Spring注入方式及解决循环依赖
依赖注入的方式:
- 注解注入:@Autowire和@Resource:这种注解可以直接解决循环依赖问题,不需要额外处理
- 构造方法器注入:构造方法注入需要使用@Lazy 注解来作用于循环依赖的属性
- setter注入:setter注入也可以直接解决循环依赖问题,不需要额外处理
注解注入:
@Autowrite是spring提供的注解;默认按照byType的方式进行注入,默认情况下要求依赖对象必须存在,可以设置它的required属性为false,如果想使用byName方式进行注解,可以配合@qualifier注解一起使用
@Autowired
private CycleBService cycleBService;
@Autowired
@Qualifier("cycleBServiceImpl")
private CycleBService cycleBService;
@Resource默认按照ByName自动注入,由J2EE提供,@Resource有两个重要的属性:name和type,而Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。
所以,如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不指定name也不指定type属性,这时将通过反射机制使用byName自动注入策略。
@Resource(name = "cycleBServiceImpl")
private CycleBService cycleBService;
@Resource(type = CycleBServiceImpl.class)
private CycleBService cycleBService;构造方法注入:
构造方法主要到底要不要加@Autowired?
@Autowired并不是必须的,不加也能注入成功,因为这个类会通过@RestController或者@Service等注解交给spring管理,这里不用加@Autowired也能成功的原因是,spring会对管理的bean的非默认构造函数的入参,尽量的匹配实例,进行实例化。这里还是建议加上@Autowired
private final CycleBService cycleBService;
@Autowired
public CycleAServiceImpl(CycleBService cycleBService) {
this.cycleBService = cycleBService;
}
setter注入:
构造器注入参数太多了,显得很笨重,另外setter的方式能用让类在之后重新配置或者重新注入。
private CycleBService cycleBService;
@Autowired
public void setter(CycleBService cycleBService){
this.cycleBService=cycleBService;
}
循环依赖问题:
@Service
public class CycleAServiceImpl implements CycleAService {
private CycleBService cycleBService;
@Autowired
public CycleAServiceImpl(CycleBService cycleBService) {
this.cycleBService = cycleBService;
}
@Override
public void printA() {
cycleBService.sayHello("我是A");
}
@Override
public void sayHello(String a) {
System.out.println("hello:" + a);
}
}
@Service
public class CycleBServiceImpl implements CycleBService {
private final CycleAService cycleAService;
@Autowired
public CycleBServiceImpl(CycleAService cycleAService) {
this.cycleAService = cycleAService;
}
@Override
public void printB() {
System.out.println("我是B");
cycleAService.printA();
}
@Override
public void sayHello(String a) {
System.out.println("hello:" + a);
}
}
上图中 CycleAService 依赖 CycleBService ,CycleBService 依赖 CycleAService ,简单来说就是A里面依赖B,B里面依赖A,所以在初始化spring bean的时候回抛出循环依赖的异常(仅限于构造器注入的方式,@Autowired不会),可使用@Lazy 注解作用于CycleAService 上
private final CycleAService cycleAService;
@Autowired
public CycleBServiceImpl(@Lazy CycleAService cycleAService) {
this.cycleAService = cycleAService;
}
这样就能解决循环依赖问题。那spring是怎么解决循环依赖呢,答案是三级缓存。
spring创建流程:
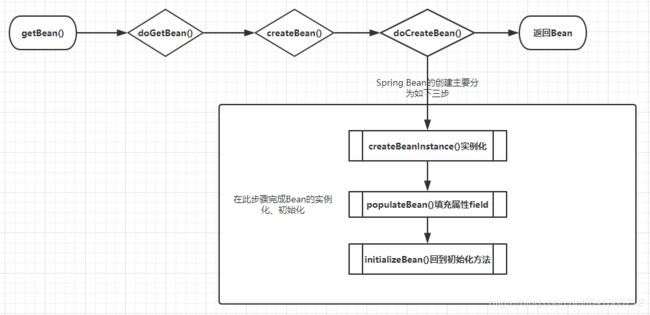
对Bean 的创建核心三个方法解释:
- createBeanInstance:例化,其实也就是调用对象的构造方法实例化对象
- populateBean:填充属性,这一步主要是对bean的依赖属性进行注入(@Autowired)
- initializeBean:回到一些形如initMethod、InitializingBean等方法
从单例Bean的初始化来看,循环依赖发生在第二步,也就是填充属性的一步。
Spring容器的“三级缓存”
在Spring容器的整个生命周期中,只有Scope为singleton(单例)才会注入到spring工厂中,由于单例Bean只有一个对象,于是可以使用缓存来管理它。
实际上,spring运用了大量的cache手段,来在循环依赖问题的解决过程中甚至不惜使用了“三级缓存”,这也便是它设计的精妙之处~
三级缓存其实它更像是Spring容器工厂的内的术语,采用三级缓存模式来解决循环依赖问题,这三级缓存分别指:
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
...
