ELK使用配置文档
ELK使用配置文档
概述
对于日志来说,最常见的需求就是收集、存储、查询、展示,开源社区正好有相对应的开源项目:logstash(收集)、elasticsearch(存储+搜索)、kibana(展示),我们将这三个组合起来的技术称之为ELKStack,所以说ELKStack指的是Elasticsearch、Logstash、Kibana技术栈的结合。
1.elasticsearch配置
需要的环境
(1)JDK1.8及以上
(2)Elasticsearch官方提供的压缩包(本文使用7.10.1)
(1)下载安装
JDK安装和ES安装单机版,均为普通用户
1)JDK安装
①下载jdk安装包,放在/opt/app/software/java下
cd /opt/app/software/java
②进行解压操作
tar -zxvf jdk-8u251-linux-x64.tar.gz
③解压完成之后,进行环境变量的配置,shell下执行
vi ~/.bash_profile
根据jdk的安装目录,加入
export JAVA_HOME=/opt/app/software/java/jdk1.8.0_251
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
按ESC键,然后:wq保存退出;
④使jdk环境变量生效
source ~/.bash_profile
⑤安装完毕进行检查
java -version

⑥JDK安装完毕
2)ES安装单机版
该安装建立在linux普通用户aoc的基础上
①下载elasticsearch,到/opt/app/software
下载地址 : https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-10-1

cd /opt/app/software
②执行命令解压
tar -zxvf elasticsearch-7.10.1-linux-x86_64.tar.gz
③启动并查看安装状态(必须安装完毕jdk,并且环境变量配置完成)
cd elasticsearch-7.10.1
./bin/elasticsearch
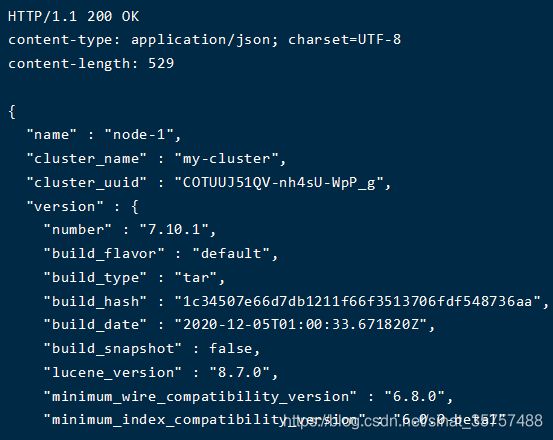
④本地查看版本信息
curl -i http://127.0.0.1:9200
如果出现如下界面,则证明安装成功
(2)首次启动可能出现的问题
此处出现的问题需要root用户在shell下进行操作,仅考虑在普通用户下安装可能出现 的问题
①提示:max number of threads [3818] for user [es] is too low, increase to at least [4096]
最大线程个数太低,可通过下面2个命令查看当前数量
ulimit -Hu
ulimit -Su
解决办法:
切换到root用户
vim /etc/security/limits.conf
新增以下配置(prouser是elasticsearch的普通用户)
prouser soft nproc 4096
prouser hard nproc 4096
②提示:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
每个进程最大同时打开文件数太小,可通过下面2个命令查看当前数量
ulimit -Hn
ulimit -Sn
解决办法:
切换到root用户
vim /etc/security/limits.conf
新增以下配置(prouser是elasticsearch的普通用户)
prouser soft nofile 65536
prouser hard nofile 65536
③修改linux主机用户名和ip的映射
查看主机名
hostname
切换root用户,vi /etc/hosts
做如下修改,新增一行,本机ip 主机名
192.168.0.1 vm-osvm84123-app
修改完成之后,按ESC键,然后输入 :wq 保存退出
2.es集群配置
(1)集群配置
集群配置中最重要的是node.name,每个节点都必须不同。node.name是节点名称主要是在Elasticsearch自己的日志加以区分每一个节点信息。
vi /opt/app/software/elasticsearch-7.10.1/config/elasticsearch.yml
显示如下
# 集群名称
cluster.name: my-cluster
# 节点名称,仅仅是描述名称,用于在日志中区分
node.name: node-1
# 数据的默认存放路径(可自行设定)
path.data: /opt/app/software/elasticsearch-7.10.1/runtime_data
# 日志的默认存放路径(可自行设定)
path.logs: /opt/app/software/elasticsearch-7.10.1/runtime_logs
# 当前节点的IP地址
network.host: 192.168.0.1
# 对外提供服务的端口
http.port: 9200
# 9300为集群服务的端口
transport.tcp.port: 9300
http.cors.enabled: true
http.cors.allow-origin: "127.0.0.1"
# 是否是master节点
node.master: true
node.data: true
# 集群每个节点IP地址
discovery.zen.ping.unicast.hosts: ["192.168.0.1", "192.168.0.2", "192.168.0.3"]
# 为了避免脑裂,集群节点数最少为 半数+1
discovery.zen.minimum_master_nodes: 2
# 初始化master节点是node-1
cluster.initial_master_nodes: node-1
(2)JVM配置
JVM配置由于Elasticsearch是Java开发的,所以可以通过/opt/app/software/elasticsearch-7.10.1/config/jvm.options配置文件来设定JVM的相关设定。
如果没有特殊需求按默认即可。
不过其中还是有两项最重要的-Xmx1g与-Xms1gJVM的最大最小内存。如果太小会导致Elasticsearch刚刚启动就立刻停止。太大会拖慢系统本身
vi /opt/app/software/elasticsearch-7.10.1/config/jvm.options
