【论文笔记】HetGNN
Heterogeneous Graph Neural Network
2019 KDD
论文链接:https://dl.acm.org/doi/pdf/10.1145/3292500.3330961
官方代码:https://github.com/chuxuzhang/KDD2019_HetGNN
个人实现:https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/hetgnn
1.引言
(本文研究的)异构图不仅包含多个类型的顶点之间的结构化关联(边),还包含与每个顶点关联的非结构化内容
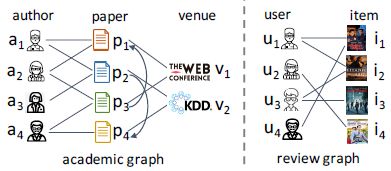
例如:
- 学术图包含学者、论文和期刊三种顶点,“作者-写-论文”、“论文-引用-论文”和“论文-发表于-期刊”三种边,另外,学者顶点还包含id(属性),论文顶点包含摘要(文本),这里的属性和文本就是非结构化内容
- 评论图包含用户和物品两种顶点,“用户-评论-物品”一种边,另外,用户顶点还包含id(属性),物品顶点还包含简介(文本)和图片(图像),这里的属性、文本和图像就是非结构化内容
尽管在同构或异构图嵌入、属性图嵌入以及图神经网络等方面已经有了大量的研究,但很少有研究能同时考虑异构结构信息(顶点和边)和异构内容信息(属性、文本、图像等)
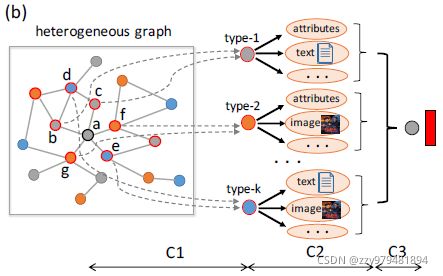
论文中总结了异构图嵌入面临的挑战
- (C1) 如何为每个顶点采样与它们的嵌入生成强相关的异构邻居?
- (C2) 如何编码顶点内容,解决异构图中不同顶点的内容异构?
- (C3) 考虑不同的顶点类型对顶点嵌入的影响,如何聚集异构邻居的特征信息?
为了解决以上挑战,论文提出了HetGNN——用于异构图表示学习的异构图神经网络模型
2.问题定义
(1)内容相关的异构图
内容相关的异构图是指具有多种顶点类型和边类型的图 G = ( V , E , O V , R E ) G=(V, E, O_V, R_E) G=(V,E,OV,RE) ,其中 O V O_V OV 和 R E R_E RE 分别表示顶点和边的类型集合,另外,每个顶点还关联了异构内容(例如属性、文本、图像等)
前面提到的学术图和评论图都是内容相关的异构图的例子
(2)异构图表示学习
给定一个内容相关的异构图 G = ( V , E , O V , R E ) G=(V, E, O_V, R_E) G=(V,E,OV,RE) ,顶点内容集合为C,目标是设计一个模型 F : V → R d F: V→R^d F:V→Rd 来学习一个d维嵌入,该嵌入能够同时对异构结构信息(顶点和边)和异构非结构信息(内容)进行编码
学习到的顶点嵌入可用于多种图挖掘任务,例如连接预测、推荐、顶点分类等
3.HetGNN模型
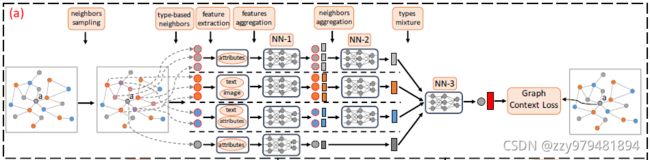
模型包括4部分:
- 采样异构邻居(C1)
- 顶点的异构内容嵌入(C2)
- 聚集异构邻居(C3)
- 目标函数和模型训练
每一部分的功能如下:
- 设计了一个基于重启策略的随机游走方法,来为异构图中的每一个顶点采样固定数量的强相关的异构邻居
- 设计了一个异构图神经网络来根据顶点类型对采样的邻居进行分组,包含两个模块:
- 第一个模块使用RNN来编码异构内容的“深度”特征交互,从而得到每个顶点的内容嵌入
- 第二个模块使用另一个RNN来聚集不同的邻居组(类型)的内容嵌入,从而得到这个类型的特征表示;之后通过注意力机制来衡量不同异构顶点类型的影响,将它们组合起来,获得最终的顶点嵌入
- 最后,利用一个图上下文损失函数和小批量梯度下降方法来训练模型
模型的整体结构如下图所示
3.1 采样异构邻居(C1)
用于同构图的GNN通过顶点的直接邻居来聚集特征信息,这种做法在异构图中会产生几个问题:
- 异构图中的直接邻居可能只有部分类型的顶点(例如学术图中学者顶点的直接邻居只有论文顶点),学习出来的顶点嵌入缺乏表示能力
- 每个顶点的邻居数量可能差别很大
- 异构邻居不同的内容特征需要使用不同的特征变换来处理
为了解决以上问题以及挑战C1,论文提出了基于重启随机游走(RWR)的异构邻居采样策略
- 第1步:采样固定长度的RWR。从任意顶点v开始随机游走,游走的过程会重复地经过v的邻居或者以一个概率p返回初始顶点。RWR在收集到固定数量的邻居顶点后会停止,记为RWR(v)。采样序列中不同类型的顶点数量是受限的,从而确保采样到的邻居包含了所有类型的顶点。
- 第2步:将不同类型的邻居分组。对于每个顶点类型t,根据频率选出top k个顶点作为v的t类型邻居集合 N t ( v ) N_t(v) Nt(v)
该策略避免了上面提到的问题:
- RWR为每个顶点收集了所有类型的邻居
- 采样的邻居数量是固定的,选择的是最频繁访问的邻居顶点
- 相同类型(有相同的内容特征)的顶点被分组,从而可以使用基于类型的聚集
3.2 顶点的异构内容嵌入(C2)
为了解决挑战C2,论文中设计了一个模块用于将顶点v的异构内容 C v C_v Cv 通过一个神经网络 f 1 f_1 f1 编码为固定长度的嵌入,如下图所示
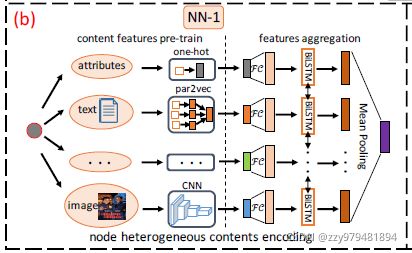
首先根据不同内容的类型使用不同的方法进行预训练(例如属性内容使用one-hot编码,文本内容使用Par2Vec,图像内容使用CNN),将顶点v的第i个内容的特征表示记为 x i ∈ R d f × 1 , 1 ≤ i ≤ ∣ C v ∣ x_i∈R^{d_f×1},1≤i≤|C_v| xi∈Rdf×1,1≤i≤∣Cv∣
之后使用双向LSTM来聚集顶点v的异构内容特征,最后将LSTM层输出的隐含状态输入到一个mean-pooling层(即取平均),从而得到顶点v的总体异构内容嵌入 f 1 ( v ) f_1(v) f1(v)
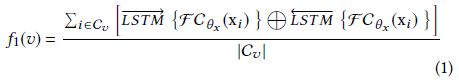
其中FC是一个特征转换层,可以是恒等变换、全连接层等
简单来说就是:内容编码→ x i x_i xi →双向LSTM→取平均→ f 1 ( v ) f_1(v) f1(v)
这个内容编码框架有如下优点:
- 复杂度相对较低(参数少),因此实现模型和调参都相对容易
- 之前的模型直接将不同类型的内容特征拼接为一个向量,而该模型使用了双向LSTM来捕获“深度”特征交互,能够融合异构内容信息,从而获得更强的表示能力
- 添加额外的内容特征很灵活,模型方便拓展
3.3 聚集异构邻居(C3)
为了解决挑战C3,论文中设计了另一个模块——基于类型的神经网络来聚集异构邻居的内容嵌入
该模块包括两步:
- 同类型邻居聚集
- 类型组合
3.3.1 同类型邻居聚集
在3.1节中通过RWR每个顶点的所有类型的邻居,这一步使用一个神经网络 f 2 t f_2^t f2t (注意和类型t相关)来聚集每个顶点v的t类型邻居 N t ( v ) N_t(v) Nt(v) 的内容嵌入

该神经网络的结构与3.2节中的类似,使用双向LSTM来聚集每个邻居v’的内容嵌入 f 1 ( v ′ ) f_1(v') f1(v′) ,最后将LSTM层输出的隐含状态输入到一个mean-pooling层(即取平均),从而得到顶点v的t类型邻居的聚集嵌入 f 2 t ( v ) f_2^t (v) f2t(v)
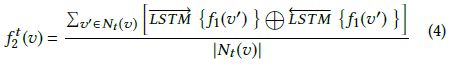
对于不同顶点类型的邻居使用不同的双向LSTM来聚集
3.3.2 类型组合
前一步对每个顶点v生成了 ∣ O V ∣ |O_V| ∣OV∣ 个聚集嵌入 f 2 t ( v ) , t ∈ O V f_2^t (v),t∈O_V f2t(v),t∈OV ,这一步使用注意力机制来组合基于类型的邻居嵌入,如下图所示

