RoaringBitMap在ClickHouse和Spark之间的实践-解决数据仓库预计算多维分析问题
前面在Spark多维分析去重计数场景优化案例中说了一下Spark计算在多维分析场景中的弊端,多维度分析会导致数据量指数级膨胀,搭配上去重计算字段越多,膨胀倍数也是线性增长,通过BitMap这个案例也更加让我们明白了,什么是数据倾斜,从根本来讲,并不仅仅是数据量的问题,而是倾斜Task在进行数据IO和数据计算的时候耗费过长时间,我理解为下面三种情况。
- 数据量过大 很常见
- 单条数据存储过大 很少有单个字段单条数据超过几百兆或者几个G的
- 单个Task计算逻辑非常复杂
上面三种情况任意一个情况较差,那么都有可能造成Task长尾。那在之前的案例中也见到了,我使用了RoaringBitMap导致最终的数据计算长尾,单个跑出来的数据可达几个G。
RoaringBitMap
原理分析
借用一张图片看看它比较直观的存储方式。以下都以32位存储为例。64位可以自己去找资料看看。
简单来说,每次往里面加入一个数据,就会将32位数据分为高16位和低16位,高16位是大桶,低16位是小桶,那一个小桶最多可以存储2^16=65536条数据。
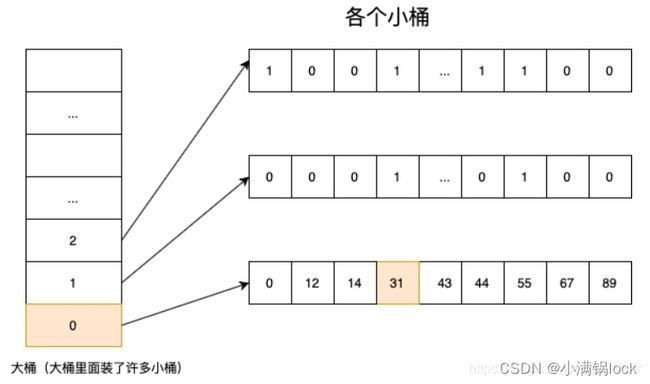

其中RoaringBitMap有一个比较聪明的点,就是一个小桶数据小于4096条时,是采用SmallSet的方式存储,理解为一个排序数组就行,超过这个阈值就采用位图。具体参考这篇文章解释
这个图片也能让你明白大于4096后,位图内存利用率更好,另外就是我们一旦使用了位图,就是2^16位=8kb,所以对于小数据量,没必要一上来就分配这么多存储空间,一条数据低16位,就是2个字节,4096条刚好到8kb,后面如果继续使用数组,就会超过8kb,还不如直接使用位图来存储了,只需要8kb。

存储分析
上面说了RoaringBitMap分为高位存储和低位存储,高位桶对应65536个低位桶,每个低位桶最多8kb,这样一个RoaringBitMap最多有655368kb=512M。经过上面原理的分析,RoaringBitMap很容易理解为一个位图的压缩算法,想象一下,假如直接用Bitmap存储最大值和最小值,相当于需要2^32位,只有最高位和最低位为1,中间就全空了,而且还要分配512M存储,如果采用RoaringBitmap,就只有最高低位桶和最低低位桶,且都采用排序数组存储,也就2byte+2byte=4byte,算上高位也就几个字节。明显压缩了很多存储。
但是,像这种压缩算法,永远也避免不了它的局限性,这个RoaringBitMap存储大小主要受两个东西影响
* 统计基数的量
* 当前数据的散列程度
第一点毋庸置疑,基数越大浪费存储空间越多,但不是绝对,宏观上是这样的,只有当一个桶大于4096之后,那么往里面加元素,空间都不会浪费。
第二点,还是这个图片,可以假设有2000w的基数,那么假设是顺序的,那么2000w/65536桶8kb=306桶8kb=2.448M。但是如果每个桶恰好只存4096条数据,那么就是2000w/4096桶8kb=38M,所以数据越离散,对压缩算法的影响越大,压缩效果也就没那么好。
而第二点也就非常贴合我们实际应用场景,比如上一次场景的多维分析uv去重,userid本身是一个不固定,加上维度分析,userid更是自由组合,所以生成的二进制对象非常大,即便userid比较少。
上面讨论了那么多RoaringBitMap存储空间问题,在实际场景中,userid分布是很不均匀的,很随机,那么在实际中每个维度场景下生成的RoaringBitMap对象非常大,尤其是最粗粒度,聚集了最多散列用户,细粒度只聚集了少部分,开销很小。
Spark和Hive计算时,多维度组合必定有一个读取数据量会倾斜,因为他要聚合所有维度组合情况,实际And和or操作非常快,主要时间花在了IO上。
RoringBitMap在ClickHouse和Spark之间作用
上面从RoringBitMap原理和存储方面分析了我们之前案例中数据倾斜的问题,但是有一个待讨论的点,就是我们分析了11个维度组合,经过验证可能有几百万的维度组合情况,而其中某些维度组合是不是我们真正分析需要的。比如是否要看某个用户等级,os的情况,很少有人这么分析,相当于我们的多维分析,是预计算好所有可能组成的情况,沉淀到数仓的ADS层。然后提供接口查询,对数仓来说,只要按时产出就行,而实际数据需求方只是挑选其中某些情况进行分析,不可能枚举这么多种。
针对这种数据仓库预计算多维分析场景,我们花费了几个小时跑出来预计算的结果,只有少部分数据是有价值的,很显然要解决这种问题,要从两个方面入手
- 只求数据业务方需要的数据,很难预判业务方的需求,毕竟阴晴不定。
- 一是最大限度缩小无关联维度的组合 还没想到解决办法,记个代办
- 按需自助取数
这里我们针对第三点,前面已经把数据聚合到了DWS,也就是最细粒度的维度+RoaringBitMap< userid >,那我们不提供ADS,业务方需要的话,自己根据DWS查就行。
| 维度 | RBM |
|---|---|
| 维度2 | RBM< user > |
| 维度3 | RBM< user > |
| … | … |
由于Hive表不能直接存储对象,只能存储二进制,那业务方查询遇到了一个问题,就是必须使用我们的反序列化UDF,先将表数据转成RBM对象,然后在聚合维度做OR操作,也就是userid去重,这个耗时就会更长。