# JVM最大、最小使用内存
-Xms1g
-Xmx1g
(3)其他服务器配置
其他服务器的配置方法:
1.把如上配置好的ES,进行复制(可通过ftp进行下载、上传操作),然后上传或者直接scp到另外一处主机上面;
2.修改/opt/app/software/elasticsearch-7.10.1/config/elasticsearch.yml,主要区别如下
第一个:集群名称cluster.name保持不变;
第二个:node.name改成自己定义的节点名称;
第三个:host ip修改成本机的;
第四个:主节点node.master:true,其他节点此处要修改成false,注意修改
其他配置保持不变
3.完成
(4)启动Elasticsearch
分别启动每一台es
# -d表示后台启动
./bin/elasticsearch -d
(5)集群测试
①执行
curl -XGET 'http://127.0.0.1:9200/_cat/nodes?pretty'
出现如下图,表示集群启动成功
# *号表示为当前节点为主节点的意思
192.168.0.2 52 42 0 0.00 0.01 0.05 cdhilrstw - node-2
192.168.0.1 55 49 0 0.21 0.07 0.06 cdhilmrstw * node-1
192.168.0.3 61 57 0 0.01 0.04 0.05 cdhilrstw - node-3
如果要想查看更多有关于集群信息、当前节点统计信息等等,可以使用一下命令来获取到所有可以查看的信息。
curl -XGET 'http://127.0.0.1:9200/_cat?pretty'
至此,elasticsearch单机及分布式配置搭建完毕
2.kibana插件配置
用于查询和展示es里的日志数据,还可以进行统计画图,使监控更加方便。
(1)版本下载
下载kibana,https://www.elastic.co/cn/downloads/past-releases/kibana-7-10-1
到/opt/app/software/kibana,版本和es一致
cd /opt/app/software/kibana
解压
tar -zxvf kibana-7.10.1-linux-x86_64.tar.gz
(2)安装配置
解压完成之后,进入到配置目录config
编辑此文件
vi kibana.yml
该文件中,主要修改的有三处地方
①.该插件的端口地址 server.port;
②.该插件绑定的ip;
③.要监听的elasticsearch服务的地址。
# 端口
server.port: 5601
# 所在服务器ip
server.host: "192.168.0.3"
# es所在ip
elasticsearch.hosts: ["http://192.168.0.1:9200"]
(3)插件启动
需要es启起来才行,在kibana根目录下面执行
./bin/kibana
打开网址http://192.168.0.3:5601如果出现下面所示,代表插件启动成功
3.机器监控metribeat
安装此插件是为了监控集群软硬件的状态包含但不限于CPU使用率、内存使用率、硬盘使用率等,以起到预警作用。
需要监控哪个服务器就在那个服务器上安装metribeat。
(1)版本下载
下载地址https://www.elastic.co/cn/downloads/past-releases/metricbeat-7-10-1
可选择版本,和es版本一致,到/opt/app/software
cd /opt/app/software
解压
tar -zxvf metricbeat-7.10.1-linux-x86_64
(2)安装配置
进入到解压后的目录
执行vi命令,编辑metricbeat.yml文件,该文件为metricbeat的配置文件
vi metricbeat.yml
需要编辑的地方
1.Module configurations
该内容主要是配置该插件需要监控的信息,包含cpu、文件系统相关信息、进程信息、内存信息等。频率设置的为30S统计一次
metricbeat.modules:
#------------------------------- System Module -------------------------------
##qjl-update- system module to use
##default:below
- module: system
metricsets:
- socket # Sockets and connection info (linux only)
- cpu # CPU usage
- filesystem # File system usage for each mountpoint
- fsstat # File system summary metrics
- load # CPU load averages
- memory # Memory usage
- network # Network IO
- process # Per process metrics
- process_summary # Process summary
- uptime # System Uptime
- core # Per CPU core usage
- diskio # Disk IO
#socket.reverse_lookup.enabled: true
# #socket.reverse_lookup.success_ttl: 6s
# #socket.reverse_lookup.failure_ttl: 6s
enabled: true
#qjl-update-the time connect whit Elasticsearch
# #default:1s
period: 30s
processes: ['.*']
# Configure the metric types that are included by these metricsets.
cpu.metrics: ["percentages","normalized_percentages","ticks"] # The other available options are normalized_percentages and ticks.
core.metrics: ["percentages","ticks"] # The other available option is ticks.
