【Flink系列四】Window及Watermark
3.1、window
在 Flink 中 Window 可以将无限流切分成有限流,是处理有限流的核心组件,现在 Flink 中 Window 可以是时间驱动的(Time Window),也可以是数据驱动的(Count Window)。


Flink中的窗口可以分成:滚动窗口(Tumbling Window,无重叠),滑动窗口(Sliding Window,可能有重叠),会话窗口(Session Window,活动间隙),全局窗口(Gobal Window)
3.1.1、Tumbling Windows 滚动窗口

滚动窗口的assigner分发元素到指定大小的窗口。滚动窗口的大小是固定的,且各自范围之间不重叠。
// 滚动event-time窗口
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.();
// 滚动processing-time窗口
input
.keyBy()
.window(TumblingProcessingTimeWindows.of(Time.second(5)))
.();
// 长度为一天的滚动event-time窗口, 偏移量为-8小时
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.();
如上一个例子所示,滚动窗口的 assigners 也可以传入可选的 offset 参数。这个参数可以用来对齐窗口。 比如说,不设置 offset 时,长度为一小时的滚动窗口会与 linux 的 epoch 对齐。 你会得到如 1:00:00.000 - 1:59:59.999、2:00:00.000 - 2:59:59.999 等。 如果你想改变对齐方式,你可以设置一个 offset。如果设置了 15 分钟的 offset, 你会得到 1:15:00.000 - 2:14:59.999、2:15:00.000 - 3:14:59.999 等。 一个重要的 offset 用例是根据 UTC-0 调整窗口的时差。比如说,在中国你可能会设置 offset 为 Time.hours(-8)。
3.1.2、Sliding Windows滑动窗口

滑动窗口的assigner 分发元素到指定大小的窗口,窗口大小通过 window size 参数设置。 滑动窗口需要一个额外的滑动距离(滑动步长window slide)参数来控制生成新窗口的频率。 因此,如果 slide 小于窗口大小,滑动窗口可以允许窗口重叠。这种情况下,一个元素可能会被分发到多个窗口。
// 滑动 event-time 窗口
input
.keyBy()
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.();
// 滑动 processing-time 窗口
input
.keyBy()
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.();
// 滑动 processing-time 窗口,偏移量为 -8 小时
input
.keyBy()
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.();
3.1.3、Session Windows 会话窗口

会话窗口的 assigner 会把数据按活跃的会话分组。 与滚动窗口和滑动窗口不同,会话窗口不会相互重叠,且没有固定的开始或结束时间。 会话窗口在一段时间没有收到数据之后会关闭,即在一段不活跃的间隔之后。 会话窗口的 assigner 可以设置固定的会话间隔(session gap)或 用 session gap extractor 函数来动态地定义多长时间算作不活跃。 当超出了不活跃的时间段,当前的会话就会关闭,并且将接下来的数据分发到新的会话窗口。
// 设置了固定间隔的event-time会话窗口
input
.keyBy()
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.();
// 设置了动态间隔的event-time会话窗口
input
.keyBy()
.window(EventTimeSessionWindows.withDynamicGap((element)-> {
// 决定并返回会话间隔
}))
.();
// 设置了固定间隔的 processing-time session 窗口
input
.keyBy()
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.();
// 设置了动态间隔的 processing-time 会话窗口
input
.keyBy()
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// 决定并返回会话间隔
}))
3.1.4、Global Windows 全局窗口