使用注意力机制的动机是不同类型的邻居会对顶点v的最终嵌入表示有不同的贡献,用 α v , t \alpha ^{v, t} αv,t 表示t类型的邻居对顶点v的注意力权重,则顶点v的最终嵌入表示为
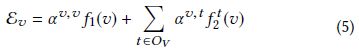
(这里的 E v \mathcal{E}_v Ev 就是第2节提到的F)
α v , t \alpha ^{v, t} αv,t 的计算公式如下:

其中 F ( v ) = { f 1 ( v ) } ∪ { f 2 t ( v ) ∣ t ∈ O V } F(v)=\{ f_1 (v) \} \cup \{ f_2^t (v) | t \in O_V \} F(v)={f1(v)}∪{f2t(v)∣t∈OV}
(就是对基于类型的邻居嵌入使用GAT)
3.4 目标函数和模型训练
目标函数定义如下:
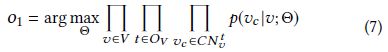

C N v t {CN}_v^t CNvt 表示顶点v的t类型上下文顶点
注意 o 1 o_1 o1 不是误差函数而是似然函数,因此是最大化, v c v_c vc 来自顶点v的随机游走结果,因此该目标函数的含义是使得随机游走结果出现的概率最大
论文中使用负采样技术来优化目标函数 o 1 o_1 o1 ,具体做法是对于顶点v的每一个t类型的邻居 v c v_c vc ,从噪声分布 P t ( v c ) P_t(v_c) Pt(vc) 中采样一个负样本 v c ′ v_{c'} vc′ ,则 log p ( v c ∣ v ; Θ ) \log p(v_c|v;\Theta) logp(vc∣v;Θ) 的估计退化为交叉熵损失
![]()
因此目标函数(7)转化为
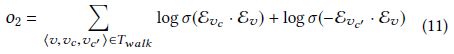
4.实验
实验目的是回答4个问题:
- (RQ1) HetGNN和SOTA基准模型相比在图挖掘任务上的表现如何,包括
- (RQ1-1) 连接预测
- (RQ1-2) 个性化推荐
- (RQ1-3) 顶点分类/聚类
- (RQ2) HetGNN和SOTA基准模型相比在归纳性(inductive)图挖掘任务上的表现如何
- (RQ3) HetGNN的不同组成部分(例如3.2异构内容编码器、3.3异构邻居聚集器)对模型性能有什么影响
- (RQ4) 各超参数(例如嵌入维度、异构邻居采样数量)对模型的性能有什么影响
4.1 实验设计
4.1.1 数据集
论文使用了4个异构图数据集,包括两个学术图和两个评论图
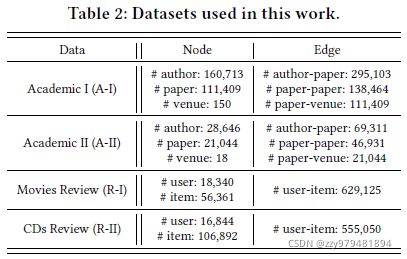
学术图数据集来自AMiner,评论图数据来自Amazon
4.1.2 Baseline
- metapath2vec:异构图嵌入模型,使用基于metapath的游走和异构skipgram模型来学习顶点的嵌入表示
- ASNE:属性图的嵌入模型,利用顶点的隐含特征和属性特征来学习顶点的嵌入表示
- SHNE:带文本属性的异构图的嵌入模型,通过联合优化图的结构相近度和文本语义相关度来学习顶点的嵌入表示
- GraphSAGE:图神经网络模型,使用神经网络来聚集顶点邻居的特征信息
- GAT:图神经网络模型,使用自注意力神经网络来聚集顶点邻居的特征信息
4.1.3 复现
嵌入维度为128,学术图的邻居采样数量为23(学者、论文、期刊分别为10, 10, 3),评论图的邻居采样数量为20(用户、物品各10)
使用Par2Vec预训练文本内容特征,使用CNN预训练图像内容特征,使用DeepWalk预训练顶点嵌入
学术图的输入顶点特征为文本(论文摘要)特征和预训练的顶点嵌入;评论图的输入顶点特征为文本(物品描述)特征、图片(物品照片)特征和预训练的顶点嵌入
使用PyTorch实现,代码:https://github.com/chuxuzhang/KDD2019_HetGNN
4.2 应用
4.2.1 连接预测(RQ1-1)
哪个连接关系会在将来出现?
