显存优化 Trick(gradient_accumulation、gradient_checkpointing、xformers)
目录
-
- Out of Memory
- Gradient Accumulation
- Gradient Checkpointing
- Xformers
- Diffusers的显存优化
Out of Memory
先来说下OOM问题,其实也是日常会遇到的情况。模型申请的显存超过了设备实际显存大小,则会报错Out of Memory。一般情况下,batch size设置过大,不能匹配自己手里的计算设备(GPU、TPU等)显存时,会经常触发这个问题。
一般遇到这个情况,都会选择调小batch size,但是很多模型本身就非常大(尤其是预训练模型当道的今天),记得19年的时候拿一张1080ti做BERT finetune,11G的显存,batch size最大也就就能设置成4。但是batch size又是很影响训练效果的超参,在很多时候只能在原作者调参得到的那个数值下才能训练出较好的结果。此时,有钱就选择加卡,不然就只能另辟蹊径来磨一磨手里这张小显存的计算卡了。
正常的训练流程:每个step送入1个batch_size的数据计算梯度,然后用这个梯度反向传播更新参数,接着送入下一个batch_step的数据重复。
Gradient Accumulation
梯度累加 gradient_accumulation ,顾名思义,就是将多次计算得到的梯度值进行累加,然后一次性反向传播,进行参数更新。
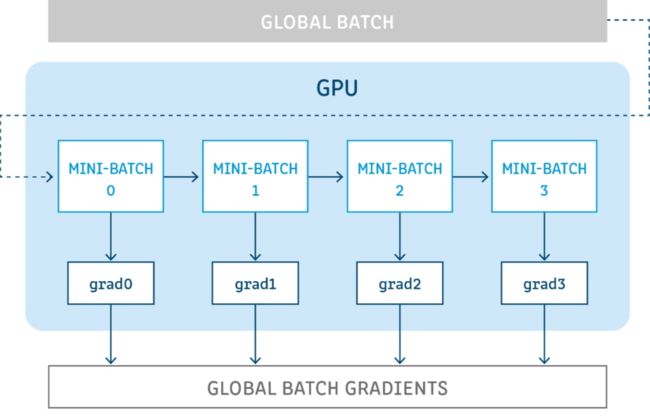
如图所示,假设我们有batch size = 256的global-batch,在单卡训练显存不足时,将其分为多个小的mini-batch=64(如图分为大小为64的4个mini-batch),每个step送入1个mini-batch获得梯度,将多次获得的梯度进行累加后再更新参数,以次达到模拟单次使用global-batch训练的目的。

自动微分机制和梯度累加实现
由于不同深度学习框架的自动微分机制不同,所以实现梯度累加的方式有显著差异。当前业界框架的自动微分机制分为两类:
- 以Tensor为核心的自动微分,Tensor可配置requires_grad参数控制是否需要梯度。每个Tensor对象有grad_fn属性用来存储该Tensor参与的反向操作,同时还有grad属性,存储该Tensor对应的梯度。
计算梯度时通过标量loss.backward()实现。由于API接口使用方式很符合反向传播的概念,业界多数框架选择此方案,如Pytorch、Paddle、Oneflow、MegEngine等。 - 函数式自动微分。将神经网络正向计算视作输入到Loss的计算函数,通过函数变换获得反向计算函数,并调用反向计算函数来获得梯度。业界采用此方案的框架有Jax、MindSpore,此外Tensorflow的GradientTape本质上也可以视作该方案的变种。
自动微分原理都是一致的,这两种方案的核心差异点在于是否暴露了自动微分更底层的接口,如Pytorch等框架更多定位纯深度学习,此时只体现backward更符合目标用户的使用习惯。而Jax、MindSpore则在定位上更加底层,Jax直接明言自身为数值计算框架,MindSpore则定位为AI+科学计算融合计算框架,因此函数式自动微分设计更符合框架定位。
由于两种方案的差异,也造成了梯度累加实现的差异,下面主要以Pytorch为例,讲一下梯度累加的实现:
# batch accumulation parameter
accum_iter = 4
# loop through enumaretad batches
for batch_idx, (inputs, labels) in enumerate(data_loader):
# forward pass
preds = model(inputs)
loss = criterion(preds, labels)
# scale the loss to the mean of the accumulated batch size
loss = loss / accum_iter
# backward pass
loss.backward()
# weights update
if ((batch_idx + 1) % accum_iter == 0) or (batch_idx + 1 == len(data_loader)):
optimizer.step()
optimizer.zero_grad()
由于Pytorch本身,在求完梯度后会自动挂载到Tensor.grad属性上,而在没有手动清空(即optimizer.zero_grad())的情况下,每个step训练求得的梯度会自动累加,因此只需要控制梯度清零和参数更新的间隔步数即可。
这里着重强调一个位置,loss = loss / accum_iter这一行操作的含义及实现。稍微翻看了一下搜索引擎排名靠前的几篇,发现误导不少。
首先是注释里说明的含义,不知出处但是几乎所有人都备注一句normalize loss to account for batch accumulation,中文译作loss正则化。这个地方显然是越写越偏了。
实际上这里就是做了一次求mean的操作。原因是直接累加的accum_iter次梯度值作为一次参数更新的梯度,是将梯度值放大了accum_iter倍,而Pytorch的参数更新是写在optimizer.step()方法内部,无法手动控制,因此只能根据链式法则,在loss处进行缩放,来达到缩放梯度的目的。与常规理解的正则化没有任何关系。
此外,还有一个谬误的写法:
loss = criterion(outputs, labels)
loss += loss / accumulation_steps
loss.backward()