于是我们想到了ClickHouse的groupBitMapOR,底层也是采用RoaringBitMap,但是是用Croaring实现的,那可以将hive的RBM对象序列化成ClickHouse的RoaringBitMap数据存储方式。
下面案例以64位实现方式为准,32位可自己扒代码。
Spark RoaringBitMapUDAF聚合函数实现
/**
* @description roaring64NavigableMap 采用红黑树的RBM实现方法
*/
public class RoaringBitMapNavigableUDAF extends AbstractGenericUDAFResolver implements Serializable {
/**
* @return 返回去重Buffer
* @description UDAF初始化 仅仅支持一个参数 传进来的为TextWritable 读取Object可以强制转为Text
* */
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters) throws SemanticException {
// TODO Auto-generated method stub
if (parameters == null || parameters.length != 1) {
throw new UDFArgumentTypeException(0, "仅支持一个参数!");
}
return new RoaringBitMapNavigableUDAF.BitmapDistinctUDAFBuffer();
}
/**
* BitMap去重 静态内部类
* 作为 COMPLETE(PARTIAL1) -> PARTIAL2 -> FINAL 几个过程的处理
* */
public static class BitmapDistinctUDAFBuffer extends GenericUDAFEvaluator {
// 输入类型
PrimitiveObjectInspector inputType;
/**
* @return 约定每个过程的输出类型。即告诉下个过程我将传入Byte[]数组过来
* @description 初始化函数 如果为COMPLETE(PARTIAL1)过程 约定原始输入类型类PrimitiveObjectInspector(Text),用户传入字符串即可 其余模式下为Byte[]
* */
@Override
public ObjectInspector init(GenericUDAFEvaluator.Mode m, ObjectInspector[] parameters)
throws HiveException {
super.init(m, parameters);
if(Mode.PARTIAL1.equals(m) || Mode.COMPLETE.equals(m)){
inputType = (PrimitiveObjectInspector) parameters[0];
}
return PrimitiveObjectInspectorFactory.javaByteArrayObjectInspector;
}
/**
* @description 聚合的Buffer类
* */
@Override
public GenericUDAFEvaluator.AggregationBuffer getNewAggregationBuffer() throws HiveException {
return new RoaringBitMapNavigableUDAF.BitmapAggrBuffer();
}
/**
* @description 重置清空buffer
* */
@Override
public void reset(GenericUDAFEvaluator.AggregationBuffer aggregationBuffer) throws HiveException {
((RoaringBitMapNavigableUDAF.BitmapAggrBuffer) aggregationBuffer).reset();
}
/**
* @param aggregationBuffer 聚合去重Buffer处理器
* @param objects 对象列表
* @description 由聚合Buffer处理器处理每一个object
* */
@Override
public void iterate(GenericUDAFEvaluator.AggregationBuffer aggregationBuffer, Object[] objects) throws HiveException {
if(objects == null) {
return;
}
for(Object object: objects){
if(object != null) {
Object input = inputType.getPrimitiveWritableObject(object);
RoaringBitMapNavigableUDAF.BitmapAggrBuffer bitmapAggrBufferr = (RoaringBitMapNavigableUDAF.BitmapAggrBuffer) aggregationBuffer;