2.设置主机名称
name: 192.168.0.1
3.设置kibana表盘可见
setup.dashboards.enabled: true
4.设置kibana端口信息
setup.kibana:
host: "192.168.0.3:5601"
#username: "elastic"
#password: "${KIBANA_PWD}"
5.输出配置(输出到ES)
output.elasticsearch:
hosts: ["192.168.0.1:9200","192.168.0.2:9200","192.168.0.3:9200"]
#username: "elastic"
#password: "${ES_PWD}"
5.其他的才用系统默认的配置即可
6.在metricbeat目录执行如下命令,使metricbeat启动
./metricbeat -e -c metricbeat.yml
7.自动关闭
启动2个小时后,metricbeat会自动关闭(filebeat也有这个问题),有两个解决办法
1)启动之后,输入命令exit,手动关闭与服务器连接(亲测有效)
2)自定义Service方式启动
参考:metricbeat自动关闭问题
filebeat参考:Filebeat自动关闭问题解决
(3)Kibana表盘展示
Metricbeat配置完成后的效果如下图所示
访问Dashboard->[Metricbeat System] Overview,用来监控服务器相关信息


可以看到各个指标均有体现
该指标为过去15分钟内的各项指标,如果需要查询更早以前的信息可以通过下图的按钮进行指标的查看,前提是有相关数据
(6)keystore使用
keystore防止敏感信息泄露,配置密码的时候可以直接引用
如:output.elasticsearch:password: “${ES_PWD}”
# 创建keystore
./metricbeat keystore create
# 添加key
./metricbeat keystore add ES_PWD
# 覆盖key的值
./metricbeat keystore add ES_PWD --force
# 展示key
./metricbeat keystore list
# 删除key
./metricbeat keystore remove ES_PWD
4.logstash使用
Logstash 是一款强大的数据处理工具,它可以实现数据传输,格式处理,格式化输出,还有强大的插件功能,常用于日志处理。相当于是一个日志的管道,收集日志,进行过滤以及处理,传输到es上进行存储。方便kibana展示。
(1)版本下载
下载地址:https://www.elastic.co/cn/downloads/past-releases/logstash-7-10-1可选择版本,和es版本一致,到/opt/app/software/logstash
cd /opt/app/software/logstash
解压
tar -zxvf logstash-7.10.1-linux-x86_64.tar.gz
(2)启动测试
从控制台读取数据,输出到控制台
./bin/logstash -e 'input { stdin { } } output { stdout {} }'
控制台输入hello world
返回如下,表示启动成功

(3)启动可能遇到相关问题
-
启动很慢
https://jingyan.baidu.com/article/9f7e7ec0e311926f29155462.html -
启动报错 Cannot allocate memory
vim config/jvm.options新增配置
-Xms512m -Xmx512m -
启动报错
Logstash could not be started because there is already another instance using the configured data directory. If you wish to run multiple instances, you must change the “path.data” setting.
之前运行的instance有缓冲,保存在path.data里面有.lock文件查看path.data设置的路径(默认在安装目录下data)
cat logstash.yml到data下,查询是否有.lock
ls -alh删除
rm .lock
(4)配置
复制config下logstash-sample.conf文件
cp logstash-sample.conf logstash.conf
修改配置,配置logstash从filebeat获取数据,发送到es
# 从filebeat获取日志数据
input {
beats {
port => 5044
}
}
#filter {
# grok {
# match => { "message" => "正则表达式" }
# overwrite => [ "message" ]
# }
#}
output {
elasticsearch {
# esip端口
hosts => ["http://esip:9200"]
# 索引名
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
(5)插件启动
logstash配置完成之后,执行如下命令,进入后台启动模式
在logstash目录下面执行
# 测试配置文件是否正确
./bin/logstash -t -f config/logstash.conf
# 指定配置启动
./bin/logstash -f config/logstash.conf
# 后台启动
nohup ./bin/logstash -f config/logstash.conf >/dev/null 2>&1 &
查看是否启动成功
jps -l
至此,logstash配置完成
(6)keystore使用
keystore防止敏感信息泄露,配置密码的时候可以直接引用
如:password => “${ES_PWD}”
# 创建keystore
./logstash-keystore create
# 添加key
./logstash-keystore add ES_PWD
# 覆盖key的值
./logstash-keystore add ES_PWD --force
# 展示key
./logstash-keystore list
# 删除key
./logstash-keystore remove ES_PWD
5.filebeat使用
由于logstash是java的程序,启动收集日志比较消耗资源,所以一般使用filebeat在各个服务器上收集日志,并且发送到logstash进行过滤。通常我们还会在filebeat和logstah直接增加一个kafka,用来持久化日志。Filebeat是一个轻量级日志传输Agent,可以将指定日志转发到Logstash、Elasticsearch、Kafka、Redis等中。Filebeat占用资源少,而且安装配置也比较简单,支持目前各类主流OS及Docker平台。