loss通常不会这样累加,一般会单独维护一个 total_loss, 且累加之后再做loss.backward(),微分结果也是错误的,由左式正确的偏导,变为loss累加和对w求偏导:
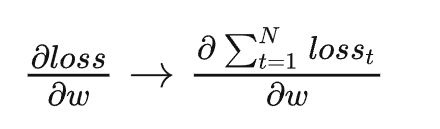
Gradient Checkpointing
当我们采用了分布式训练以及混合精度训练都不能降低显存大小的时候(比如多语言large模型,光词表就有几十万),现有的 GPU 资源无法训练一个设备装不下的模型。下面我们介绍一种改善这个问题的技术:梯度检查点 gradient_checkpointing
简单的说,梯度检查点 gradient_checkpointing 的工作原理是在反向传播时重新计算深度神经网络的中间值(而通常情况是在前向传播时存储的)。 这个策略是用时间(重新计算这些值两次的时间成本)来换空间(提前存储这些值的内存成本)。
神经网络使用的总内存基本上是两个部分的总和:
- 第一部分是
模型使用的静态内存。尽管 PyTorch 模型中内置了一些固定开销,但总的来说几乎完全由模型权重决定。而如今,在生产中使用的现代深度学习模型的总参数在100万到10亿之间。作为参考,一个带 16GB GPU 内存的 NVIDIA T4 的实际限制大约在1-1.5亿个参数之间。 - 第二部分是
模型的计算图所占用的动态内存。在训练模式下,每次通过神经网络的前向传播都为网络中的每个神经元计算一个激活值,这个值随后被存储在所谓的计算图中。必须为批次中的每个单个训练样本存储一个值,因此数量会迅速的累积起来。总成本取决于模型大小和批处理大小,并设置适用于您的GPU内存的最大批处理大小的限制。
模型的训练需要计算前向传播(forward)来获得预测结果,然后通过反向传播(backward)来计算梯度以进行参数更新。
一开始前向传播forward计算结果时,存储储激活值的原因是,在反向传播backword期间计算梯度时需要用到激活值。
现在,在forward后不存储激活值,在backward需要激活值时重新计算。
梯度检查点gradient_checkpointing是如何起作用的
大型模型在静态和动态方面都很耗资源。首先,它们很难适配 GPU,而且哪怕你把它们放到了设备上,也很难训练,因为批处理大小被迫限制的太小而无法收敛。
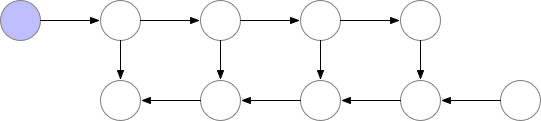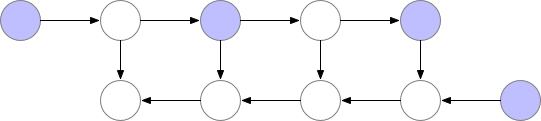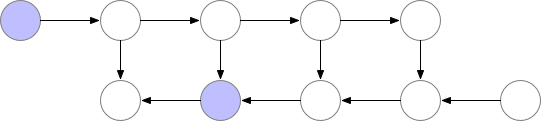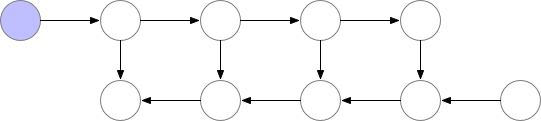
梯度检查点(gradient checkpointing)的工作原理是从计算图中省略一些激活值(由前向传播产生,其中这里的”一些“是指可以只省略模型中的部分激活值,折中时间和空间,陈天奇在它的论文中Training Deep Nets with Sublinear Memory Cost使用了如下动图的方法,即前向传播的时候存一个节点释放一个节点,空的那个等需要用的时候再backword的时候重新计算)。这减少了计算图使用的内存,降低了总体内存压力(并允许在处理过程中使用更大的批次大小)。
PyTorch 通过torch.utils.checkpoint.checkpoint和torch.utils.checkpoint.checkpoint_sequential提供梯度检查点,根据官方文档的 notes,它实现了以下功能:在前向传播时,PyTorch 将保存模型中的每个函数的输入元组。在反向传播过程中,对于每个函数,输入元组和函数的组合以实时的方式重新计算,插入到每个需要它的函数的梯度公式中,然后丢弃(显存中只保存输入数据和函数)。网络计算开销大致相当于每个样本通过模型前向传播开销的两倍。
梯度检查点算法将模型的动态内存开销从 O ( N ) O(N) O(N) (n为模型中的层数)降低到 O ( N ) O(\sqrt{N}) O(N) ,并通过实验展示了将 ImageNet 的一个变种从 48GB 压缩到了 7GB 内存占用。
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.checkpoint import checkpoint
class in_conv(nn.Module):
def __init__(self, in_ch, out_ch):
super(in_conv, self).__init__()
self.op = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, kernel_size=3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.op(x)
return x
class conv3x3(nn.Module):
def __init__(self, in_ch, out_ch):
super(conv3x3, self).__init__()
self.op = nn.Sequential(
nn.Conv2d(in_ch,out_ch, kernel_size=3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch,out_ch, kernel_size=3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.op(x)
return x
class down_block(nn.Module):
def __init__(self, in_ch, out_ch):
super(down_block, self).__init__()
self.pool = nn.MaxPool2d(2, stride=2)
self.conv = conv3x3(in_ch, out_ch)
def forward(self, x):