将两个顶点的嵌入按元素相乘作为连接嵌入,训练一个二分类器来预测两个顶点之间是否存在一条边,结果如下
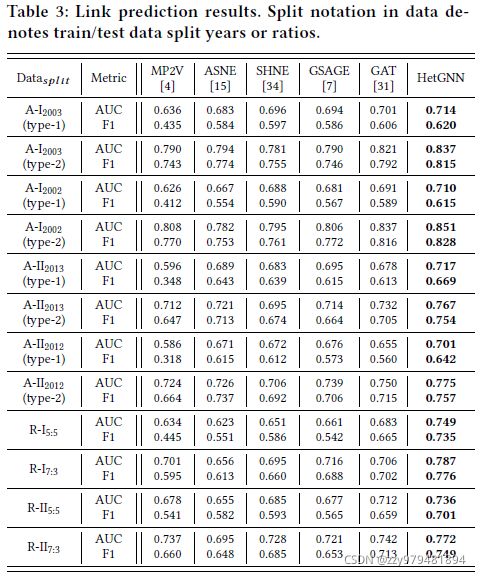
对于学术图,按年份划分训练集和测试集(例如对于A-I_2003,2003年之前的数据作为训练集,2003年及之后的数据作为测试集),预测的连接关系分为两种:type-1是学者之间的合作关系(学者1→论文←学者2),type-2是学者和论文之间的引用关系(学者→论文1→论文2)
对于评论图,按顺序划分训练集和测试集,预测的连接关系为用户和物品之间的评论关系
结果表明在连接预测任务上,HetGNN能学到比baseline更好的顶点嵌入
4.2.2 推荐(RQ1-2)
哪个顶点应该被推荐给目标顶点?
该任务实际上和连接预测很相似,偏好得分定义为两个顶点嵌入的内积
只使用学术图,目标是给学者推荐期刊(即预测“学者-期刊”连接关系),使用训练集学习顶点嵌入,使用测试集中学者发表过论文的期刊作为groud truth,仍然按年份划分,评价指标为top k推荐列表的准确率、召回率和F1得分,结果如下
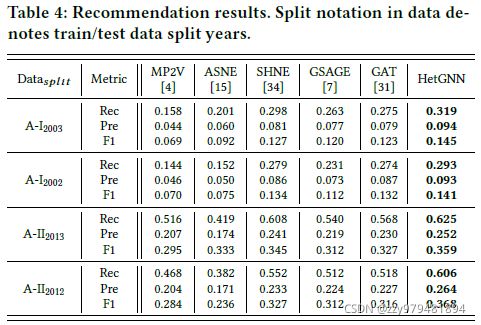
结果表明在顶点推荐任务上,HetGNN能学到比baseline更好的顶点嵌入
4.2.3 顶点分类和聚类(RQ1-3)
给定的顶点属于哪一个类别/类簇?
这部分包括多标签分类(MC)和顶点聚类(NC)两个任务
只使用A-II学术图,目标是将学者与4个人工选择的研究领域匹配:数据挖掘(DM)、计算机视觉(CV)、自然语言处理(NLP)和数据库(DB);另外,还为每个研究领域人工选择了top 3期刊(数据集中的顶点,相当于给这些期刊顶点人工指定领域)
每个学者的标签是发表论文最多的研究领域(通过论文所属的期刊),使用整个数据集来学习顶点嵌入
对于多标签分类任务,学习到的顶点嵌入用于训练逻辑回归分类器,评价指标为Micro-F1和Macro-F1;对于顶点聚类任务,学习到的顶点嵌入用于k-means算法的输入,评价指标为归一化的互信息(NMI)和adjusted rand index (ARI),结果如下
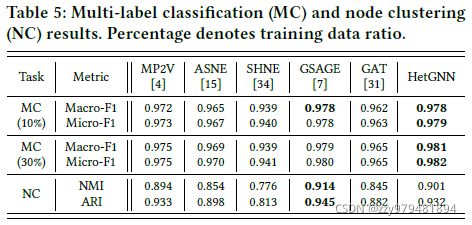
聚类结果的可视化如下
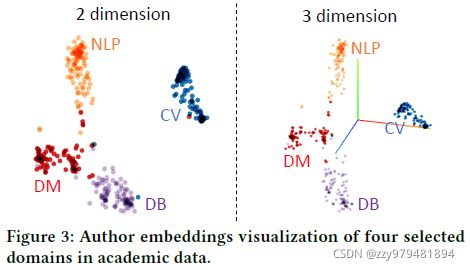
可以看到相同研究领域的学者嵌入距离较近,说明学习到的顶点嵌入有效
4.2.4 归纳式顶点分类和聚类(RQ2)
新顶点属于哪一个类别/类簇?
“归纳式”体现在没有预先学习到测试集中的顶点嵌入,需要使用训练好的模型来推断这些顶点的嵌入,之后进行顶点分类和聚类任务的测试
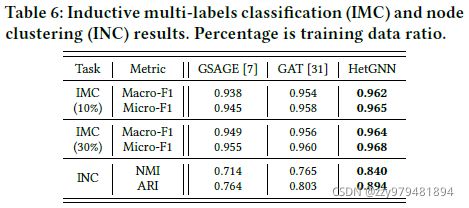
4.3 分析
4.3.1 消融实验(RQ3)
为了研究各组成部分对模型性能的影响,论文中将HetGNN模型和3个变体进行了比较:
- No-Neigh:不考虑邻居的影响,直接用异构内容嵌入f1(v)作为顶点嵌入
- Content-FC:把异构内容嵌入模块的Bi-LSTM换成了全连接神经网络
- Type-FC:把类型组合模块的注意力机制换成全连接层(把原本要加权的各个向量先连接起来,然后输入全连接层,得到顶点的嵌入)
HetGNN和这3个变体在A-II数据集的连接预测和顶点推荐任务上的表现如下
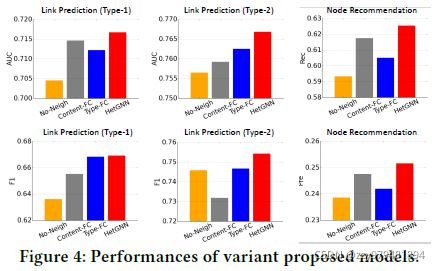
从图中可以得出以下结论:
- HetGNN比No-Neigh的性能好,证明聚集邻居信息有助于学习更好的顶点嵌入
- HetGNN比Content-FC的性能好,证明Bi-LSTM比“浅层”的全连接结构能更好地捕获“深度”特征交互
- HetGNN比Type-FC的性能好,证明自注意力机制比全连接层能更好地捕获顶点类型的影响
4.3.2 超参数敏感性(RQ4)
论文中分析了两个关键的超参数的影响:嵌入维度和异构邻居采样数量
不同超参数对HetGNN在A-II数据集的连接预测和顶点推荐任务上的性能影响如下

结果显示:
- 性能随嵌入维度的增大而提高,但过高会导致过拟合
- 性能随邻居采样数量的增大先提高后缓慢下降,原因是加入了弱相关邻居(噪声邻居)的负面影响,最优范围为20~30
5.相关工作
- 异构图挖掘
- 图表示学习
- 图神经网络
6.结论
- 本文正式定义了同时考虑同时考虑异构结构信息和异构内容信息的异构图表示学习问题
- 本文提出了一个异构图表示学习模型HetGNN,能够捕获结构和内容的异构,对于直推式(transductive)和归纳式(inductive)任务都很有用
- 本文在多个公共数据集上做了大量的实验,证明了HetGNN再连接预测、推荐、顶点分类和聚类、归纳性顶点分类和聚类等图挖掘任务上的性能优于SOTA方法