(1)版本下载
下载地址https://www.elastic.co/cn/downloads/past-releases/filebeat-7-10-1
可选择版本,和es版本一致,到/opt/app/software
cd /opt/app/software
解压
tar -zxvf filebeat-7.10.1-linux-x86_64
(2)配置
进入到解压后的目录
执行vi命令,编辑filebeat.yml文件,该文件为filebeat的配置文件
vi filebeat.yml
以下是filebeat一些常用配置的含义以及示例
###################### Filebeat配置示例 #########################
#=========================== Filebeat input =============================
filebeat.inputs:
- type: log
# 是否开启次路径扫描
enabled: true
# 爬取数据的文件路径
paths:
# 意思是采集这个目录下.log文件里面的内容
- /opt/DATA/*.log
# 可以直接配置多个采集路径
#- /opt/DATA1/*.log
# windows下路径示例
#- c:\programdata\elasticsearch\logs\*
tags: ["app"] #使用tag来区分不同的日志
# 采集多个目录的日志就再配置一个,可以用tags来区分
- type: log
enabled: true
paths:
- /opt/nginx-1.14.0/logs/stars/star.access.log
tags: ["nginx-access"] #使用tag来区分不同的日志
# 正则排除日志行,示例排除开头是DBG的行(只要是”^”这个字符是在中括号”[]”中被使用的话就是表示字符类的否定,如果不是的话就是表示限定开头)
#exclude_lines: ['^DBG']
# 包含日志行
#include_lines: ['^ERR', '^WARN']
# 正则排除文件
#exclude_files: ['.gz$']
# 向已抓取的日志文件添加额外信息以进行过滤
#fields:
#level: debug
#review: 1
# 下面输出到kafka的配置需要用到这个新增的字段
#topics: toppicname
### 多行配置
# 以下示例表示的是不以[开头的行合并到上一行的末尾
# 多行正则匹配
#multiline.pattern: ^\[
# 是否是上面正则的反对面
#multiline.negate: true
# 设置before或者after,示例表合并行到上一行末尾
#multiline.match: after
#============================= Filebeat配置文件 ===============================
filebeat.config.modules:
# filebeat配置文件存放地址
path: ${path.config}/modules.d/*.yml
# 配置是否重新加载
reload.enabled: false
# 每10秒检查path下文件是否有更改
#reload.period: 10s
#============================= Outputs =====================================
# 配置输出
#----------------------------- Logstash output --------------------------------
output.logstash:
# logstash地址list,可设置多个logstash实现高可用
hosts: ["logstaship:5044"]
# 多个logstash的时候是否使用负载均衡
#loadbalance: true
# 可选的SSL。默认为关闭。
# 用于HTTPS服务器验证的根证书列表
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# SSL客户端身份验证的证书位置
#ssl.certificate: "/etc/pki/client/cert.pem"
# 客户端证书的秘钥
#ssl.key: "/etc/pki/client/cert.key"
#-------------------------- Elasticsearch output -----------------------
# 输出到es
# 会自动生成一个filebeat-%{[beat.version]}-%{+yyyy.MM.dd}索引
#output.elasticsearch:
# es的ip端口
#hosts: ["localhost:9200"]
# 是否开启ILM策略使用索引生命周期管理,而不是使用每日索引
#ilm.enabled: false
# 可选协议和基本身份验证凭据
#protocol: "https"
#username: "elastic"
#password: "${ES_PWD}"
#------------------------------- File output -----------------------------------
# 输出到指定文件
#output.file:
#path: "/tmp"
#filename: "filebeat_messages.log"
#------------------------------- Kafka output ----------------------------------
#output.kafka:
# 是否开启
#enabled: true
# kafka的ip端口,多个
#hosts: ["localhost:9092"]
# 监听主题
#topic: '%{[fields][topics]}'
# 如果有账号密码,需要设置
#username: ''
#password: ''
# 配置JSON编码
#codec.json:
#pretty: false
# 启用SSL支持
#ssl.enabled: true
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
#ssl.verification_mode: full
#ssl.supported_protocols: [TLSv1.0, TLSv1.1, TLSv1.2]
#ssl.certificate: "/etc/pki/client/cert.pem"
#ssl.key: "/etc/pki/client/cert.key"
#ssl.key_passphrase: ''
#ssl.cipher_suites: []
#ssl.curve_types: []
#ssl.renegotiation: never
#================================ Logging =====================================
# 设置日志级别。默认日志级别为info,可用的日志级别有:error, warning, info, debug
#logging.level: debug
# 在调试级别,您可以有选择地仅为某些组件启用日志记录。
# 启用所有选择器使用["*"]。其他选择符的例子有"beat", "publish", "service"。
#logging.selectors: ["*"]
(3)启动
./filebeat -e -c filebeat.yml
(4)常用命令
# 默认配置启动
./filebeat -e
# 指定配置启动
./filebeat -e -c filebeat.yml
# 后台启动
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
# 覆盖特定的配置设置。 您可以指定多个覆盖
./filebeat -E "name=mybeat" -E "output.elasticsearch.hosts=["http://myhost:9200"]"
# 覆盖Filebeat模块的默认配置。您可以指定多个变量重写
./filebeat -modules=nginx -M "nginx.access.var.paths=['/var/log/nginx/access.log*']" -M "nginx.access.var.pipeline=no_plugins"
# 查看生效的模块
./filebeat modules list
# 生效es模块
./filebeat modules elasticsearch
(5)keystore使用
keystore防止敏感信息泄露,配置密码的时候可以直接引用
如:output.elasticsearch.password:"${ES_PWD}"
# 创建keystore
./filebeat keystore create
# 添加key
./filebeat keystore add ES_PWD
# 覆盖key的值
./filebeat keystore add ES_PWD --force
# 展示key
./filebeat keystore list
# 删除key
./filebeat keystore remove ES_PWD
6.es和kibana验证登录(x-pack)
(1)es配置
1)创建CA证书
./bin/elasticsearch-certutil ca
会让你设置输出路径和密码,都不用写,直接回车跳过,会在bin的同级目录下生成证书elastic-stack-ca.p12
2)生成节点使用的证书
./bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12
同样一路回车,会在bin同级目录生成elastic-certificates.p12
3)在config目录下新建certs文件夹
mkdir certs
4)将两个文件移动到certs下面
mv elastic-certificates.p12 elastic-stack-ca.p12 config/certs/
将两个文件scp到集群的别的服务器的同样位置
5)修改集群所有的服务器的es配置
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12
6)依次设置elastic几个内置用户的密码
./bin/elasticsearch-setup-passwords interactive
内置用户
| 用户名 | 作用 |
|---|---|
| elastic | 超级用户 |
| kibana | 用于负责Kibana连接Elasticsearch |
| logstash_system | Logstash将监控信息存储在Elasticsearch中时使用 |
| beats_system | Beats在Elasticsearch中存储监视信息时使用 |
| apm_system | APM服务器在Elasticsearch中存储监视信息时使用 |
| remote_monitoring_user | Metricbeat用户在Elasticsearch中收集和存储监视信息时使用 |
配置完毕,重启所有es服务器
7)带入账号密码检查是否启动成功
curl -i --user admin:admin http://127.0.0.1:9200
(2)kibana修改配置
elasticsearch.username: "kibana"
elasticsearch.password: "kibanapassword"
配置完毕,重启kibana
(3)logstash修改配置
输出到es的配置里面加上账号密码
output {
elasticsearch {
# esip端口
hosts => ["http://esip:9200"]
# 索引名
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
user => "elastic"
password => "changeme"
}
}
配置完毕,重启logstash
现在访问kibana地址http://192.168.0.3:5601,就需要账号密码登录了(使用的是es的账号密码)
7.异常监控
(1)操作原理
此处异常监控的功能,就需要使用整套ELK功能了,其中,logstash负责通过正则把日志中有用字段匹配出来,然后以字段的形式存入到Elasticsearch中,然后Kibana把数据取出,经过API的加工分析,以报表的方式进行数据趋势图的展示。
(2)实现步骤
①统一日志格式
其中需要截取的有关信息的日志格式为
2016-12-19 14:36:26,498 [INFO] appname._log[95]: send email use channel :6
②Logstash编写匹配原则
编辑logstash目录下面的logstash.conf文件
首先,配置数据来源
# 从filebeat获取日志数据
input {
beats {
port => 5044
}
}
其次,配置过滤信息
filter {
grok {
match => { "message" => "20%{YEAR:year}-%{MONTHNUM:month}-%{MONTHDAY:day} %{HOUR:hour}:?%{MINUTE:minutes}(?::?%{SECOND:second}) \[%{LOGLEVEL:level}\] appname._log%{NAGIOSTIME:linenumber}: (.*)
" }
overwrite => [ "message" ]
}
}
最后,配置完成匹配、并且切分好的数据输出到的地方
output {