x = self.pool(x)
x = self.conv(x)
return x
class up_block(nn.Module):
def __init__(self, in_ch, out_ch, residual=False):
super(up_block, self).__init__()
self.up = nn.ConvTranspose2d(in_ch, in_ch // 2, kernel_size=2, stride=2)
self.conv = conv3x3(in_ch, out_ch)
def forward(self, x1, x2):
x1 = self.up(x1)
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, (diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2))
x = torch.cat([x2, x1], dim=1)
x = self.conv(x)
return x
class out_conv(nn.Module):
def __init__(self, in_ch, out_ch):
super(out_conv, self).__init__()
self.conv = nn.Conv2d(in_ch, out_ch, kernel_size=1)
def forward(self, x):
x = self.conv(x)
return x
class UNet(nn.Module):
def __init__(self, img_channels, n_classes,use_checkpoint=False):
super(UNet, self).__init__()
self.inc = in_conv(img_channels,64)
self.down1 = down_block(64, 128)
self.down2 = down_block(128, 256)
self.down3 = down_block(256, 512)
self.down4 = down_block(512, 1024)
self.up1 = up_block(1024, 512)
self.up2 = up_block(512, 256)
self.up3 = up_block(256, 128)
self.up4 = up_block(128, 64)
self.outc = out_conv(64, 1)
def forward(self, x):
def forward(self, x):
x = Variable(x,requires_grad=True)
if self.use_checkpoint:
x1 = checkpoint(self.inc,x)
x2 = checkpoint(self.down1,x1)
x3 = checkpoint(self.down2,x2)
x4 = checkpoint(self.down3,x3)
x5 = checkpoint(self.down4,x4)
x = checkpoint(self.up1,x5,x4)
x = checkpoint(self.up2,x,x3)
x = checkpoint(self.up3,x,x2)
x = checkpoint(self.up4,x,x1)
x = checkpoint(self.outc,x)
else:
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
x = self.outc(x)
return x
注意第94行,必须确保checkpoint的输入输出都声明为require_grad=True的Variable,否则运行时会报如下的错
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
网络训练高效内存管理——torch.utils.checkpoint的使用
torch.utils.checkpoint 简介 和 简易使用
此外,HuggingFace Transformers 也支持 Gradient Checkpoint。 梯度检查点可以通过 PreTrainedModel 实例的 gradient_checkpointing_enable 方法执行。
from transformers import AutoConfig, AutoModel
# https://github.com/huggingface/transformers/issues/9919
from torch.utils.checkpoint import checkpoint
# initializing model
model_path = "microsoft/deberta-v3-base"
config = AutoConfig.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path, config=config)
# gradient checkpointing
if model.supports_gradient_checkpointing:
model.gradient_checkpointing_enable()
print(f"Gradient Checkpointing: {model.is_gradient_checkpointing}")
更进一步,看看HF是如何在Bert模型内部实现梯度检查点的
modeling_bert.py中,定义了BertEncoder,其中forward函数内部判断是否开启了梯度检查点,并调用torch.utils.checkpoint.checkpoint实现梯度检查点
class BertEncoder(nn.Module):
def forward(args):
...
