数据分析(1):jupyter notebook的基本使用,itertools模块的使用
hhh,我的数据分析的书来了,,终于要踏入第二阶段了嘛。。。。
jupyter notebook
交互式的编辑器,用起来很舒服啊,可以下个Anaconda.
ipython是一个python的交互式shell,比默认的python shell好用得多,支持变量自动补全,自动缩进,支持bash shell命令,内置了许多很有用的功能和函数。学习ipython将会让我们以一种更高的效率来使用python。同时它也是利用Python进行科学计算和交互可视化的一个最佳的平台。
-
! shell 命令
-
Tab补全:没有pycham好,,,可以补全变量,模块还可以补全计算机文件路径。在函数关键字参数(包含=)中节约时间。
-
内省:在一个变量名的前后使用问好(?)可以显示一些关于该对象的概要信息。这就是对象内省。对于函数对象,使用?来显示文档字符串,使用??来显示源代码。还可以搜索命名空间。结合一些字符和通配符(星号*)会显示所有匹配通配符表达式的命名。例如我们可以得到numpy 顶层函数中包含 load的函数名列表
np.*load*?
np.__loader__
np.load
np.loads
np.loadtxt
- .%run 命令。来运行python程序文件。
%run python.py脚本是在空白命名空间(没有导入模块或其他定义变量)中运行的,文件定义的所有变量在运行后就可以在命令行中使用了。
如果你想让带运行的脚本使用交互式IPython命名空间中已有的变量,请使用 %run -i替代% run 命令。
如果你想将脚本导入一个代码单元,可以使用%load 魔术函数:
# %load Mytimer.py
import time as t
class Mytimer:
def start(self):
self.begin=t.localtime()
self.prompt = '请先调用stop()停止计时'
print('计时开始')
def stop(self):
if not self.begin:
-----------省略-----------------
-
中断运行中的代码,使用 ctrl+c 引起 KeyboardInterrupt,来停止运行。
-
各种快捷键可以再jupyter notebook 的help里的 keyboard shortcuts 来查看。
-
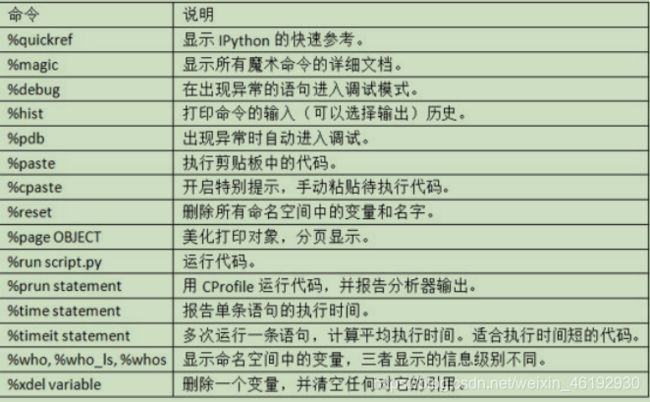
各种魔术命令,,,就是没有内建到python自身的特殊命令。这些命令被设计用来简化常见的任务确保用户更容易的控制Ipython系统的行为。以% 为前缀。例如可以使用 %timeit 来检查一段python语句的执行时间。
魔术函数可以不加% 来使用,只要没有变量被定义为于魔术函数相同的名字即可。特种特性称为自动魔术。。。通过%automagic进行启用或禁止。一些魔术函数可以像python函数一样,其输出可以赋值给一个变量。
可以使用 %quickref或者%magic探索所有的特殊命令。
- matplotlib集成。ipython 能在分析计算领域流行的原因之一就是,他和数据可视化,用户界面库(如matplotlib) 的良好集成。 %matplotlib魔术函数可以设置 matplotlib于ipython命令行或jupyter notebook的集成。这个命令很重要,否则你创建的图可能不会出现(notebook)或者直到结束也无法控制会话(命令行)
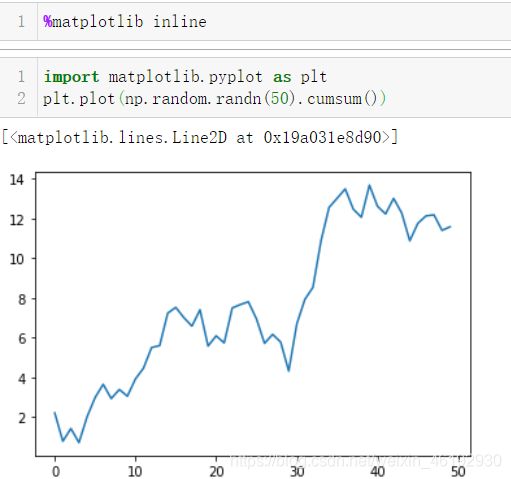 e…这是啥。。。。
e…这是啥。。。。
python语言基础
当复习了,,,
- sort 有一些选项偶尔会排上用场,就像传递一个二级排序key,一个用于生成排序值的函数。
b=['a'.'aa'.'aaa']
b.sort(key=len) # 根据长度排序
- 二分搜索和已排列列表的维护,内置的bisect 模块实现了二分搜索和已排序列表的插值。bisect.bisect会找到元素应该插入的位置,并保持序列排序。而bisect.insort 将元素插入到响应位置:
import bisect
c=[1,2,3,4,5,6]
bisect.bisect(c,2) >>>2
- zip,将列表,元组,其他序列的元素配对,新建一个元组构成的列表。
- 字典的 setdefault 方法,
dict.setdefault(key, default=None) - 集合的操作
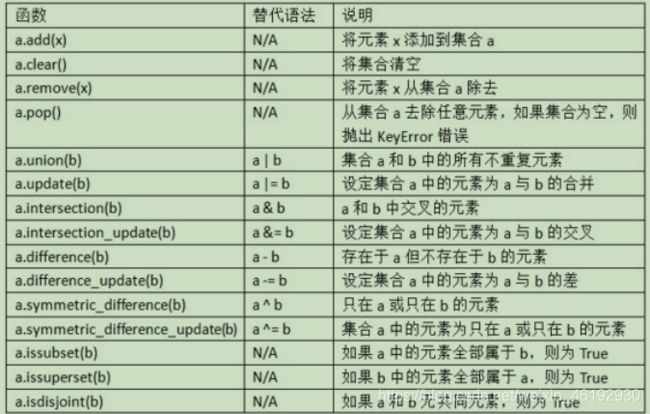
- 列表,集合和字典的推导式
[x.upper() for x in sthrngs if len(x)>2]
{val:index for index,val in enumerate(strings)}
set(map(len,strings))
[name for names in all_data for name in names if name.count('e') >=2] # 嵌套列表推导式
some_tuples=[(1,2,3),(4,5,6),(7,8,9)]
[x for tup in some_tuples for x in top] # for表达式的顺序应该和你写的嵌套for的顺序一直
[[x for x in tup] for tup in some_tuples] # 列表推导式中的列表推导式。
- 函数是对象
import re # 来对一些数据进行清洗
def clean_strings(strings):
result = []
for value in strings:
value = value.strip()
value = re.sub('[!#?]', '', value)
value = value.title()
result.append(value)
return result
# 这种各位函数化的模式可以是你在更高层次上方便修改字符串变换的方法。clean_strings就有了更强的复用性和通用性。
def remove_punctuation(value):
return re.sub('[!#?]', '', value)
clean_ops = [str.strip, remove_punctuation, str.title]
def clean_strings(strings, clean_ops):
result = []
for value in strings:
for function in clean_ops:
value = function(value)
result.append(value)
return result
-
匿名函数,这个再数据分析中非常方便,匿名函数代码量小(也更加清晰),将它作为差数进行传值,比写一个完整的函数或者将匿名函数赋值给局部变量更加有效。
strings.sort(key=lambda x :len(set(list(x))))根据字符串中不同字母的数量对一个字符串集合进行排序 -
柯里化:部分参数应用。表示通过部分参数应用的方式从已有的函数中衍生出新的函数。就是定义了一个新的函数然后调用已有的函数罢了。。。。
-
生成器表达式,多数情况下生成器表达式可以作为函数参数用于替换列表推导式
dic((i,i**2) for i in range(5))
- itertools 模块是适用于大多书数据算法的生成器集合。例如groupby可以根据任意的序列和函数,通过函数的返回值对序列中连续的元素进行分组,

- 字节于Unicode文件。进行解码时,只有每个已编码的Unicode字符时完整的情况下才能进行解码。否则就是报错
UnicodeDecodeError: 'utf-8' codec can't decode byte 0。。。。。,,额,,爬虫的时候经常碰到啊。。。总算直到原因了,还有就是打开文件使用seek时,如果文件的句柄位置恰好再一个Unicode符号的字节中间时,后续的读取也会产生错误,如果你经常要再非ASC II文本数据上进行数据分析,精通Unicode就很有必要。。。。
itertools
Python的内建模块itertools提供了非常有用的用于操作迭代对象的函数。
无限迭代器:
>>> import itertools
>>> cs = itertools.count(2)
>>> for n in cs:
print(n) # 停不下来,,
>>> import itertools
>>> cs = itertools.cycle('ABC') # 注意字符串也是序列的一种
>>> for c in cs: # 这个会无限重复这个序列
... print(c)
>>> ns = itertools.repeat('A', 3) # A 重复三次
>>> for n in ns:
... print(n)
无限序列虽然可以无限迭代下去,但是通常我们会通过takewhile()等函数根据条件判断来截取出一个有限的序列:
>>> natuals = itertools.count(1)
>>> ns = itertools.takewhile(lambda x: x <= 10, natuals)
>>> list(ns)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
chain() 可以把一组迭代对象串联起来,形成一个更大的迭代器:for c in itertools.chain('ABC',;'xyz')
groupby() 把迭代器中相邻的重复元素挑出来放在一起:
>>> for key, group in itertools.groupby('AAABBBCCAAA'):
... print(key, list(group))
...
A ['A', 'A', 'A']
B ['B', 'B', 'B']
C ['C', 'C']
A ['A', 'A', 'A']
实际上挑选规则是通过函数完成的,只要作用于函数的两个元素返回的值相等,这两个元素就被认为是在一组的,而函数返回值作为组的key。
import itertools
first_letter = lambda x:x[0]
names = ['Alan','Adam','Web','Will','Steven']
for key,names in itertools.groupby(names,first_letter):
print(letter,list(name))
A ['Alan','Adam']
....................
-
itertools.accumulate(iterable,func)
accumulate([1,2,3,4,5]) --> 1 3 6 10 15 -
itertools.combinations 求列表或生成器中指定数目的元素不重复的所有组合
combinations('ABCD', 2) --> AB AC AD BC BD CD
>>> x = itertools.combinations(range(4), 3)
>>> print(list(x))
[(0, 1, 2), (0, 1, 3), (0, 2, 3), (1, 2, 3)]
- itertools.combinations_with_replacement(iterable, r) 允许重复元素的组合
>>> x = itertools.combinations_with_replacement('ABC', 2)
>>> print(list(x))
[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'B'), ('B', 'C'), ('C', 'C')]
- itertools.dropwhile(predicate, iterable) 根据真值表舍弃第一个不满足条件前面的值
>>> x = itertools.dropwhile(lambda e: e < 5, range(10))
>>> print(list(x))
[5, 6, 7, 8, 9]
- itertools.filterfalse 保留对应真值为False的元素
>>> x = itertools.filterfalse(lambda e: e < 5, (1, 5, 3, 6, 9, 4))
>>> print(list(x))
[5, 6, 9]
- itertools.permutations(iterable, r=None),输出输入序列的全排列,根据序列位置进行全排列,而不是值,所以如果输入序列有重复值,输出亦会有
>>> x = iters.permutations([0,1,1], 3)
>>> list(x)
[(0, 1, 1), (0, 1, 1), (1, 0, 1), (1, 1, 0), (1, 0, 1), (1, 1, 0)]
- tertools.product(*iterables, repeat=1),product(A, B) returns the same as ((x,y) for x in A for y in B)
>>> list(iters.product('ABC',repeat =1))
[('A',), ('B',), ('C',)]
>>> list(iters.product('ABC',repeat =2))
[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'B'), ('B', 'C'), ('C', 'A'), ('C', 'B'), ('C', 'C')]
- itertools.takewhile(predicate, iterable) 保留序列元素直到条件不满足
takewhile(lambda x: x<5, [1,4,6,4,1]) --> 1 4 - itertools.zip_longest(*iterables, fillvalue=None)
>>> x = itertools.zip_longest(range(3), range(5))
>>> y = zip(range(3), range(5))
>>> print(list(x))
[(0, 0), (1, 1), (2, 2), (None, 3), (None, 4)]
>>> print(list(y))
[(0, 0), (1, 1), (2, 2)]
这篇文章是个好东西啊 脑补连接