// 从上至下 分表代表这“三级缓存”
private final Map singletonObjects = new ConcurrentHashMap<>(256); //一级缓存
private final Map earlySingletonObjects = new HashMap<>(16); // 二级缓存
private final Map> singletonFactories = new HashMap<>(16); // 三级缓存
...
/** Names of beans that are currently in creation. */
// 这个缓存也十分重要:它表示bean创建过程中都会在里面呆着~
// 它在Bean开始创建时放值,创建完成时会将其移出~
private final Set singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap<>(16));
/** Names of beans that have already been created at least once. */
// 当这个Bean被创建完成后,会标记为这个 注意:这里是set集合 不会重复
// 至少被创建了一次的 都会放进这里~~~~
private final Set alreadyCreated = Collections.newSetFromMap(new ConcurrentHashMap<>(256));
}
注:AbstractBeanFactory继承自DefaultSingletonBeanRegistry
- singletonObjects:用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用
- earlySingletonObjects:提前曝光的单例对象的cache,存放原始的 bean 对象(尚未填充属性),用于解决循环依赖
- singletonFactories:单例对象工厂的cache,存放 bean 工厂对象,用于解决循环依赖
获取单例Bean源码:
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
...
@Override
@Nullable
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
...
public boolean isSingletonCurrentlyInCreation(String beanName) {
return this.singletonsCurrentlyInCreation.contains(beanName);
}
protected boolean isActuallyInCreation(String beanName) {
return isSingletonCurrentlyInCreation(beanName);
}
...
}- 先从一级缓存singletonObjects中去获取。(如果获取到就直接return)
- 如果获取不到或者对象正在创建中(isSingletonCurrentlyInCreation()),那就再从二级缓存earlySingletonObjects中获取。(如果获取到就直接return)
- 如果还是获取不到,且允许singletonFactories(allowEarlyReference=true)通过getObject()获取。就从三级缓存singletonFactory.getObject()获取。(如果获取到了就从singletonFactories中移除,并且放进earlySingletonObjects。其实也就是从三级缓存移动(是剪切、不是复制哦~)到了二级缓存)
加入singletonFactories三级缓存的前提是执行了构造器,所以构造器的循环依赖没法解决
getSingleton()从缓存里获取单例对象步骤分析可知,Spring解决循环依赖的诀窍:就在于singletonFactories这个三级缓存。这个Cache里面都是ObjectFactory,它是解决问题的关键。
// 它可以将创建对象的步骤封装到ObjectFactory中 交给自定义的Scope来选择是否需要创建对象来灵活的实现scope。 具体参见Scope接口
@FunctionalInterface
public interface ObjectFactory {
T getObject() throws BeansException;
经过ObjectFactory.getObject()后,此时放进了二级缓存earlySingletonObjects内。这个时候对象已经实例化了,虽然还不完美,但是对象的引用已经可以被其它引用了。
此处说一下二级缓存earlySingletonObjects它里面的数据什么时候添加什么移除???
添加:向里面添加数据只有一个地方,就是上面说的getSingleton()里从三级缓存里挪过来
移除:addSingleton、addSingletonFactory、removeSingleton从语义中可以看出添加单例、添加单例工厂ObjectFactory的时候都会删除二级缓存里面对应的缓存值,是互斥的。
总结
依旧以上面A、B类使用属性field注入循环依赖的例子为例,对整个流程做文字步骤总结如下:
- 使用context.getBean(A.class),旨在获取容器内的单例A(若A不存在,就会走A这个Bean的创建流程),显然初次获取A是不存在的,因此走A的创建之路~
- 实例化A(注意此处仅仅是实例化),并将它提前放进三级缓存中(此时A已经实例化完成,已经可以被引用了)
- 初始化A:@Autowired依赖注入B(此时需要去容器内获取B)
- 为了完成依赖注入B,会通过getBean(B)去容器内找B。但此时B在容器内不存在,就走向B的创建之路~
- 实例化B,并将其放入三级缓存中。(此时B也能够被引用了)
- 初始化B,@Autowired依赖注入A(此时需要去容器内获取A)
- 此处重要:初始化B时会调用getBean(A)去容器内找到A,从一级缓存->二级缓存->三级缓存,一级一级获取,上面我们已经说过了此时候因为A已经实例化完成了并且放进了三级缓存里,所以这个时候去看缓存里是已经存在A的引用了的,所以getBean(A)能够正常返回
- B初始化成功(此时已经注入A成功了,已成功持有A的引用了),return(注意此处return相当于是返回最上面的getBean(B)这句代码,回到了初始化A的流程中~)。
- 因为B实例已经成功返回了,因此最终A也初始化成功
- 到此,B持有的已经是初始化完成的A,A持有的也是初始化完成的B,完美~
站的角度高一点,宏观上看Spring处理循环依赖的整个流程就是如此。希望这个宏观层面的总结能更加有助于小伙伴们对Spring解决循环依赖的原理的了解,同时也顺便能解释为何构造器循环依赖就不好使的原因。