
关闭流(包括刷新流)
刷新流:输出流的对象.flush();
当流刷新之后,流还是可以继续进行使用的
关闭流:输出流的对象.close();
缓冲区是有限制的,如果缓冲区的内存已经占用完了,则系统会自动将缓冲流的数据储存在文件中,继续将缓冲流供给使用。

Io流下的其他流:“包装流”
这些都是基于字符流和字节流的,他们都是对原始流进行处理,来提高他们的性能。
高级流不能够直接进行追加文本输出,如果需要追加文本的输出,需要先直接创建低级流对象,在低级流中设置追加的输出方法。(即,不直接引用文件地址)
字节缓冲流:


之后在进行传输数据的时候需要用缓冲流对象(因为,如果是通过先创建指明的原始流对象,而不是匿名对象,原始流对象仍可以进行使用)
其他传输过程和原始流相同

字节流时:在进行输入,输出的时候用字节数组的时候每次读取的是1kb(自己设置)每次读取都需要调用系统
但在字节流的缓冲流下,每次调用读取的数据会先储存8kb到内存中,而字节数组在进行传输数据的时候是在内存中进行的传输快
字符缓冲输入流:

同样需要对字符流对象进行包装。
同字节缓冲流一样也是有初始8kb的缓冲区,也可以进行设置缓冲区的大小
BufferedReader有按行进行读取的特殊方法,所以在进行使用字符缓冲流的时候不建议使用多态的形式

(直接使用字符缓冲流的读取对象调用)在进行读取的时候是一次性的,如果有空白行,但后面还有内容则会输出空白行,如果没有内容之后则会输出null
字符缓冲输出流:
字符缓冲输出流也拥有特殊的方法,换行的方法,所以也不见进行多态来创建对象

同样是包装原始流的对象,默认也是8kb的缓冲池,可以进行初始化
该过程还是可以将转换流包装成缓冲流
转换流只是将缓冲流的对象转换为指定的编码类型
转换流:

用来解决不同文本编码不同进行传输的时候 出现错误的问题
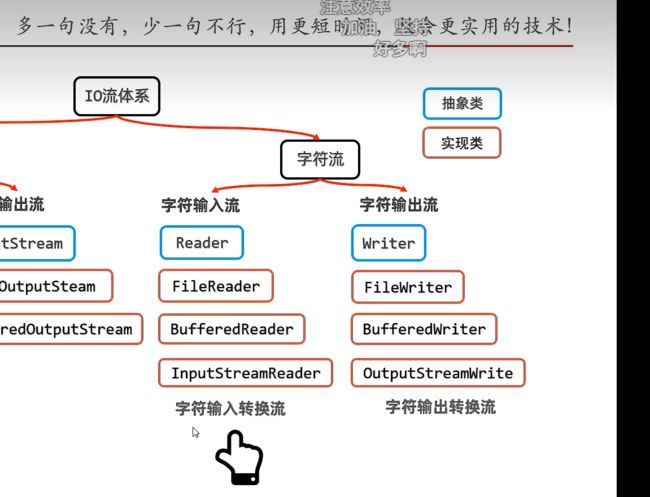
字符输入转换流:

String charset此处填入想要的编码类型,转换为想要的编码类型的字符输入流
InputStream is 填原始流。只使用该形参,相当于了使用writer了

字符输出转换流:


该过程还是可以将转换流包装成缓冲流
转换流只是将缓冲流的对象转换为指定的编码类型
打印流(输出):
是在进行输出的时候进行使用的,指写数据到文本
基本可以替代原来的输出流
PrintStream和printWritter是相似。

常常直接使用打印数据到文本中功能。
PrintStream打印流:

旗下方法也是特有的方法
可以直接指定构造器在输出的编码格式
内部包装了缓冲流
PrintWritter打印流:

打印流的特殊应用:输出语句的重定向
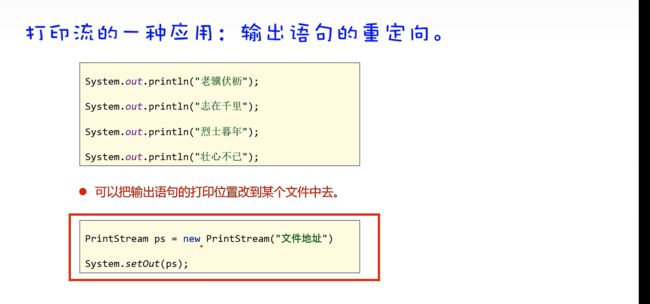
System.out (out使用的是打印流的默认对象默认是输出到控台的)可以借此直接将数据打印到文本中
同时,某种程度上打印==输出。

其提供了一个setOut的方法用于设置打印输出的地方(该地方是由打印流对象创建的),默认为null是输出到控制台。
只要创建打印流对象到指定文件位置,放在setOut参数上即可。
数据流:
需要进行包装低级流

数据输出流:

需要先进行包装一个低级的字节输出流
数据在进行储存的时候会按照储存的编码类型进行储存,可以储存多种编码类型的数据
当进行再次读取数据的时候,需要使用到数据输入流
数据输入流:
当进行再次读取数据的时候,需要使用到数据输入流

在进行读取数据的时候需要对应读取(即按照数据的前后数据类型进行读取),否则会报错


序列化流:

JAVA中如果需要对对象进行序列化,则对象类一定要实现Serializable接口(序列化接口)//相当于标记

需要进行包装低级字节流
对象字节输出流:

JAVA中如果需要对对象进行序列化,则对象类一定要实现Serializable接口(序列化接口)//相当于标记
对象字节输入流:

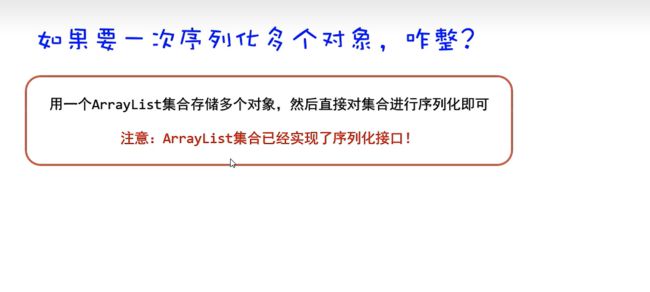
序列化多个对象:
transient 修饰符
序列化的对象包含被 transient 修饰的实例变量时,java 虚拟机(JVM)跳过该特定的变量。
该修饰符包含在定义变量的语句中,用来预处理类和变量的数据类型。
该修饰的作用在于,在进行对象序列化的时候不将某个属性进行存储