全局窗口的 assigner 将拥有相同 key 的所有数据分发到一个全局窗口。 这样的窗口模式仅在你指定了自定义的 trigger 时有用。 否则,计算不会发生,因为全局窗口没有天然的终点去触发其中积累的数据。
input
.keyBy()
.window(GlobalWindows.create())
.();
3.1.5、Triggers窗口触发
Trigger决定了一个窗口(由window assigner定义)何时可以被window function处理。一般来说,watermark的时间戳>=window endTime并且在窗口内有数据,就会触发窗口的计算。每个WindowAssigner都有一个默认的Trigger。如果默认trigger无法满足需求,可以在trigger(...)调用中指定自定义的trigger。
- onElement() 每次往 window 增加一个元素的时候都会触发
- onEventTime() 当 event-time timer 被触发的时候会调用
- onProcessingTime() 当 processing-time timer 被触发的时候会调用
- onMerge() 对两个 trigger 的 state 进行 merge 操作
- clear() window 销毁的时候被调用
上面的接口中前三个会返回一个 TriggerResult,TriggerResult 有如下几种可能的选择:
- CONTINUE 不做任何事情
- FIRE 触发 window
- PURGE 清空整个 window 的元素并销毁窗口
- FIRE_AND_PURGE 触发窗口,然后销毁窗口
3.2、time和watermark
3.2.1、time
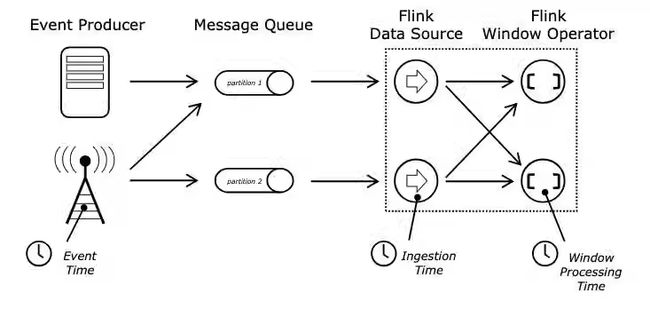
在 Flink 中 Time 可以分为三种Event-Time,Processing-Time 以及 Ingestion-Time,三者的关系我们可以从下图中得知:
3.2.2、watermark
Flink提出了watermark,专门处理EventTime窗口计算,其本质其实就是一个时间戳。因为对于迟到数据late element,不可能一直无限期等待,必须有一个机制来保证一个特定的时间后,必须取触发window去进行计算,这种机制就是watermark
watermark本质上也是一种时间戳,由Apache Flink Source或者自定义的Watermark生成器按照需求Punctuated或者Periodic两种方式生成的一种系统Event,与普通数据流Event一样流转到对应的下游算子,接收到Watermark Event的算子以此不断调整自己管理的EventTime clock。 Apache Flink 框架保证Watermark单调递增,算子接收到一个Watermark时候,框架知道不会再有任何小于该Watermark的时间戳的数据元素到来了,所以Watermark可以看做是告诉Apache Flink框架数据流已经处理到什么位置(时间维度)的方式。 Watermark的产生和Apache Flink内部处理逻辑如下图所示:

目前Apache Flink 有两种生产Watermark的方式,如下:
- Punctuated - 数据流中每一个递增的EventTime都会产生一个Watermark。 在实际的生产中Punctuated方式在TPS很高的场景下会产生大量的Watermark在一定程度上对下游算子造成压力,所以只有在实时性要求非常高的场景才会选择Punctuated的方式进行Watermark的生成。
- Periodic - 周期性的(一定时间间隔或者达到一定的记录条数)产生一个Watermark。在实际的生产中Periodic的方式必须结合时间和积累条数两个维度继续周期性产生Watermark,否则在极端情况下会有很大的延时。
参阅:Apache Flink 漫谈系列(03) - Watermark-阿里云开发者社区
我们可以考虑一个这样的例子:某 App 会记录用户的所有点击行为,并回传日志(在网络不好的情况下,先保存在本地,延后回传)。A 用户在 11:02 对 App 进行操作,B 用户在 11:03 操作了 App,但是 A 用户的网络不太稳定,回传日志延迟了,导致我们在服务端先接受到 B 用户 11:03 的消息,然后再接受到 A 用户 11:02 的消息,消息乱序了。那我们怎么保证基于 event-time 的窗口在销毁的时候,已经处理完了所有的数据呢?这就是 watermark 的功能所在。watermark 会携带一个单调递增的时间戳 t,watermark(t) 表示所有时间戳不大于 t 的数据都已经到来了,未来小于等于t的数据不会再来,因此可以放心地触发和销毁窗口了。下图中给了一个乱序数据流中的 watermark 例子

3.2.3、迟到的数据
上面的 watermark 让我们能够应对乱序的数据,但是真实世界中我们没法得到一个完美的 watermark 数值 — 要么没法获取到,要么耗费太大,因此实际工作中我们会使用近似 watermark — 生成 watermark(t) 之后,还有较小的概率接受到时间戳 t 之前的数据,在 Flink 中将这些数据定义为 “late elements”, 同样我们可以在 window 中指定是允许延迟的最大时间(默认为 0),可以使用下面的代码进行设置

设置allowedLateness之后,迟来的数据同样可以触发窗口,进行输出,利用 Flink 的 side output 机制,我们可以获取到这些迟到的数据,使用方式如下:
