论文阅读《Uncertainty Guided Adaptive Warping for Robust and Efficient Stereo Matching》
论文地址:https://openaccess.thecvf.com/content/ICCV2023/html/Jing_Uncertainty_Guided_Adaptive_Warping_for_Robust_and_Efficient_Stereo_Matching_ICCV_2023_paper.html
概述
当前基于相关性代价体的立体匹配方法在跨域预测上表现不佳,导致模型在现实世界应用困难。大场景差异、不平衡的视差分布是带来噪声与特征失真的主要原因,也降低了模型的鲁棒性。此外,感受野受限限制模型获得全局信息,使模型对不同数据集敏感。
针对该问题,文中提出一种动态计算相关性的方法 Uncertainty Guided Adaptive Correlation (UGAC) 用于调整模型适应不同场景。在warp过程使用一个基于方差的不确定估计模块自适应调整采样区域。此外,文中提出一种学习的加权warp操作用于视图间的投影。在现有主流模型上增加了UGAC模块后,有效提升模型的鲁棒性与效率。实验结果表明,该方法在多个数据集上的泛化性能达到了sota水平。
模型架构

给定输入的左右视图 I L , I R ∈ R H × W × 3 \mathbf{I}_L,\mathbf{I}_R\in \mathbb{R}^{H\times W\times3} IL,IR∈RH×W×3,使用权值共享的特征提取网络得到多尺度特征图 { F L s } , { F R s } ∈ R s H × s W × C , s ∈ { 1 / 4 , 1 / 8 , 1 / 16 } \left\{\mathbf{F}_{L}^{s}\right\},\left\{\mathbf{F}_{R}^{s}\right\}\in\mathbb{R}^{sH\times sW\times C}, s\in\{1/4,1/8,1/16\} {FLs},{FRs}∈RsH×sW×C,s∈{1/4,1/8,1/16}。将多尺度特征图送入权值共享的3层级联ARM(自适应循环)模块,该模块由不确定引导自适应相关模块(UGAC)和门控循环单元(GRU)组成,由UGAC构建代价体后送入GRU预测视差残差图,最后预测的视差图经过上采样后得到原图尺寸的预测结果。
Uncertainty Guided Adaptive Correlation 不确定度引导自适应相关性计算模块

如图3所示,UGAC模块由上下文感知的投影模块、相关性计算层、不确定估计三个模块组成。在第 n t h n^{th} nth 轮的ARM模块,基于上一轮预测的视差图 d n − 1 d_{n-1} dn−1与不确定图 U n − 1 U_{n-1} Un−1,将右视图特征图 { F R s } \{\mathbf{F}_R^s\} {FRs} 先经过上下文感知投影模块投影到左视图计算代价体 V n V_{n} Vn与估计不确定度 U n U_n Un。
Correlation Layer 相关性计算层
基于局部邻域计算匹配点之间的相关性:
V n ( p ) = ∑ r ∈ R < F L ( p ) ⋅ F R ( p + r ) > , (1) V_n(\boldsymbol{p})=\sum_{r\in R}\left<\mathbf{F}_L(\boldsymbol{p})\cdot\mathbf{F}_R(\boldsymbol{p}+\boldsymbol{r})\right>,\tag{1} Vn(p)=r∈R∑⟨FL(p)⋅FR(p+r)⟩,(1)
其中 R R R 为局部搜索范围。
Content-aware Warping Layer 上下文感知投影模块
原始的warp操作如下:
F ^ R ( p ) = ∑ k ∈ K c k ⋅ F R ( p + d n − 1 ( p + k ) ) , (2) \hat{\mathbf{F}}_R(\boldsymbol{p})=\sum_{k\in K}\boldsymbol{c}_k\cdot\mathbf{F}_R\left(\boldsymbol{p}+\boldsymbol{d}_{n-1}(\boldsymbol{p}+\boldsymbol{k})\right),\tag{2} F^R(p)=k∈K∑ck⋅FR(p+dn−1(p+k)),(2)
其中 K K K 表示以像素 p p p 为中心的采样点区域, d n − 1 ( p + k ) d_{n−1}(p + k) dn−1(p+k) 表示 p + k p + k p+k 位置的对应视差。另外, c k c_k ck 是第 k k k 个点的权重,通常设为常数。然而,这种方式方式忽略了warp过程中的多样性,对所有的情况都以与内容无关的形式处理,在遮挡、无纹理区域会引入不匹配带来的特征失真与噪声。为此,文中提出一种基于上下文感知的方式计算 c k c_k ck,记为 w k ( p ) w_k(p) wk(p)。此外,考虑到不同情况下的视差视差范围与分布差异,引入一个偏置 o ( p , k ) o(p, k) o(p,k)自适应调整采样范围,针对不同区域使用不一样的采样范围:
F ^ R ( p ) = ∑ k ∈ K w k ( p ) ⋅ F R ( p + d n − 1 ( p + k ) + o ( p , k ) ) , \hat{\mathbf{F}}_R(\boldsymbol{p})=\sum_{k\in K}\boldsymbol{w}_k\left(\boldsymbol{p}\right)\cdot\mathbf{F}_R\left(\boldsymbol{p}+\boldsymbol{d}_{n-1}(\boldsymbol{p}+\boldsymbol{k})+\boldsymbol{o}(\boldsymbol{p},\boldsymbol{k})\right), F^R(p)=k∈K∑wk(p)⋅FR(p+dn−1(p+k)+o(p,k)),
这个操作由组相关可变性卷积实现。
Uncertainty Estimation 不确定性估计
传统的非参数变形会导致一些像素的歧义,如纹理缺失或遮挡区域,这些区域的视差分布可能有多个峰值,导致估计误差较大。为了解决这个问题,作者引入了基于方差的不确定性估计,用来指导warp过程中的偏移量 o ( p , k ) o(p,k) o(p,k),使得偏移量能够根据不同像素的不确定性进行自适应调整。这样,对于不确定性较高的像素,网络可以采用更大的采样范围,从而增加匹配的可能性。同时,这种方法也可以平衡不同数据集的视差分布,提高模型的泛化能力。
U n = 1 − σ ( ∑ ( V ˉ n − V n ) 2 ) , o = U n ⋅ C N N [ F L , S ( F R , d n − 1 ) ] , (4) \begin{aligned}\boldsymbol{U}_n&=1-\sigma(\sum\left(\bar{\boldsymbol{V}}_n-\boldsymbol{V}_n\right)^2),\\\boldsymbol{o}&=\boldsymbol{U}_n\cdot\mathrm{CNN}[\mathbf{F}_L,\mathcal{S}(\mathbf{F}_R,\boldsymbol{d}_{n-1})],\end{aligned}\tag{4} Uno=1−σ(∑(Vˉn−Vn)2),=Un⋅CNN[FL,S(FR,dn−1)],(4)
其中 V n V_n Vn是通过相关层计算出的代价体, S S S 是双线性差值采样, V ˉ n \bar{V}_n Vˉn是 V n V_n Vn的平均值, σ ( ⋅ ) σ(·) σ(⋅)是 sigmoid函数。模型能利用当前的视差预测的先验知识,来自适应地捕捉更多可能的采样邻域特征信息,如图4所示:

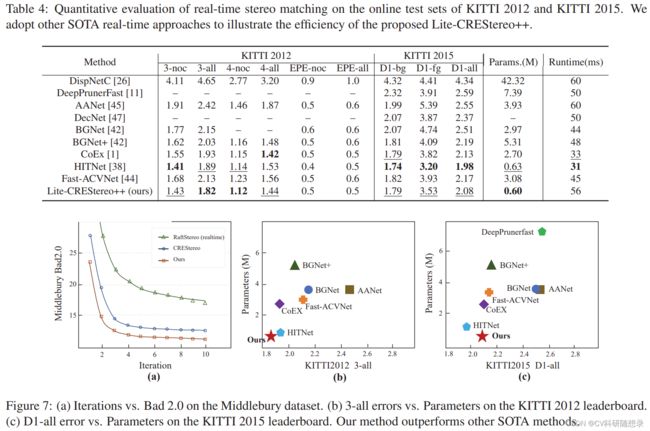
Lite-CREStereo++
Lite-CREStereo++基于CREStereo++的网络结构做了以下改进:一是减少了特征提取模块和循环模块的通道数,从而提高了模型的效率;二是在循环模块中增加了一个额外的1×15的卷积层,可以提高模型的准确度;三是将循环模块的迭代次数从低分辨率到高分辨率逐渐增加,而不是固定为相同的次数,这样可以在保证精度的同时,提高速度。这个模型可以实现实时的视差预测,而不牺牲太多精度。
损失函数
L = ∑ s ∑ i = 1 n γ n − i ∣ ∣ d g t − S ( d i s ) ∣ ∣ 1 , (5) \mathcal{L}=\sum_s\sum_{i=1}^n\gamma^{n-i}||\mathbf{d}_{\mathrm{gt}}-\mathcal{S}(\mathbf{d}_i^s)||_1,\tag{5} L=s∑i=1∑nγn−i∣∣dgt−S(dis)∣∣1,(5)
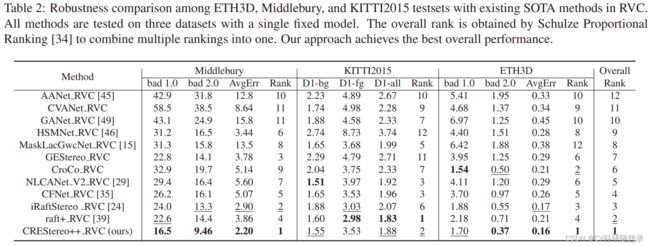
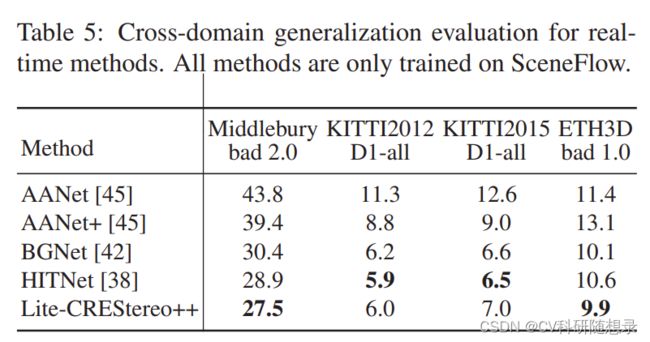
实验结果