for i, layer_module in enumerate(self.layer):
...
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs, past_key_value, output_attentions)
return custom_forward
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(layer_module),
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
...
Xformers
xformers库仅适用于N卡,用于推理和训练中,在attention block中执行优化,可以提高速度并减少内存消耗。在图像生成领域,特点是加速图片生成并降低显存占用,代价是输出图像不稳定,有可能比不开Xformers略差。
self-attention在Transformer中发挥着重要的作用,但在实际应用中也面临着两个挑战:
(1) complexity:self-attention的时间复杂度是 O ( T 2 ⋅ D ) O(T^2·D) O(T2⋅D),在处理长序列问题上存在较大瓶颈。
(2) structural prior:self-attention没有对输入做输入做任何结构偏差的假设,因此对于小数据集可能存在过拟合现象。
xformers在Vanilla Transformer(普通transformer)的self-attention基础上进行改进:
-
Sparse attention :在计算attention matrix时不会attend 每个token,而是仅对部分sparse connection的位置计算。根据确定sparse connection的方法又可以细分为 position-based 和 content-based 两种。
-
Position-based Sparse Attention:

- Global Attention:为了缓解稀疏注意力在中长距离依赖关系上模型能力的退化,这一类模式增加了一些全局节点作为节点间信息传播的枢纽。这些全局节点可以关注序列中的所有节点,并且整个序列也都会关注这些全局节点。
- Band Attention:这一类attention 也可以成为局部attention或者滑动窗口attention,设计的主要思路在于,由于大部分的数据都有很强的局部关系特性,因此可以限制query只关注附近的一些节点从而做到稀疏化的效果。
- Dilated Attention:这种attention的方法与dilated CNN的方法十分相似,可以在不增加计算复杂度的情况下扩大感受野的大小,并且通过调整dilation 的间距可以扩展至strided attention.
- Random Attention:为了提高非局部位置之间的联系,每个query随机的选择一些位置去attend.
- Block Local Attention:将整个序列划分为几个没有重叠部分的block,每个block内部之间做attention.
