C++STL的list模拟实现
文章目录
-
- 前言
- list实现
-
- push_back
- 迭代器(重点)
-
- 普通迭代器
- const迭代器
- insert
- erase
- 析构函数
- 构造函数
- 拷贝构造
- 赋值
- vector和list的区别
前言
要实现STL的list, 首先我们还得看一下list的源码。

我们看到这么一个东西,我们知道C++兼容C,可以用struct来创建一个类。但是我们习惯用class。
那什么时候会用struct呢?
这个类所有成员都想开放出去,比如结点的指针,它一般开放出来。所以我们用struct.。
继续看源码比较重要的东西,成员变量的结构。
![]()
这个东西是啥?
![]()
![]()
这样就很清晰了。
知道它是一个结点的指针,下一步 应该看什么?
成员看了,就看接口。
看接口第一步,看构造函数,看构造函数就知道它怎样初始化,就知道它的初始结构是怎样的。
初始结构摸清楚了,就对它的大概形态摸清楚了。
接着看它的核心方法,当然我们本身对list有一定的了解。
头插头删,尾插尾删就是核心方法。
看它的构造函数
![]()

![]()
后面就先不接着往下看了。
list实现
先把最基本的东西写出来。
namespace but
{
template<class T>
struct list_node
{
list_node<T>* _next;
list_node<T>* _prev;
T _data;
};
template<class T>
class list
{
list()
{
_head = new list_node;
_head->_next = _head;
_head->_prev = _head;
}
private:
list_node* _head;
};
}
push_back


为什么报错?
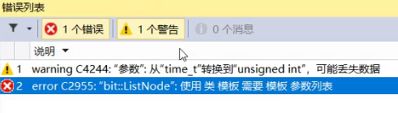
前面我们说过像构造函数,参数可以不加模板参数,但是声明类型还是得加上。
list_node是类名,list_node才是类型。
更新一下前面的代码。
namespace but
{
template<class T>
struct list_node
{
list_node<T>* _next;
list_node<T>* _prev;
T _data;
};
template<class T>
class list
{
typedef list_node<T> node;
list()
{
_head = newnode;
_head->_next = _head;
_head->_prev = _head;
}
private:
node _head;
};
}
push_back怎么搞?
找到尾,然后new 一个新节点,最后链接。
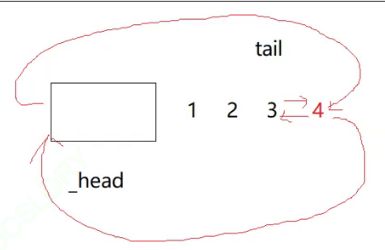
void push_back(const T& x)
{
node* tail = _head->_prev;
node* new_node = new node(x);
tail->_next = new_node;
new_node->_prev = tail;
new_node->_next = _head;
_head->_prev = new_node;
}
写个list_node的构造函数。
list_node(const T& x )
:_next(nullptr)
, _prev(nullptr)
, _data(x)
{}
紧接着报错。
![]()
没有默认构造怎么办?
最好还是提供一个全缺省的构造函数。
//list_node(const T& x =0)不能给0
list_node(const T& x =T())
:_next(nullptr)
, _prev(nullptr)
, _data(x)
迭代器(重点)
普通迭代器
首先我们肯定会遇到一个问题,之前的vector的数据是连续存放的,而链表每个结点是不连续的。
++不能指向下一个结点。
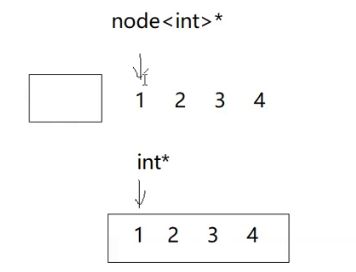
怎么解决这个问题?
能不能给node提供一个重载,不行,因为是node*而不是node;
我们可以看一下STL的源码。
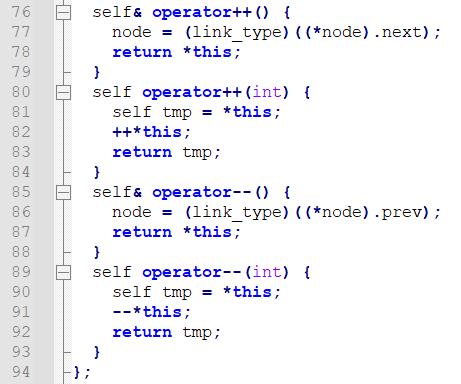
++还可以解引用
![]()
现在我们根据自己的理解,写一个简单的迭代器,让它运行起来。

