利用Python进行数据分析(Ⅰ)
利用Python进行数据分析(Ⅰ)
本文参考书籍:《利用Python进行数据分析》
目录
- 利用Python进行数据分析(Ⅰ)
-
- 1.准备工作
-
- 1.1重要的Python库
-
- NumPy
- pandas
- matplotlib
- IPython与Jupyter
- SciPy
- scikit-learn
- statsmodels
- 导入约定
- 术语
- 2.Python基础、IPython及Jupyter notebook
-
- 2.1 IPython基础
-
- 运行IPython命令行
- 运行Jupyter notebook
- 内省
- %run命令
-
- 中断运行中的代码
- 关于魔术命令
- matplotlib集成
- 2.2 Python基础
-
- 语言语义
-
- 一切皆为对象
- 变量和参数传递
- 标量类型
-
- 数值类型
- 字符串
- 类型转换
- None
- 日期和时间
- 控制流
-
- pass
- 3 内建数据结构、函数及文件
-
- 3.1数据结构和序列
-
- 元组
-
- 元组拆包
- 列表
-
- 连接和联合列表
- 排序
- 二分搜索和已排序列表的维护
- 切片
- 内建序列函数
-
- enumerate
- sorted
- zip
- reversed
- 字典
-
- 从序列生成字典
- 默认值
- 有效的字典键类型
- 集合
- 列表、集合和字典的推导式
-
- 嵌套列表推导式
- 3.2 函数
-
- 命名空间、作用域和本地函数
- 返回多个值
- 函数是对象
- 匿名(Lambda)函数
- 柯里化:部分参数应用
- 生成器
-
- 生成器表达式
- itertools模块
- 错误和异常处理
- 3.3 文件与操作系统
-
- 字节与Unicode文件
- 4 NumPy基础:数组与向量化计算
-
- 4.1 NumPy ndarray:多维数组对象
-
- 生成ndarray
- ndarray的数据类型
- NumPy数组算术
- 基础索引与切片
-
- 数组的切片索引
- 布尔索引
- 神奇索引
- 数组转置和换轴
- 4.2 通用函数:快速的逐元素数组函数
- 4.3 使用数组进行面向数组编程
-
- 将条件逻辑作为数组操作
- 数学和统计方法
- 布尔值数组的方法
- 排序
- 唯一值与其他集合逻辑
- 4.4 使用数组进行文件输入和输出
- 4.5 线性代数
- 伪随机数生成
1.准备工作
1.1重要的Python库
NumPy
NumPy(Numerical Python) 是Python数值计算的基石
它提供多种数据结构、算法以及大部分涉及Python数值计算所需的接口
Numpy还包括:
快速、高效的多维数组对象ndarray;
基于元素的数组计算或数组间数学操作函数;
用于读取硬盘中基于数组的数据集的工具;
线性代数操作、傅里叶变换及随机数生成;
pandas
pandas提供了高级数据结构和函数
pandas提供复杂的索引函数,使得数据的重组、切块、切片、聚合、子集选择更简单
pandas名字来源于panel data,是计量经济学中针对多维结构化数据集的术语。pandas也是Python data analysis的简写
matplotlib
制图与二维数据可视化
IPython与Jupyter
Jupyter提供交互性、探索性的环境
SciPy
Scipy是科学计算领域针对不同标准问题域的包集合
如:
scipy.integrate # 数值积分例程和微分方程求解器
scipy.linalg # 线性代数例程和基于numpy.linalg的矩阵分解
scipy.optimize # 函数优化器(最小化器)和求根算法
scipy.signal # 信号处理工具
scipy.sparse # 稀疏矩阵与稀疏线性系统求解器
scipy.stats # 标准的连续和离散概率分布(密度函数、采样器、连续
# 分布函数)、各类统计测试、各类描述性统计
scikit-learn
机器学习工具包
包含的子模块有:
分类:SVM、最近邻、随机森林、逻辑回归等
回归:Lasso、岭回归等
聚类:k-means、谱聚类等
降维:PCA、特征选择、矩阵分解等
模型选择:网络搜索、交叉验证、指标矩阵
预处理:特征提取、正态化
statsmodels
统计分析数据包
与scikit-learn相比,statsmodels包含经典的统计学、经济学算法。它所包含的模型包括:
回归模型:线性回归、通用线性模型、鲁棒线性模型、线性混合效应模型等
方差分析(ANOVA)
时间序列分析:AR、ARMA、ARIMA、VAR等模型
非参数方法:核密度估计、核回归
统计模型结果可视化
statsmodels更专注于统计推理,提供不确定性评价和p值参数。而scikit-learn更专注于预测
导入约定
Python社区对一些常用模块采用了命名约定
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import statsmodels as sm
术语
处理/处置/规整:
描述的是将非结构化或同时又很凌乱的数据整理成结构化、清晰形式的整个过程
2.Python基础、IPython及Jupyter notebook
2.1 IPython基础
运行IPython命令行

在IPython中仅输入一个变量名,它会返回一个表示该对象的字符串:
In [3]: import numpy as np
In [4]: data = {i: np.random.randn() for i in range(7)}
In [5]: data
Out[5]:
{0: -1.9717584214734714,
1: 0.26150785169015517,
2: 1.9317193339964511,
3: 1.1294835936372685,
4: -1.3337240345334922,
5: 1.3374786965820054,
6: -0.8457359561513423}
IPython中大多数Python对象被格式化为更可读的形式(较print打印而言)
IPython还提供执行任意代码块(通过复制粘贴实现)和整个Python脚本的功能
运行Jupyter notebook
Jupyter 项目中的主要组件就是notebook,这是一种交互式的文档类型,可以用于编写代码、文本(可以带标记)、数据可视化及其他输出。
在Anaconda Prompt中运行jupyter notebook命令打开
输入一行代码,按下shift+Enter执行
File-Save and Checkpoint会自动生成后缀名为.ipynb的文件
内省
在一个变量名后使用问号可显示关于该对象的概要信息

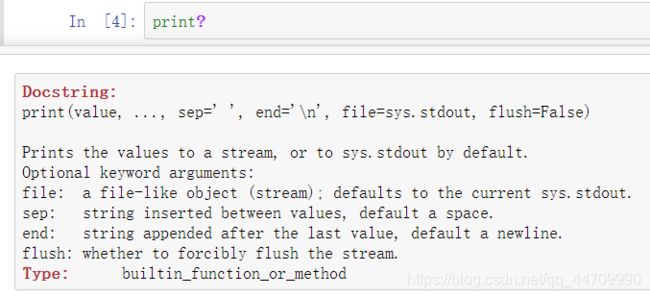
若对象是一个函数或实例方法且文档字符串已写好,则文档字符串将显示出来
使用?显示文档字符串:

使用??显示函数的源代码:

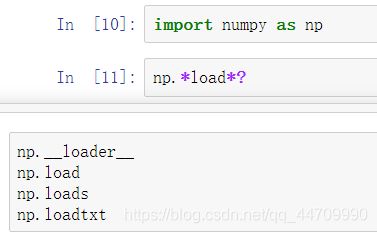
?还可以搜索IPython命名空间,把一些字符和通配符(*)结合,会显示所有匹配通配符表达式的命名:
如,可得到NumPy顶层函数中包含load的函数列表:
%run命令
可在IPython会话中使用%run命令运行任意的Python程序文件
%run hello_world.py
中断运行中的代码
Ctrl+C
关于魔术命令
IPython的特殊命令(未内建到Python自身中)被称为魔术命令
魔术命令的前缀符为%
%debug # 从最后发生报错的底部进入交互式调节器
%hist # 打印命令输入(也可打印输出)历史
%pdb # 出现任意报错后自动进入调试器
%run # 在IPython中运行一个Python脚本
%time # 报告单个语句的执行时间
%timeit # 多次运行单个语句计算平均执行时间
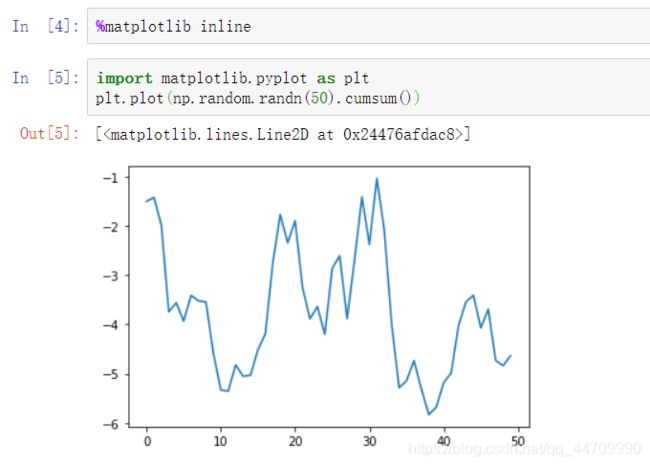
matplotlib集成
%matplotlib设置matplotlib与IPython命令行或Jupyter notebook的集成,不使用此条命令,创建的图将不会出现
在Jupyter中使用matplotlib:
2.2 Python基础
语言语义
一切皆为对象
每一个数值、字符串、数据结构、函数、类、模块以及所有存在于Python解释器中的事物,都是Python对象。每个对象都会关联到一种类型(如字符串、函数)和内部数据。
变量和参数传递
在Python中对一个变量(或变量名)赋值时,就创建了一个指向等号右边对象的引用

a,b指向了同一对象
标量类型
数值类型
整数除法会把结果自动转化为float,若需C风格的整数除非(舍弃小数部分),使用整除操作符//

字符串
对于含换行的多行字符串,可以使用三个单引号’’'或双引号"""
c="""
This is a longer string that
spans multiple lines
"""
Python的字符串是不可变的,无法修改一个字符串
很多函数可通过str函数转换为字符串

字符串格式化:
字符串对象拥有一个format方法,可用来代替字符串中的格式化参数,并产生一个新的字符串:
template = '{0:.2f} {1:s} are worth US${2:d}'
# {0:.2f}表示将第一个参数格式化为2位小数的浮点数
# {1:s}表示将第二个参数格式化为字符串
# {2:d}表示将第三个参数格式化为整数
将含有参数的序列传给format方法:

类型转换
str,bool,int,float既是数据类型,同时也是可以将其他数据转换为这些类型的函数:

None
None是Python的null值类型。
None可作为一个常用的函数参数默认值
def add_and_maybe_multiply(a, b, c=None):
result = a + b
if c is not None:
result = result * c
return result
日期和时间
内建的datetime模块,提供了datetime、date、time类型
strftime方法将datetime转换为字符串
字符串可通过strptime函数转换为datetime对象

在聚合或分组时间序列数据时,会常常用到替代datetime时间序列中的一些值,如将分钟、秒替换为0

两个不同的datetime对象会产生一个datetime.timedelta类型的对象:

输出的timedelta(days=17, seconds=7179)表示时间间隔为17天又7179秒
控制流
pass
pass用于在代码段表示什么都不做(由于缩进而存在)
if x < 0:
print('negative')
elif x == 0:
pass
else:
print('positive')
3 内建数据结构、函数及文件
3.1数据结构和序列
元组
元组固定长度,且不可变
可使用tuple函数将任意序列或迭代器转换为元组:

若元组中的一个对象是可变的,例如列表,可以在它内部进行修改:

可使用+号连接元组来生成更长的元组
将元组乘以整数,则会和列表一样,生成含有多份拷贝的元组

元组拆包
若将元组型的表达式赋值给变量,Python会对等号右边的值进行拆包

使用该功能可交换变量名

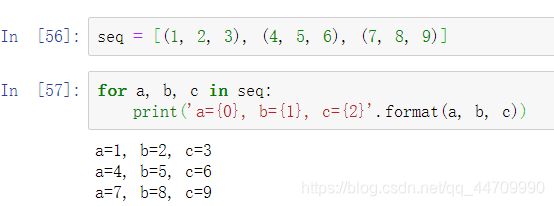
拆包的一个常用场景就是遍历元组或列表组成的序列:
列表
可使用[]或list类型函数定义列表

连接和联合列表
与元组类似,两个列表可通过+号连接

若有一个已经定义的列表,可用extend方法向该列表添加多个元素
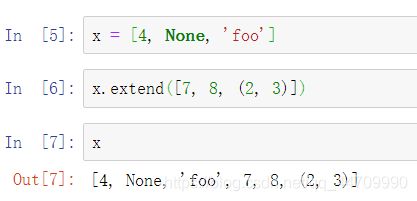
排序
调用列表的sort方法排序
a.sort()
sort的一个选项是传递一个二级排序key——一个用于生成排序值的函数。例如,可通过字符串的长度进行排序:

二分搜索和已排序列表的维护
内建的bisect模块实现了二分搜索和已排序列表的插值
bisect.bisect会找到元素应当被插入的位置,并保持序列排序,而bisect.insort将元素插入到相应位置

切片
步进值step可在第二个冒号后使用,意思是每隔多少个数取一个值
向步进传值-1可对列表或元组进行翻转

内建序列函数
enumerate
可使用enumerate函数在遍历一个序列的同时追踪当前元素的索引
enumerate返回(i,value)元组的序列,value为元素的值,i为元素索引
当需要对数据建立索引时,可使用enumerate构造一个字典,将序列值(假设唯一)映射到索引位置上:

sorted
排序
zip
zip将列表、元组或其他序列的元素配对,新建一个元组构成的列表:

zip可处理任意长度的序列,其生成列表长度由最短的序列决定:

zip的常用场景为同时遍历多个序列,有时会和enumerate同时使用:

给定一个已“配对”的序列时,zip可用于拆分序列:

reversed
reversed函数将序列的元素倒序排列
reversed是一个生成器,若没有实例化(例如使用list函数或进行for循环)的时候,并不能产生倒序列表

字典
可使用update方法将两个字典合并:
update方法改变了字典中元素位置,因此对于任何原字典中已存在的键,若传给update方法的数据也含有相同的键,则它的值将被覆盖

从序列生成字典
使两个序列在字典中按元素配对:

默认值
通常情况下,会有这样的代码逻辑:
if key in some_dict:
value = some_dict[key]
else:
value = default_value
字典的get方法和pop方法可返回一个默认值,因此上述代码块可简写为:
value = some_dict.get(key, default_value)
当需要将字典中的值集合通过设置,成为另一种集合,如列表时:
如将字词组成的列表根据首字母分类为包含列表的字典:
words = ['apple', 'bat', 'bar', 'atom', 'book']
by_letter = {}
for word in words:
letter = word[0]
if letter not in by_letter:
by_letter[letter] = [word]
else
by_letter[letter].append(word)
可使用字典的setdefault方法将上述循环改写为:
for word in words:
letter = word[0]
by_letter.setdefault(letter, []).append(word)
内建的集合模块有defaultdict类,想要生成符合要求的字典,可向字典中传入类型或能在各位置生成默认值的函数:
from collections import defaultdict
by_letter = defaultdict(list)
for word in words:
by_letter[word[0]].append(word)
有效的字典键类型
尽管字典的值可以是任何Python对象,但键必须是不可变的对象,比如标量类型(整数、浮点数、字符串)或元组(且元组内对象也必须是不可变对象)
为将列表作为键,一种方式是将其转换为元组

集合
集合是一种无序且元素唯一的容器。可认为集合也像字典,但只有键没有值。
集合有两种创建方式:通过set函数或用字面值集与大括号的语法

集合支持数学上的集合操作,如联合(并集)、交集、差集、对称差集
并集:union或 | 二元运算符
交集:intersection或 &

常用的集合方法列表:
a.add( x ) #将元素x加入集合a
a.clear() #将集合重置为空,清空所有元素
a.remove( x ) #从集合a中移除某个元素
a.pop() #移除任意元素,如果集合是空的抛出keyError
a.union(b) ( 或a|b ) #并
a.update(b) ( 或a|=b ) #将a的内容设置为a和b的并集
a.intersection(b) ( 或a&b ) #交
a.intersection_update(b) ( 或a&=b) #将a的内容设置为a和b的交
a.difference(b) ( 或a-b ) #集合差
a.difference_update(b) ( 或a-=b ) #将a的内容设置为a-b
a.symmetric_difference(b) ( 或a^b ) #所有在a或b中,但不是同时在
#a、b中的元素
a.symmetric_difference_update(b) ( 或a^=b )
a.issubset(b) #如果a包含于b返回True
a.issuperset(b) #如果a包含b返回True
a.isdisjoint(b) #a、b没有交集返回True
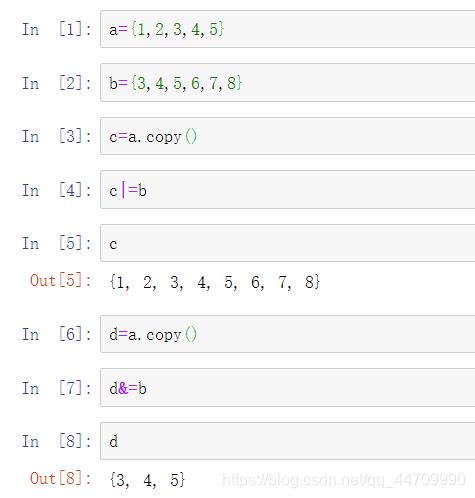
和字典类似,集合的元素必须是不可变的。如果想要包含列表型的元素,必须先转换为元组:


列表、集合和字典的推导式
列表推导式允许你过滤一个容器的元素,用一种简明的表达式转换给过滤器的元素,从而生成一个新的列表。列表推导式的基本形式为:
[expr for val in collection if condition]
这与下面的for循环等价:
result=[]
for val in collection:
if collection:
result.append( expr )
过滤条件是可以忽略的,只保留表达式。例如,给定一个字符串列表,我们可以过滤出长度大于2的,并且将字母改为大写:

集合与字典的推导式是列表推导式的自然拓展,用相似的方式生成集合与字典。字典推导式如下:
dict_comp={key-expr:value-expr for value in collection if condition}
集合推导式将中括号变为大括号
set_comp={expr for value in collection if condition}
若有一个字符串的列表,假设我们想要一个集合,集合里包含列表中字符串的长度:

也可使用map函数:
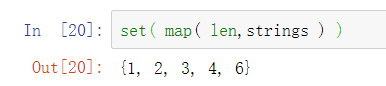
创建一个将字符串与其位置相匹配的字典:

嵌套列表推导式
假设有一个包含列表的列表,内容是英语姓名和西班牙语姓名:
![]()
获得一个列表包含所有含有2个以上字母e的名字:

列表推导式的for循环部分是根据嵌套的顺序排列的,所有的过滤条件像之前一样被放在尾部
将含有整数元组的列表扁平化为一个简单的整数列表:

创建一个包含列表的列表:

3.2 函数
命名空间、作用域和本地函数
返回多个值

函数是对象
假设我们正在做数据清洗,需要将一些变形应用到下列字符串列表中:
![]()
我们需去除空格,移除标点符号,调整适当的大小写。一种方式是使用内建的字符串方法,结合标准库中的正则表达式模块re:

另一种实现是将特定的列表操作应用到某个字符串的集合上:

可以将函数作为一个参数传给其他的函数,比如内建的map函数,可以将一个函数应用到一个序列上:

匿名(Lambda)函数
匿名函数是一种通过单个语句生成函数的方式,其结果是返回值。匿名函数使用Lambda关键字定义

假设想要根据字符串中不同字母的数量对一个字符串集合进行排序:

可以将一个匿名函数传给列表的sort方法:

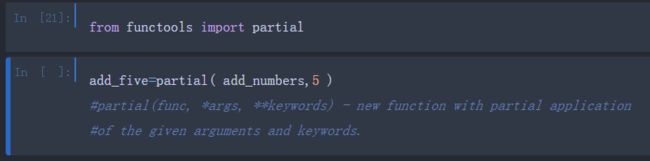
柯里化:部分参数应用
柯里化表示通过部分参数应用的方式从已有的函数中衍生出新的函数。假设我们有一个函数,其功能是将两个数加一起:
def add_numbers(x,y):
return x+y
使用这个函数,我们可以衍生出一个只有一个变量的新函数,add_five,可以给参数加上5:
add_five=lambda y:add_numbers(5,y)
第二个参数对于函数add_numers就是柯里化了。内建的functools模块可以使用pratial函数简化这种处理:
生成器
遍历一个字典,获得字典的键:

当你写下for key in some_dict语句时,Python解释器首先尝试根据some_dict生成一个迭代器:
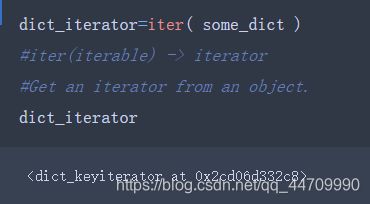
迭代器就是一种用于在上下文中(比如for循环)向python解释器生成对象的对象。大部分以列表或列表型对象为参数的方法都可以接收任意的迭代器对象。包括内建方法比如min、max和sum,以及类型构造函数比如list和tuple:

生成器是构造新的可遍历对象的一种非常简洁的方式。普通函数执行并一次返回单个结果,而生成器则“惰性”地返回一个多结果序列,在每一个元素产生之后暂停,直到下一个请求。如需创建一个生成器,只需要在函数中将返回关键字return替换为yield关键字

当实际调用生成器时,代码并不会立即执行:

直到你请求生成器中的元素时,它才会执行它的代码:

生成器表达式
用生成器表达式来创建生成器更为简单。生成器表达式与列表、字典、集合的推导式很类似,创建一个生成器表达式,只需要将列表推导式的中括号替换为小括号即可:
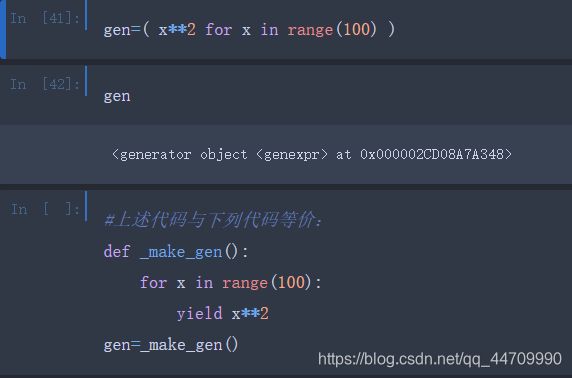
在很多情况下,生成器表达式可作为函数参数用于替代列表推导式:
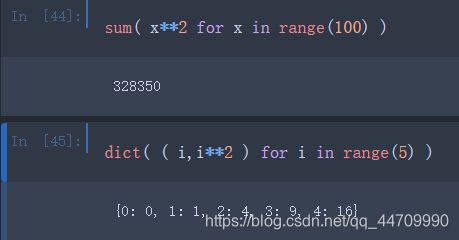
itertools模块
标准库中的itertools模块是适用于大多数数据算法的生成器集合。例如,groupby可以根据任意的序列和一个函数,通过函数的返回值对序列中连续的元素进行分组,如:

一些有用的itertools函数:
combinations( iterable,k )
#根据iterable参数中的所有元素生成一个包含所有可能K-元组的序列,忽略
#元组的顺序,也不进行替代(需要替代请参考函数combinations_with_replacement)
permutations( iterable,k )
#根据iterable参数中的所有元素按顺序生成包含所有可能K元组的序列
groupby( iterable[,keyfunc] )
#根据每一个独一的key生成(key,sub-iterator)元组
product( *iterables,repeat=1 )
#以元组的形式,根据输入的可遍历对象生成笛卡尔积,与嵌套的for循环类似
错误和异常处理
如果float(x)执行时出现了异常,则代码段中的except部分代码将会执行:

可以通过将多个异常类型写成元组的方式同时捕获多个异常(小括号必不可少):

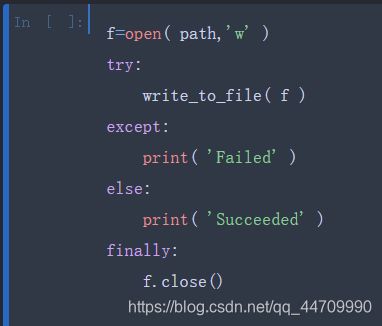
某些情况下,你可能想要处理一个异常,但是你希望一部分代码无论try代码块是否报错都要执行。为了实现这个目的,使用finally关键字:
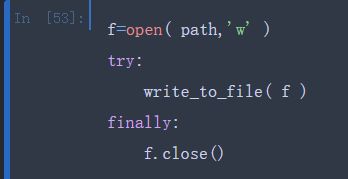
这样,我们可以让f在程序结束后总是关闭。类似地,可以使用else来执行当try代码块成功执行时才会执行的代码:
3.3 文件与操作系统
字节与Unicode文件
4 NumPy基础:数组与向量化计算
以下内容将会出现在NumPy中:
- ndarray,一种高效多维数组,提供了基于数组的便捷算术操作及灵活的广播功能
- 对所有数据进行快速的矩阵运算,而无须编写循环程序
- 对硬盘中数组数据进行读写的工具,并对内存映射文件进行操作
- 线性代数、随机数生成以及傅里叶变换功能
- 用于连接NumPy到C、C++语言类库的C语言API
4.1 NumPy ndarray:多维数组对象
一个ndarray是一个通用的多维同类数据容器,也就是说,它包含的每一个元素均为相同类型。每一个数组都有一个shape属性,用来表征数组每一维度的数量;每一个数组都有一个dtype属性,用来描述数组的数据类型:

生成ndarray
array函数接收任意的序列型对象(当然也包括其他的数组),生成一个新的包含传递数据的NumPy数组。

嵌套序列,例如同等长度的列表,将会自动转换成多维数组:

除非显式地指定,否则np.array会自动推断生成数组的数据类型。数据类型被存储在一个特殊的元数据dtype中
给定长度及形状后,zeros可以一次性创造全0数组,ones可以一次性创造全1数组。empty则可以创建一个没有初始化数值的数组。想要创建高维数组,则需要为shape传递一个元组:

arange是Python内建函数range的数组版:

由于NumPy专注于数值计算,如果没有特别指明,默认的数据类型是float64(浮点型),以下为标准数组的生成函数:
array
#将输入数据(可以是列表、元组、数组以及其他序列)转换为ndarray,
#如不显式指明数据类型,将自动推断;默认复制所有的输入数据
asarray
#将输入转换为ndarray,但如果输入已经是ndarray则不再复制
arange
#Python内建函数range的数组版,返回一个数组
ones
#根据给定形状和数据类型生成全1数组
ones_like
#根据所给的数组生成一个形状一样的全1数组
zeros
#根据给定形状和数据类型生成全0数组
zeros_like
empty
#根据给定形状生成一个没有初始化数值的空数组
empty_like
full
#根据给定的形状和数据类型生成指定数值的数组
full_like
eye,identity
#生成一个N x N特征矩阵(对角线位置都是1,其余位置是0)
ndarray的数据类型
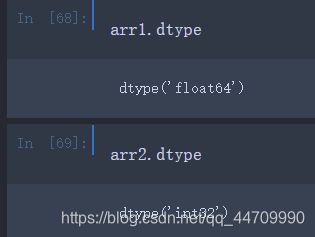
可以使用astype方法显式地转换数组的数据类型:

如果有一个数组,里面的元素都是表达数字含义的字符串,也可以通过astype将字符串转换为数字:

NumPy数组算术
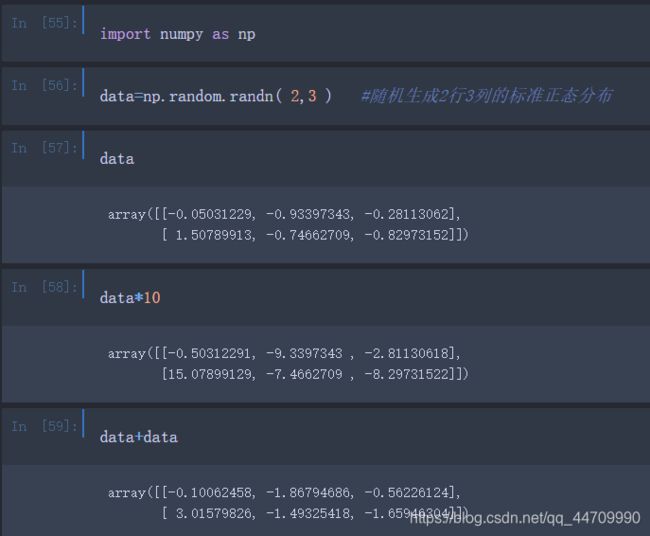
任何在两个等尺寸数组之间的算术操作都应用了逐元素操作的方式:

带有标量计算的算术操作,会把计算参数传递给数组的每一个元素:

同尺寸数组之间的比较,会产生一个布尔值数组:

基础索引与切片
一维数组:

若传入了一个数值给数组的切片,例如arr[5:8]=12,数值被传递给了整个切片。区别于Python的内建列表,数组的切片是原数组的视图。这意味着数据并不是被复制了,任何对于视图的修改都会反映到原数组上
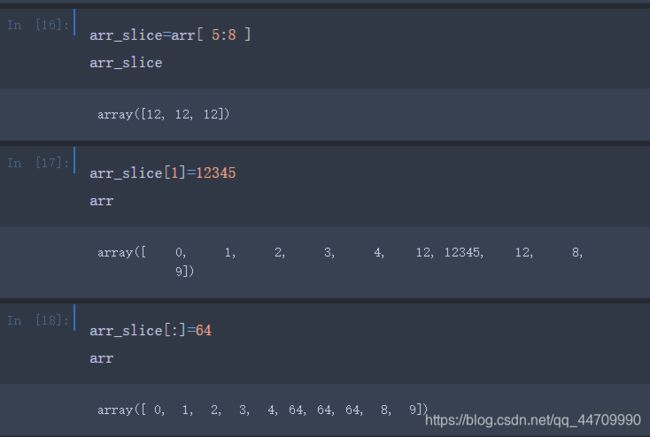
如果想要一份数组切片的拷贝而不是一份视图,必须显式地复制这个数组,例如arr[5:8].copy()
在一个二维数组中,每个索引值对应的元素不再是一个值,而是一个一维数组:
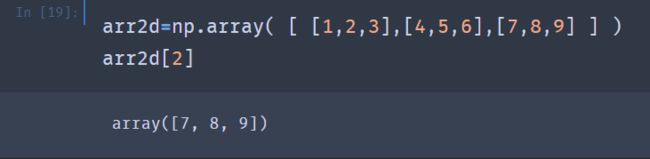
可以通过传递一个索引的逗号分隔列表去选择单个元素,以下两种方式效果一样:
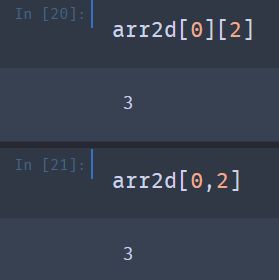
在多维数组中,可以省略后续索引值,返回的对象是降低一个维度的数组。因此在一个2x2x3的数组arr3d中:

标量和数组都可以传递给arr3d[0]:

arr3d[1,0]返回的是一个一维数组:
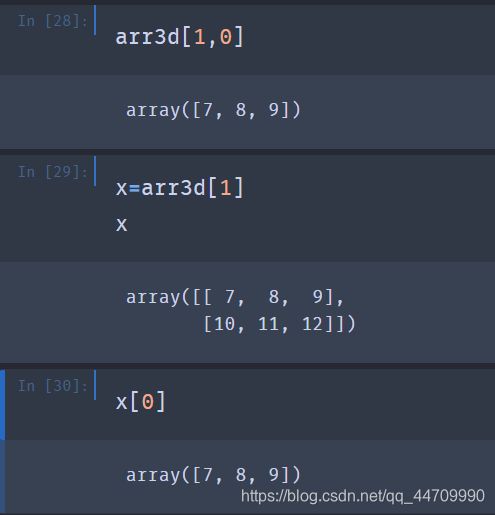
数组的切片索引


可以进行多组切片,与多组索引类似:


布尔索引
假设数组中的数据是一些存在重复的人名。使用numpy.random中的randn函数生成一些随机正态分布的数据:
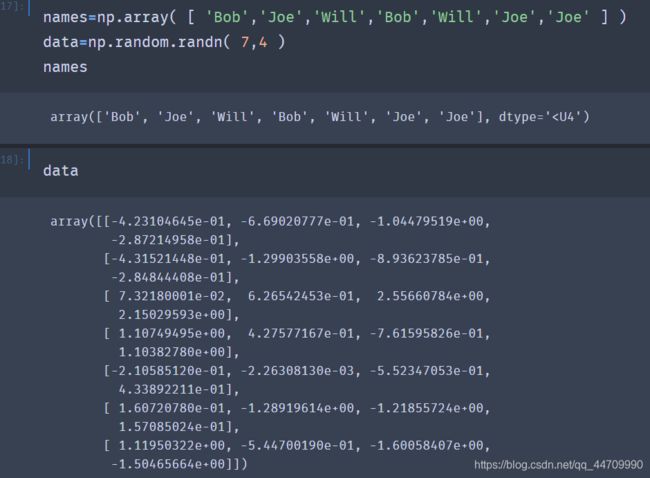
假设每个人名都和data数组中的一行相对应,并且我们想要选中所有‘Bob’对应的行。数组的比较操作(如==)也是可以向量化的。因此,比较names数组和字符串‘Bob’会产生一个布尔值数组:

在索引数组时可以传入布尔值数组

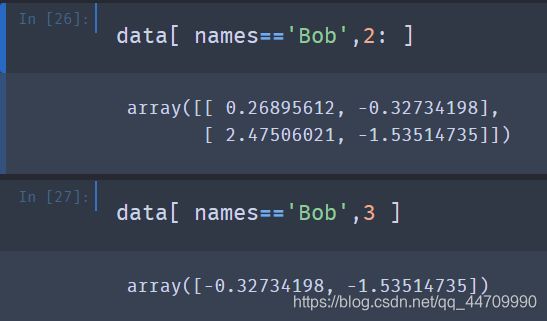
为了选择除了‘Bob’以外的其他数据,可以使用!=或在条件表达式前使用~对条件取反:
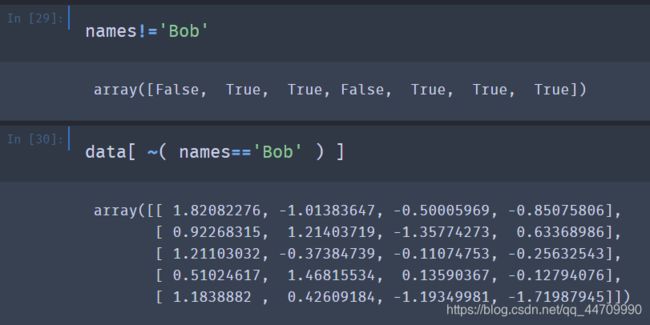
~符号可以在你想要对一个通用条件进行取反时使用:

当要选择三个名字中的两个来组合多个布尔值条件时,需要使用布尔算术运算符,如&和|:

使用布尔值索引选择数据时,总是生成数据的拷贝
将data中所有的负值设置为0:

利用一维布尔值数组对每一行或每一列设置数值:

神奇索引
神奇索引用于描述使用整数数组进行数据索引
假设我们有一个8x4的数组:

为了选出一个符合特定顺序的子集,可以通过传递一个包含指明所需顺序的列表或数组来完成:
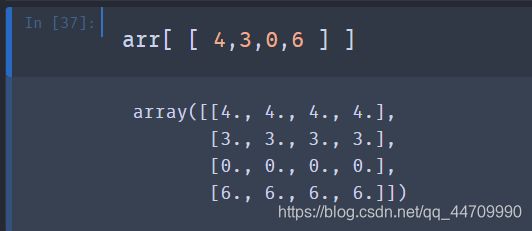
如果使用负的索引,将从尾部进行选择:

若传递多个索引数组,将根据每个索引元组对应的元素选出一个一维数组:
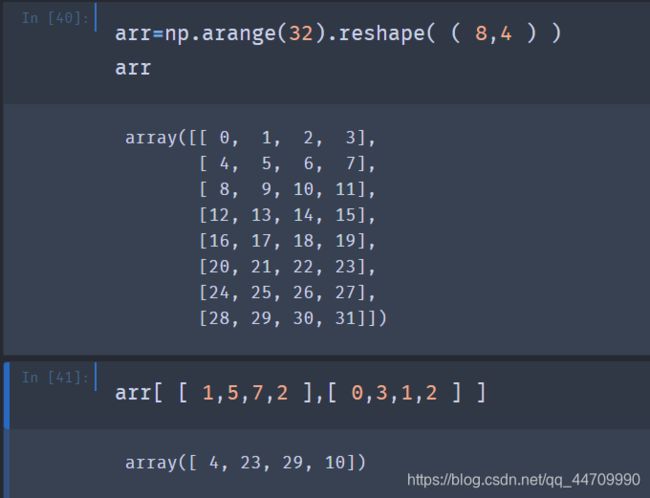
选择矩阵中行列的子集所形成的矩形区域:

注意神奇索引与切片不同,它总是将数据复制到一个新的数组中
数组转置和换轴
数组拥有transpose方法,也有特殊的T属性:

当计算矩阵内积会使用np.dot:

对于更高维度的数组,transpose方法可以接收包含轴编号的元组,用于置换轴:

ndarray有一个swapaxes方法,该方法接收一对轴编号作为参数,并对轴进行调整用于重组数据:

swapaxes返回的是数据的视图,而没有对数据进行复制
4.2 通用函数:快速的逐元素数组函数
通用函数,也可以称为ufunc,是一种在ndarray数据中进行逐元素操作的函数。某些简单函数接收一个或多个标量数值,并产生一个或多个标量结果,而通用函数就是对这些简单函数的向量化封装
有很多ufunc是简单的逐元素转换,比如sqrt或exp函数:

这些是所谓的一元通用函数。还有一些通用函数,比如add或maximum则会接收两个数组并返回一个数组作为结果,因此称为二元通用函数:
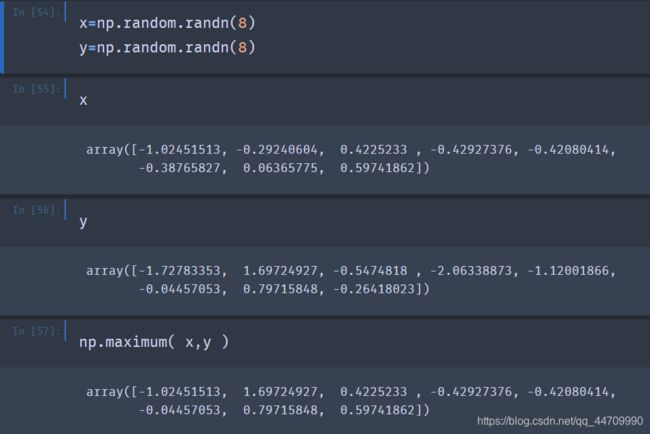
这里,numpy.maximum逐个元素地将x和y中元素的最大值计算出来
也有一些通用函数返回多个数组,比如modf,是python内建函数divmod的向量化版本。它返回了一个浮点值数组的小数部分和整数部分:
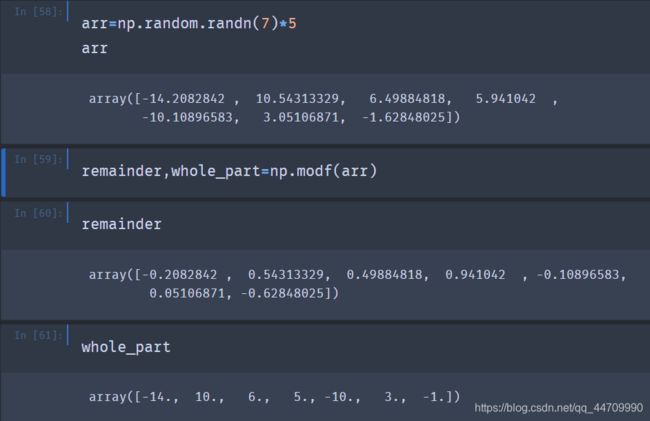
通用函数接收一个可选参数out
out : ndarray, None, or tuple of ndarray and None, optional
A location into which the result is stored. If provided, it must have a shape that the inputs broadcast to. If not provided or None,
a freshly-allocated array is returned. A tuple (possible only as a
keyword argument) must have length equal to the number of outputs.
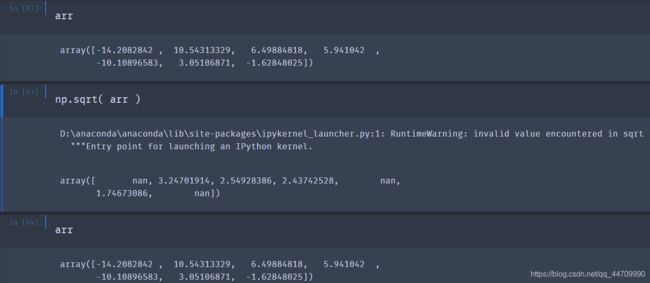

一元通用函数:


4.3 使用数组进行面向数组编程
假设我们想要对一些网格数据来计算函数sqrt(x^2+y ^2)的值。np.meshgrid函数接收两个一维数组,并根据两个数组的所有(x,y)对生成一个二维矩阵:
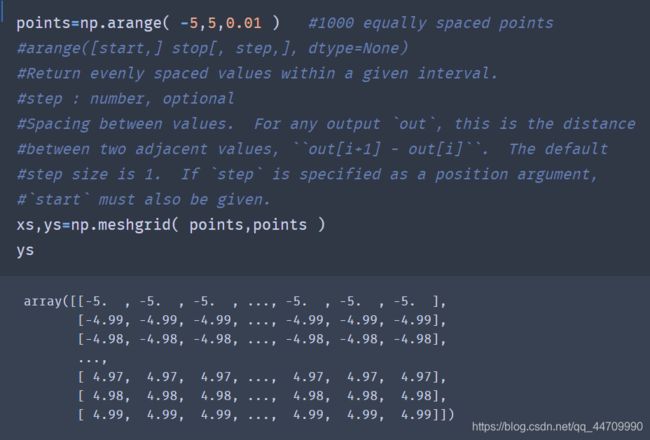


使用matplotlib函数imshow根据函数值的二维数组生成一个图像:

将条件逻辑作为数组操作
numpy.where函数是三元表达式x if condition else y的向量化版本。假设我们有一个布尔值数组和两个数值数组:

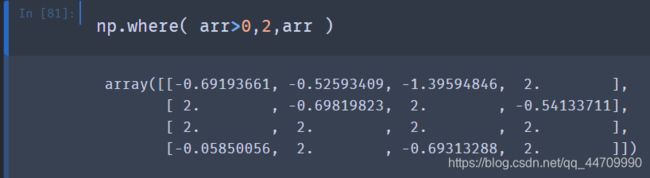
np.where的第二个和第三个参数并不需要是数组,它们可以是标量。where在数据分析中的一个典型用法是根据一个数组来生成一个新的数组。假设有一个随机生成的矩阵数据,并且想将其中的正值都替换为2,将所有的负值替换为-2:

可以使用np.where将标量和数组联合,例如,将arr中所有正值替换为常数2:
数学和统计方法
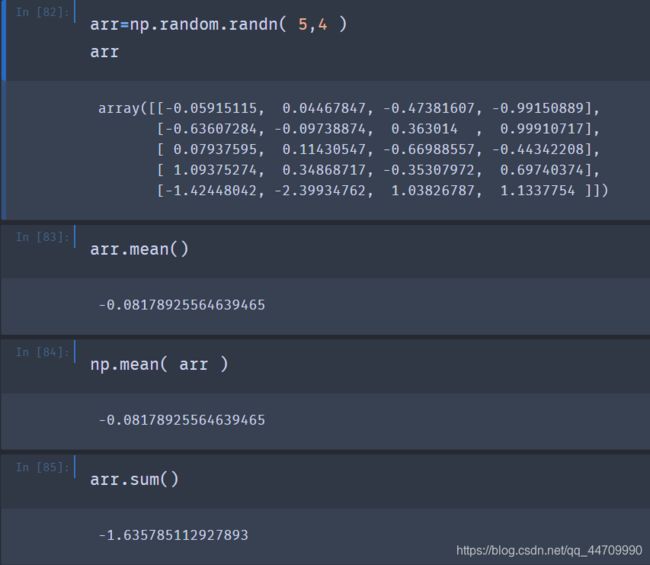
像mean、sum等函数可以接收一个可选参数axis,这个参数可以用于计算给定轴向上的统计值,形成一个下降一维度的数组:

其他的方法,例如cumsum和cumprod并不会聚合,它们会产生一个中间结果:

在多维数组中,像cumsum这样的累积函数返回相同长度的数组,但是可以在指定轴向上根据较低维度的切片进行部分聚合:

以下为基础数组统计方法:

布尔值数组的方法
sum可以计算布尔值数组中的True的个数:

对于布尔值数组,any检查数组中是否至少有一个True,而all检查是否每个值都是True:

这些方法也可以用于非布尔值数组,所有的非0元素都会按True处理
排序

可以在多维数组中根据传递的axis值,沿着轴向对每个一维数据段进行排序:

顶层的np.sort方法返回的是已经排序好的数组拷贝,而不是对原数组按位置排序
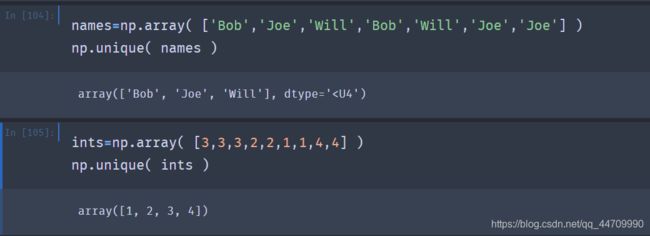
唯一值与其他集合逻辑
NumPy包含一些针对一维ndarray的基础集合操作。np.unique返回的是数组中唯一值排序后形成的数组:
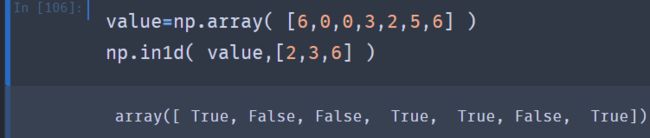
np.in1d可以检查一个数组中的值是否在另外一个数组中,并返回一个布尔值数组:
下列为NumPy中的集合函数:

4.4 使用数组进行文件输入和输出
NumPy可以在磁盘中将数据以文本或二进制文件的形式进行存入硬盘或由硬盘载入。np.save和np.load是高效存取硬盘数据的两大工具函数。数组在默认情况下是以未压缩的格式进行存储的,后缀名是.npy。如果文件存放路径中没写.npy时,后缀名会被自动加上。硬盘上的数组可以使用np.load进行载入:
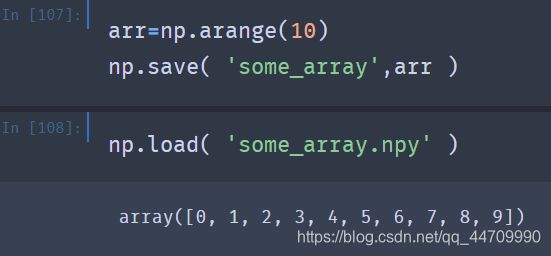
可以使用np.savez并将数组作为参数传递给该函数,用于在未压缩文件中保存多个数组。当载入一个.npy文件的时候,会获得一个字典型的对象,并通过该对象载入单个数组

若数据已经压缩好,可使用numpy.savez_compressed将数据存入已经压缩的文件:

4.5 线性代数
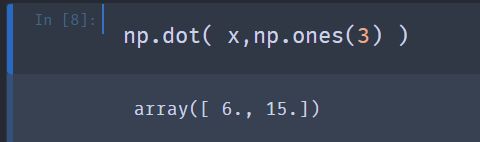
NumPy的线性代数中,*是矩阵的逐元素乘积,而不是矩阵的点乘积。因此NumPy的数组方法和numpy命名空间中都有一个函数dot,用于矩阵的操作:


一个二维数组和一个长度合适的一维数组之间的矩阵乘积,其结果是一个一维数组:
特殊符号@也作为中缀操作符,用于点乘矩阵操作:

numpy.linalg拥有一个矩阵分解的标准函数集,以及其他常用函数,例如求逆和行列式求解
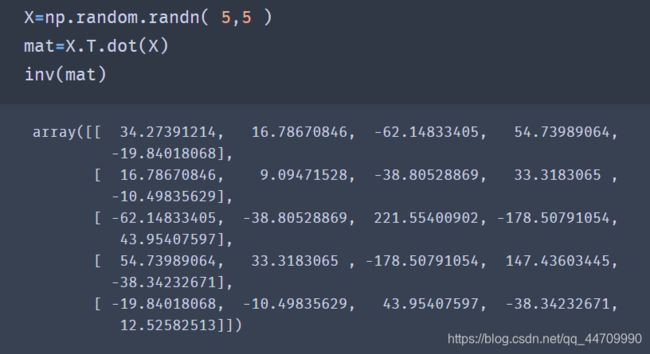
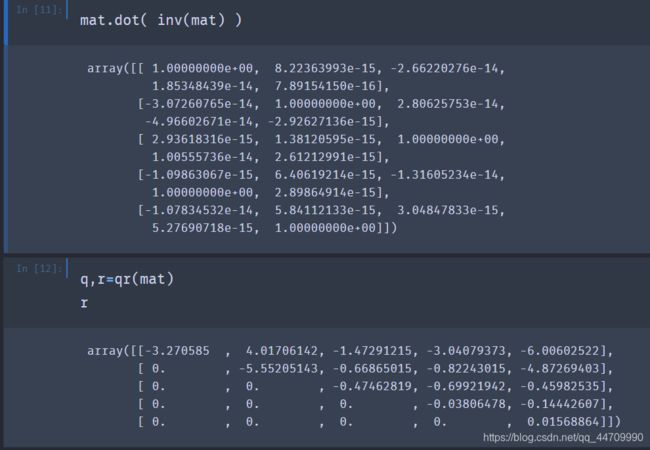
常用的线性代数函数列表:

伪随机数生成