-
Content-based sparse attention:
- Reformer:Reformer使用了Locality-sensitive hashing(LSH) 对每个query选择对应的key-value对。
- Route Transformer:相比于reformer,该方法采用了k-means聚类的方法对query和key进行聚类,每个query 只attend 属于同一类cluster的keys. 聚类中心的向量根据被赋予向量的指数移动平均值来计算,同时除以cluster中数目的移动平均值。
-
-
Linearized attention:
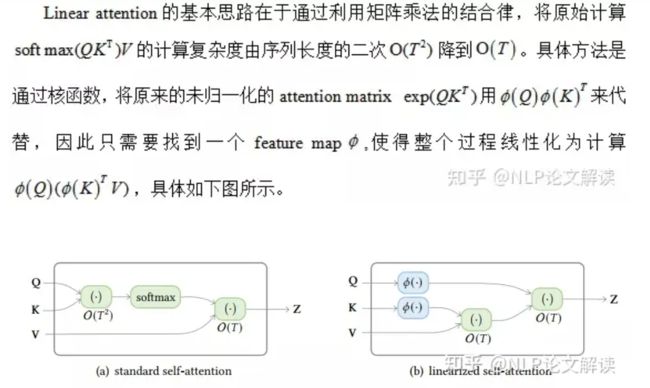
这里可将原始的指数内积的计算形式替换为核函数,从而提出新的计算方式,

对于自回归的attention而言,上式中的累积和项可以通过上一个时间步的结果计算叠加而来,因此对于transformer的decoder来说,整个计算过程类似于RNN的计算过程。
在Linear Transformer中,linear map采用了一种简单的计算方法,
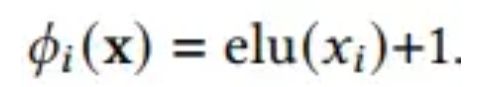
这种feature map的目的不是为了近似内积attention,但是通过实验证明它和标准的Transformer的结果表象相当。 -
Query Prototyping和memory Compression:除了使用sparse attention或者核函数的linearized attention外,另一个改进的思路就是减少query和key-value对的数量。
- Query Prototyping:如 Informer,编码器接收大量的长序列输入(绿色序列)。采用ProbSparse attention 来代替常规的self-attention。蓝色梯形是自注意力的蒸馏操作来提取主要的attention,大大减小了网络规模。层叠加复制副本的操作增加了鲁棒性。解码器接收长序列输入,将target中元素填充为零,根据特征图的加权注意力组成,立即以生成方式预测输出元素(橙色系列),从而使得Transformer能够更有效的处理长序列数据。
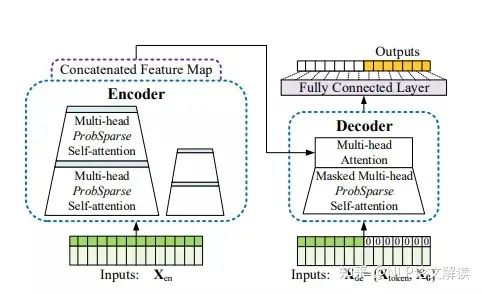

- Attention with Compressed Key-Value Memory:相比于减少query数量的方法,这一类方法的主要特点在于通过减少key-value对的数量来减少复杂度。
- Memory Compressed Attention(MCA):通过跨步卷积的方法来减少key和value的数量,减少的大小和kernel size k的数值有关,这种方法相比于之前提到局部注意力而言,增加了对全局上下文的捕捉。
- Linformer:利用线性投影将键和值从长度n投射到一个更小的长度的nk。这也将self attention的复杂性降低到线性。这种方法的缺点是必须假定输入序列的长度,因此不能用于自回归的问题上。
- PoolingFormer:将原始的全注意力机制修改为一个两级注意力机制:第一级采用滑动窗口注意力机制,限制每个词只关注近距离的邻居;第二级采用池化注意力机制,采用更大的窗口来增加每个token 的感受野,同时利用池化操作来压缩键和值向量,以减少要参加注意力运算的token数量。

- Query Prototyping:如 Informer,编码器接收大量的长序列输入(绿色序列)。采用ProbSparse attention 来代替常规的self-attention。蓝色梯形是自注意力的蒸馏操作来提取主要的attention,大大减小了网络规模。层叠加复制副本的操作增加了鲁棒性。解码器接收长序列输入,将target中元素填充为零,根据特征图的加权注意力组成,立即以生成方式预测输出元素(橙色系列),从而使得Transformer能够更有效的处理长序列数据。
-
多头机制的改进:多头注意力的一大优势在于它能够共同关注来自不同子空间的不同位置的信息。然而,目前还没有一种机制可以保证不同的注意头确实捕捉了不同的特征。

除此之外还有很多对Transformer的改进都集成进了xformers。xFormers 软件包需要最新版本的 PyTorch。如果需要使用以前版本的 PyTorch,那么我建议 从github souce 安装 xFormers。
xFormers安装后,diffusers的unet可以使用enable_xformers_memory_efficient_attention() 为了更快的推理和减少内存消耗:
if enable_xformers_memory_efficient_attention:
if is_xformers_available():
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
PyTorch 2.0相比1.12改变了很多底层实现,不向后兼容。所以不能在PyTorch 2.0上使用xFormers。但是可以使用这个机制:GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attention
更具体的直接使用xformers实现attention:
import torch
from xformers.ops import memory_efficient_attention, LowerTriangularMask
device='cuda'
batch = 4
n_head = 8
head_dim = 16
seq_len = 128
q = torch.rand(batch, seq_len, n_head, head_dim).to(device)
k = torch.rand(batch, seq_len, n_head, head_dim).to(device)
v = torch.rand(batch, seq_len, n_head, head_dim).to(device)