接着我们再在list这个对象里写上begin()和end()就可以正常访问了。
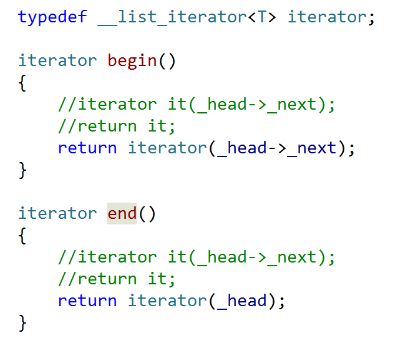
最后测试一下
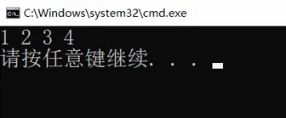
大家仔细看,数组和链表的结构千差万别,但是用起来是如此的相似。
这源自于封装,屏蔽掉了我们看不到的细节。
今天最重要的并不是链表的实现,迭代器的实现才是最最重要的。
总结一下,node*不支持解引用,不支持++,但是我可以用一个自定义类型对你封装,然后去重载运算符,我可以控制我想要的解引用的行为,想要的++的行为,这是自定义类型达到的意义。
![]()
注意看这里有个隐藏的点,发生了拷贝构造,我们自己没有写拷贝构造,编译器自动生成的不会 出问题吗?
程序运行没有报错,什么原因呢?这里没有写析构函数,不需要释放结点。
为什么不需要释放结点?
虽然有结点的指针,但是这结点的指针并不属于迭代器。
结点的指针给迭代器,只是为了遍历链表,++,解引用,修改链表。
释放是链表的事情,链表的析构函数会释放,不需要你释放。
这个结点不是迭代器new出来的,你只有使用权,没有归属权。
template<class T, class Ref, class Ptr>
struct __list_iterator
{
typedef list_node<T> node;
typedef __list_iterator<T, Ref, Ptr> self;
node* _node;
__list_iterator(node* n)
:_node(n)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
self& operator++()
{
_node = _node->_next;
return *this;
}
self operator++(int)
{
self tmp(*this);
_node = _node->_next;
return tmp;
}
self& operator--()
{
_node = _node->_prev;
return *this;
}
self operator--(int)
{
self tmp(*this);
_node = _node->_prev;
return tmp;
}
bool operator!=(const self& s)
{
return _node != s._node;
}
bool operator==(const self& s)
{
return _node == s._node;
}
};
const迭代器
假设我们传了const的链表,编译不通过。
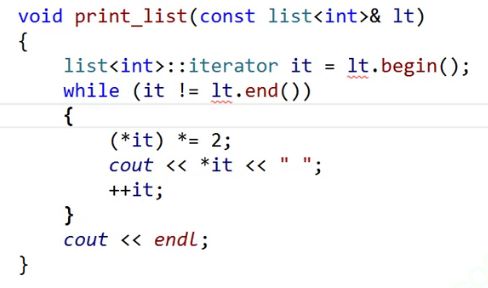
为什么编译不通过?
还是我们之前讲了很多次的权限放大。
我们提供一个支持const对象的迭代器就可以了。
但是看这里,为什么const对象还可以调用构造迭代器?