elasticsearch {
# esip端口
hosts => ["http://esip:9200"]
# 索引名
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
至此,logstash配置完成
(3)Kibana数据展示
根据分解的字段,画对应的统计图进行监控
8.配置自动删除索引
参考:https://blog.csdn.net/UbuntuTouch/article/details/102728987
kibana进入Stack Management->Index Lifecycle Policies->Create policy创建索引的生命周期策略
也可以直接在dev tools上用语句创建,2天删除索引
PUT _ilm/policy/<policyName>
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 100
}
}
},
"delete": {
"min_age": "2d",
"actions": {
"delete":{}
}
}
}
}
}
给索引添加Lifecycle Policy
①直接添加,只有这一个索引生效
Stack Management->Index Management->indices->点击选择index->Manage->Add Lifecycle Policy->选择刚创建的生命周期策略
②给索引模板添加,满足索引模板的所有索引都生效
Stack Management->Index Management->Index Templates->选择或者创建索引模板->Manage->Edit->在index setting步骤下添加
{
"index": {
"lifecycle": {
"name": ""
}
}
}
9.警报和操作
(1)配置es需要https访问
获取elasticsearch-ca.pem,放在kibana的config下
openssl pkcs12 -in elastic-certificates.p12 -cacerts -nokeys -out elasticsearch-ca.pem
es配置
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.http.ssl.truststore.path: certs/elastic-certificates.p12
(2)配置kibana用https访问es
kibana配置
# 修改成https
elasticsearch.hosts: ["https://192.168.0.1:9200"]
elasticsearch.ssl.verificationMode: none
elasticsearch.ssl.certificateAuthorities: ["/opt/app/software/kibana/kibana-7.10.1-linux-x86_64/config/elasticsearch-ca.pem"]
# 配置自己的日志加密秘钥
xpack.reporting.encryptionKey: "a_random_string"
xpack.security.encryptionKey: "something_at_least_32_characters"
xpack.encryptedSavedObjects.encryptionKey: "something_at_least_32_characters"
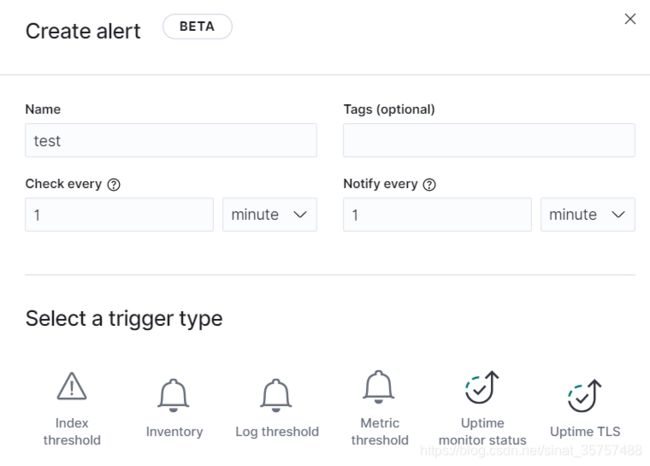
现在访问Stack Management->Alerts and Actions,就能够创建警报通知了

可以配置以下的监控告警
10.JAVA连接操作elasticsearch
引入pom
<properties>
<java.version>1.8java.version>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<elasticsearch.version>7.7.0elasticsearch.version>
<fastjson.version>1.2.70fastjson.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>${elasticsearch.version}version>
dependency>
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>${elasticsearch.version}version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-clientartifactId>
<version>${elasticsearch.version}version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>${fastjson.version}version>
dependency>
dependencies>
@Bean
public RestHighLevelClient getHighClient() {
// getHost() 为获取链接集群的地址
HttpHost httpHost=new HttpHost("192.168.0.1",9200,null);
HttpHost[] host = new HttpHost[]{httpHost};
RestClientBuilder builder = RestClient.builder(host);
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
// 设置ES 链接密码
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("elastic", "password"));
builder.setHttpClientConfigCallback(f -> f.setDefaultCredentialsProvider(credentialsProvider));
// 创建高级搜索链接,请注意改链接使用完成后必须关闭,否则使用一段时间之后将会抛出异常
RestHighLevelClient restClient = new RestHighLevelClient(builder);
return restClient;
}
@Autowired
RestHighLevelClient highClient;
public String createIndex() throws IOException {
BulkRequest request = new BulkRequest();
Map<String, String> map = new HashMap<>();
map.put("key","test");
String data = JSONObject.toJSONString(map);
request.add(new IndexRequest("ceshi").id("321").source(data, XContentType.JSON));
// 批量新增数据
BulkResponse bulk = highClient.bulk(request, RequestOptions.DEFAULT);
RestStatus status = bulk.status();
// 关闭链接
highClient.close();
return status.toString();
}
附:logstash插件配置示例
logstash配置主要有4个插件
(1)Input
输入插件
1)stdin input
从控制台读取数据
input {
stdin {
# 可以添加字段和值
add_field => {"key" => "value"}
# 可以设置编码解码类型
codec => "plain"
# 可以添加tags
tags => ["add"]
# 可以添加type,给filter和output做判断
type => "std"
}
}
2)File input
从文件读取数据
input {
file {
# 文件路径
path => ["/var/log/*.log", "/var/log/message"]
# 可以添加type,给filter和output做判断
type => "log"
# 从什么位置开始读取文件数据,默认是从末尾开始读
start_position => "beginning"
# 每隔多久去检查一次被监听的 path 下是否有新文件。默认值是 15 秒
#discover_interval => 15
# 每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒
#stat_interval => 1
# 存放文件读取记录的文件,默认在$HOME/.sincedb
#sincedb_path => ["/var/log/test.txt"]
}
}
3)filebeat input
从filebeat读取数据
input {
beats {
# 要监听的端口
port => 5044
}
}
4)kafka input
从kafka读取数据
input {
kafka {
# 服务地址
bootstrap_servers => ["kafka01:9092,kafka02:9092,kafka03:9092"]
# 订阅主题
topics => ["topics"]
# 消费者线程
consumer_threads => 5
# 可以添加type,给filter和output做判断
type => "test"
# 可向kafka添加事件
decorate_events => true
# kafka一般配json
codec => "json"
# 从最新的开始消费
auto_offset_reset => "latest"
# 如果kafka是需要账号密码访问的,需要配置以下配置
jaas_path => "jaas.conf路径"
security_protocol => "SASL_PLAINTEXT"
sasl_mechanism => "PLAIN"
}
}
新建jaas.conf
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="user"
password="password";
};
(2)codec
编码解码插件,配合其他三个插件使用
multiline
# 如果不是以'['开头的行,合并到前一行的后面
codec => multiline {
pattern => "^\["
negate => true
what => "previous"
}
(3)output
输出插件
1)stdout output
输出到控制台
output {
stdout { codec => rubydebug }
}
2)File output
输出到文件
output {
file {
path => "/opt/applog/%{+yyyy}/%{+MM}/%{+dd}/%{host}.log.gz"
# 格式化,保障和原数据格式相同
codec => line {
format => "%{message}"
}
gzip => true
}
}
3)elasticsearch output
输出到es
output {
elasticsearch {
hosts => ["es1:9201","es2:9201","es3:9201"]
index => "test-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
(4)filter
1)grok插件
grok语法
%{语法:语义}
%{正则名称:自定义的输出字段名称}
正则名称来源
- 默认的内置正则名称
https://www.cnblogs.com/renguiyouzhi/archive/2004/01/13/13279134.html - 自定义的 (?
the pattern here) - 配置pattern_definitions
- 配置patterns_dir
patterns_dir => ["/opt/logstash/patterns", "/opt/logstash/extra_patterns"]
举例
grok常用配置
match
字段⇒值匹配
overwrite
覆盖字段原来的值
filter {
grok {
match => { "message" => "%{SYSLOGBASE} %{DATA:message}" }
overwrite => [ "message" ]
}
}
提高性能
- 当 grok 无法匹配一个事件的时候,它将会为这个事件添加一个 tag。默认这个 tag 是 _grokparsefailure。
Logstash 允许你将这些事件路由到可以统计和检查的地方。 例如,你可以将所有失败的匹配写入文件:
input { # ... }
filter {
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:timestamp} [%{IPV4:ip};%{WORD:environment}] %{LOGLEVEL:log_level} %{GREEDYDATA:message}" }
}
}
output {
if "_grokparsefailure" in [tags] {
# write events that didn't match to a file
file { "path" => "/tmp/grok_failures.txt" }
} else {
elasticsearch { }
}
}
- 添加行锚点(^和$)的开始和结束,我们确保我们只会匹配整个字符串从开始到结束,而不包含其他的。
这在匹配失败的情况下非常重要。 如果锚点不在位,并且正则表达式引擎不能匹配一行日志,它将开始尝试在初始字符串的子字符串中查找该模式,因此我们在上面看到了性能下降 - 分层匹配
grok {
"match" => { "message" => [
'%{IPORHOST:clientip} %{DATA:process_name}\[%{NUMBER:process_id}\]: %{WORD:word_1} %{WORD:word_2} %{NUMBER:number_1} %{NUMBER:number_2} %{DATA:data}',
'%{IPORHOST:clientip} %{DATA:process_name}\[%{NUMBER:process_id}\]: %{WORD:word_1} %{NUMBER:number_1} %{NUMBER:number_2} %{NUMBER:number_3} %{DATA:data};%{NUMBER:number_4}',
'%{IPORHOST:clientip} %{DATA:process_name}\[%{NUMBER:process_id}\]: %{DATA:data} | %{NUMBER:number}'
] }
}
现在请注意,即使你的应用程序正确日志记录,grok 仍然会依次尝试将传入日志行与三个表达式进行匹配,从而在第一次匹配时中断。
这意味着确保我们尽可能快地跳到正确的位置仍然很重要,因为应用程序2总是有一个失败的匹配,应用程序3有两个失败的匹配
对Grok匹配进行分层:首先匹配 header,覆盖 message 字段,然后仅匹配 bodies
filter {
grok {
"match" => { "message" => '%{IPORHOST:clientip} %{DATA:process_name}\[%{NUMBER:process_id}\]: %{GREEDYDATA:message}' },
"overwrite" => "message"
}
grok {
"match" => { "message" => [
'%{WORD:word_1} %{WORD:word_2} %{NUMBER:number_1} %{NUMBER:number_2} %{GREEDYDATA:data}',
'%{WORD:word_1} %{NUMBER:number_1} %{NUMBER:number_2} %{NUMBER:number_3} %{DATA:data};%{NUMBER:number_4}',
'%{DATA:data} | %{NUMBER:number}'
] }
}
)
2)date插件
格式化时间
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
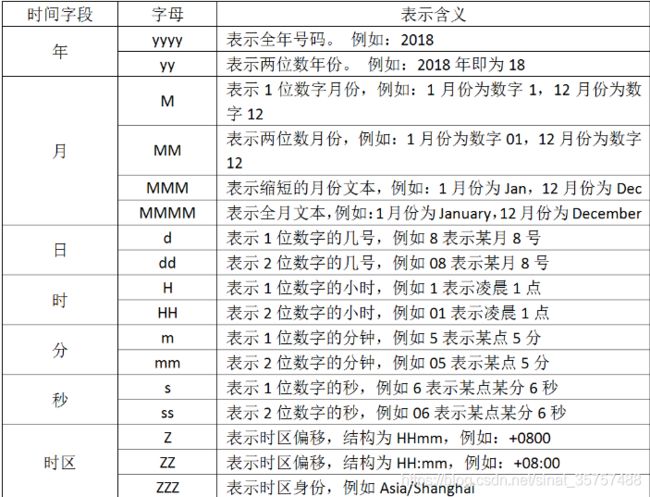
3)mutate插件
对字符串和字段进行处理
filter {
geoip {
source => "message"
}
mutate {
# 类型转换
#convert => ["@version", "float"]
# 替换字符串的内容,替换该字段所有"/"为"|"
#gsub => ["[geoip][timezone]","/","|"]
# 拆分
#split => ["[geoip][timezone]", "/"]
# 拼接
#join => ["[geoip][timezone]", "|"]
# 合并
#merge => ["[geoip][country_name]", "[geoip][country_name]"]
# 除去字段值前后空格
#strip => ["name"]
# 转小写
#lowercase => ["[geoip][country_code3]"]
# 转大写
#uppercase => ["[geoip][region_name]"]
# 重命名某个字段,如果目的字段已经存在,会被覆盖掉
#rename => ["[geoip][country_code2]", "host"]
# 更新某个字段的内容。如果字段不存在,不会新建
#update => {"[geoip][region_code]" => "CD"}
# 作用和 update 类似,但是当字段不存在的时候,它会起到 add_field 参数一样的效果,自动添加新的字段
#replace => {"name" => "replace"}
}
}
执行顺序
rename(event) if @rename
update(event) if @update
replace(event) if @replace
convert(event) if @convert
gsub(event) if @gsub
uppercase(event) if @uppercase
lowercase(event) if @lowercase
strip(event) if @strip
remove(event) if @remove
split(event) if @split
join(event) if @join
merge(event) if @merge
filter_matched(event)
4)geoip插件
可以根据ip查询相关信息
input {
stdin {
}
}
filter {
geoip {
source => "message"
# 可以选择需要返回的字段
#fields => ["region_name"]
# 可以去掉返回的字段
#remove_field => ["[geoip][latitude]", "[geoip][longitude]"]
# 可以重命名返回的geoip字段
#target => "location"
}
}
output {
stdout { codec => rubydebug }
}
控制台输入一个公网ip,回车
返回ip的信息
{
"geoip" => {
"latitude" => 39.9289,
"timezone" => "Asia/Shanghai",
"ip" => "132.232.98.51",
"country_code3" => "CN",
"longitude" => 116.3883,
"country_code2" => "CN",
"continent_code" => "AS",
"region_name" => "Beijing",
"location" => {
"lon" => 116.3883,
"lat" => 39.9289
},
"region_code" => "BJ",
"country_name" => "China"
},
"@version" => "1",
"message" => "132.232.98.51",
"@timestamp" => 2021-01-07T13:23:37.781Z,
"host" => "vm-osvm84119-app"
}