# 使用 causal 偏置掩码
o = memory_efficient_attention(q, k, v, LowerTriangularMask())
# 不使用任何偏置掩码
o = memory_efficient_attention(q, k, v)
memory_efficient_attention 的等效pytorch代码实现,用于模型导出。注:LowerTriangularMask 之类的掩码请另外手动生成一个等效的 attn_bias Tensor 再用于本函数
# 使用自定义的偏置掩码 attn_bias,要求 xformers 版本 大于等于 0.17
## 这里的 from_len,to_len 分别代表Decoder的序列长度,Encoder的序列长度
from_len = seq_len
to_len = seq_len
attn_bias = torch.rand(batch, n_head, from_len, to_len).to(device)
o = memory_efficient_attention(q, k, v, attn_bias)
import torch.nn.functional as F
def memory_efficient_attention_pytorch(query, key, value, attn_bias=None, p=0., scale=None):
# query [batch, seq_len, n_head, head_dim]
# key [batch, seq_len, n_head, head_dim]
# value [batch, seq_len, n_head, head_dim]
# attn_bias [batch, n_head, seq_len, seq_len]
if scale is None:
scale = 1 / query.shape[-1] ** 0.5
# BLHC -> BHLC
query = query.transpose(1, 2)
key = key.transpose(1, 2)
value = value.transpose(1, 2)
# scale query
query = query * scale
# BHLC @ BHCL -> BHLL
attn = query @ key.transpose(-2, -1)
if attn_bias is not None:
attn = attn + attn_bias
attn = attn.softmax(-1)
attn = F.dropout(attn, p)
# BHLL @ BHLC -> BHLC
out = attn @ value
# BHLC -> BLHC
out = out.transpose(1, 2)
return out
Diffusers的显存优化
-
vae.enable_vae_slicing():将按顺序对每个prompt对应的隐变量进行解码,而不是同时解码整个batch。可以大大减少GPU内存使用,支持更大的batch size。需要 trade-off 推理时间和显存需求。 -
vae.enable_vae_tiling():在有限VRAM的情况下处理大尺寸图像。例如,在8GB VRAM中生成4K图像。分块VAE解码器将图像分割成重叠的块,对每个块解码,最后将输出混合生成最终图像。输出图像由于块解码器独立,会有一些块间色调变化,但不会出现明显的块间裂缝。512x512或以下大小的图像不会进行分块。分块VAE适用于大尺寸图像的生成,可以突破VRAM限制。需要 trade-off patch的调色差异和显存需求。 -
pipeline.enable_sequential_cpu_offload():为进一步节省内存,底层使用accelerate,可以将权重offload到CPU,仅在执行前向传播时加载到GPU。注意,此方法在子模块级别工作,而不是整个模型级别(如每次卸载Unet的一个Conv层)。这是最小化内存消耗的最佳方式,但由于过程的迭代特性,推理速度会大大降低。管道的UNet组件会运行多次(和num_inference_steps一样多次);每次UNet的不同子模块会按需要顺序地在CPU和GPU之间加载和卸载,所以内存传输的次数非常大。 -
pipeline.enable_model_cpu_offload():顺序CPU卸载可以节省大量内存,但会降低推理速度,因为子模块在需要时移动到GPU,在新模块运行时立即返回CPU。全model卸载是sequential卸载另一种替代方案,它按整个模型,而不是每个模型的组成模块来移动到GPU(如每次卸载整个Unet)。这对推理时间几乎没有影响,在这种场景下,pipeline的主要组件(通常是:文本编码器、UNet和VAE)中只有一个处于GPU,其他组件等在CPU。像UNet这样运行多次迭代的组件会一直留在GPU,直到不再需要为止。
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"/data1/huggingface/StableDiffusion/stable-diffusion-v1-5", torch_dtype=torch.float16
)
pipe = pipe.to("cuda")
pipe.enable_model_cpu_offload() # new diffusers
pipe.unet.enable_xformers_memory_efficient_attention()
pipe.enable_vae_slicing()
pipe.enable_vae_tiling() # new diffusers
pipe.enable_attention_slicing()
prompt = "a photo of an astronaut riding a horse on mars"
images = pipe([prompt] * 32).images # sample 32 images