首先const修饰的*this具体是_head;所以_head不能被改变,而不是_head指向的内容不能被改变。
这个结点指针本身不能改变,但是它可以拷贝给别人。
但是这样写不符合我们的预期,可以修改了。为什么能修改呢?就是因为它构造出了普通迭代器。但是普通迭代器是不可写的。
我们要写一个const迭代器
首先我们先想一下普通迭代器和const迭代器的区别是什么?
先看一个问题,能不能这样定义const迭代器?

绝对不可以。
首先迭代器对标的是指针。

写成上面这样,是保护迭代器本身不能修改,而我们想要的是,迭代器指向的内容不能修改,也就是 const T*;
那怎么实现呢,我们要实现的内容不能修改。
我们可以像之前实现普通迭代器一样,再写一个const迭代器对象,只是名字改一下,然后解引用的时候不能修改。

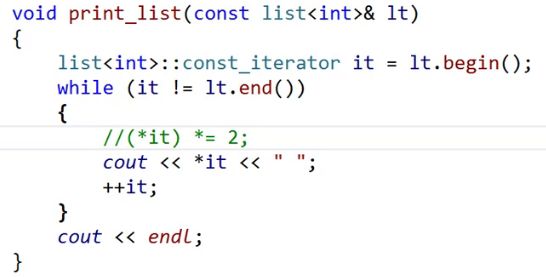
两个对象除了那个返回值不一样,其他都一样怎么简化一下呢?
控制返回值不一样就可以了。增加一个模板参数。
还能这么玩。


// 1、迭代器要么就是原生指针
// 2、迭代器要么就是自定义类型对原生指针的封装,模拟指针的行为
template<class T, class Ref, class Ptr>
struct __list_iterator
{
typedef list_node<T> node;
typedef __list_iterator<T, Ref, Ptr> self;
node* _node;
__list_iterator(node* n)
:_node(n)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
self& operator++()
{
_node = _node->_next;
return *this;
}
self operator++(int)
{
self tmp(*this);
_node = _node->_next;
return tmp;
}
self& operator--()
{
_node = _node->_prev;
return *this;
}
self operator--(int)
{
self tmp(*this);
_node = _node->_prev;
return tmp;
}
bool operator!=(const self& s)
{
return _node != s._node;
}
bool operator==(const self& s)
{
return _node == s._node;
}
};
我们看一下库里面的模板参数
![]()
为什么还有一个Ptr呢?
它还提供了一个重载operator->;
![]()
什么时候会用->?
大家注意,上面的迭代器模拟的是int*;
自定义的类型是不是得用->

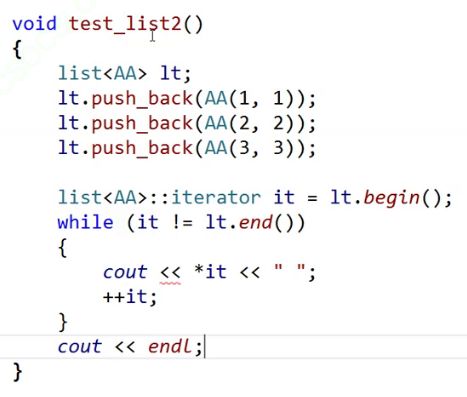
大家看报错了。报的啥错。
it返回的是AA,AA没有返回流插入。
第一种方式可以使用重载一个流插入,这里因为AA里面的成员都不是私有,所以我们可以这样。

这样写很别扭我们可以这样。

我们可以在迭代器里面重载一个->
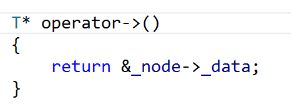
总感觉有点怪怪,其实是这样的。

![]()
好,接下来const的迭代器的->重载需要返回const T*,所以这里再增加一个模板参数。
insert
链表其实已经实现的差不多了,我们现在自己再把功能完善一下。其实我们没必要实现头插头删尾插尾删,我们只需要实现insert.和 erase, insert和erase实现了,其他都可以实现。
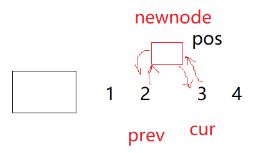
void insert(iterator pos, const T& x)
{
node* cur = pos._node;
node* prev = cur->_prev;
node* new_node = new node(x);
prev->_next = new_node;
new_node->_prev = prev;
new_node->_next = cur;
cur->_prev = new_node;
}
链表的insert会不会导致迭代器失效?
不会
因为pos始终指向这个结点,并且这个位置关系也不会变。
接着我们其实自己不用写push_back和push_front了
void push_back(const T& x)
{
insert(end(), x);
}
void push_front(const T& x)
{
insert(begin(), x);
}
erase
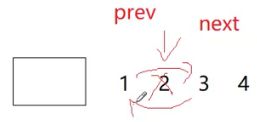
void erase(iterator pos)
{
//哨兵卫头节点不能删除
assert(pos != end());
node* prev = pos._node->_prev;
node* next = pos._node->_next;
prev->_next = next;
next->_prev = prev;
delete pos._node;
}
链表的erase会不会导致迭代器失效?
铁铁的失效,迭代器指向的结点的指针都被干掉了
void pop_back()
{
erase(--end());
}
void pop_front()
{
erase(begin());
}

大家看下面这两行代码的差异在哪里?
本质上没有差异。它们的差异点在于pnode是一个内置类型,it是一个自定义类型。
从物理空间上看,它们的代码是一摸一样的,都是4个字节,并且都是同一个地址。
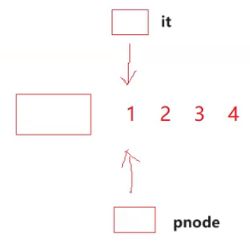
但是这两个的行为天差地别

这就是C语言和C++的差异。
析构函数
clear可以帮我们把数据清掉,但是它不清头结点。
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it);//防止迭代器失效
erase(it++);
}
}

这样写行不行?
可以。it不是失效了吗?为什么还可以it++; 我们之前说过it失效有个现象就是野指针,那这里怎么没事呢?
这就是后置++的价值,它会返回++之前的值。

也就是说erase的并不是it,而是返回的迭代器。
析构和clear的区别就是头节点要不要清楚掉,析构是彻底不用了。
~list()
{
clear();
delete _head;
_head = nullptr;
}
void clear()
{
iterator it = begin();
while (it != end())
{
//it = erase(it);
erase(it++);
}
}
构造函数
我们再提供一下迭代器区间的构造。
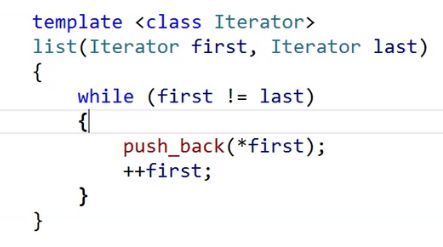
这样写可不可以,不可以,你要push_back,你得有一个哨兵卫的头节点。
void empty_init()
{
_head = new node;
_head->_next = _head;
_head->_prev = _head;
}
template <class Iterator>
list(Iterator first, Iterator last)
{
empty_init();
while (first != last)
{
push_back(*first);
++first;
}
}
const对象可不可以调用构造函数。可以。

拷贝构造
传统写法

现代写法
void swap(list<T>& tmp)
{
std::swap(_head, tmp._head);
}
list(const list<T>& lt)
{
empty_init();
list<T> tmp(lt.begin(), lt.end());
swap(tmp);
}

this跟tmp交换,但是this是随机值,会报错,所以要初始化。
赋值

为什么不用引用传参?
用引用会导致一个非常恶劣的后果。
大家看,传引用的话,lt就是lt3,交换就变成lt1和lt3的交换了。
// lt1 = lt3
list<T>& operator=(list<T> lt)
{
swap(lt);
return *this;
}
vector和list的区别
其实就是顺序表和链表的区别。