bitmapAggrBufferr.calcResult((Text) input); // 这里强制转为了Text。注意BitMap只能处理数字,所以传进来的必须是数字 字符串 否则会报错
}
}
}
/**
* @param aggregationBuffer 聚合去重Buffer处理器
* @description 将Buffer中的RoaringBitmap序列化成字节数组,输出给下游shuffle。
* */
@Override
public Object terminatePartial(GenericUDAFEvaluator.AggregationBuffer aggregationBuffer) throws HiveException {
RoaringBitMapNavigableUDAF.BitmapAggrBuffer bitmapAggrBuffer = (RoaringBitMapNavigableUDAF.BitmapAggrBuffer) aggregationBuffer;
// 约定字节输出流
ByteArrayOutputStream out = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = null;
try {
objectOutputStream = new ObjectOutputStream(out);
bitmapAggrBuffer.writeBytes(objectOutputStream);
objectOutputStream.flush(); // 记得要flush一下
return out.toByteArray();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭流
try {
out.close();
if (objectOutputStream != null) {
objectOutputStream.close(); // 关闭外部流即可 内部流会自己关闭
}
} catch (IOException e) {
e.printStackTrace();
}
}
return new byte[0];
}
/**
* @param aggregationBuffer 聚合去重Buffer处理器
* @param o 另一个需要待合并的 聚合去重Buffer处理器
* @description 这里在下游聚合的时候,不同上游传了同一个Group key但是不同value,
* 此时value已经是序列化之后的RoaringBitMap对象object,需要将每一个object反序列化成RoaringBitMap
* 然后利用aggregationBuffer 将每个RoaringBitMap合并起来
* 这里的合并采用OR操作,因为涉及到同一个key的value去重,只需要任何一个value的某个bit有值,那么就说明这个bit代表的值是有的,即把bit当做标记而已。
* */
@Override
public void merge(GenericUDAFEvaluator.AggregationBuffer aggregationBuffer, Object o) throws HiveException {
RoaringBitMapNavigableUDAF.BitmapAggrBuffer bitmapAggrBuffer = (RoaringBitMapNavigableUDAF.BitmapAggrBuffer) aggregationBuffer;
if (o != null) {
byte[] bytes = (byte[]) o; // 将object转为byte[] 可能有坑
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
ObjectInputStream inputStream = null;
try {
Roaring64NavigableMap mergeInputStreamBitMap = new Roaring64NavigableMap();
inputStream = new ObjectInputStream(in);
mergeInputStreamBitMap.readExternal(inputStream);
bitmapAggrBuffer.or(mergeInputStreamBitMap);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
} finally {
try {
if(inputStream != null) {
inputStream.close();
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
/**
* @description 最终的结果输出 将aggregationBuffer里面的Roaring中的BitMap反序列化成Byte[]输出
*
* */
@Override
public Object terminate(GenericUDAFEvaluator.AggregationBuffer aggregationBuffer) throws HiveException {
RoaringBitMapNavigableUDAF.BitmapAggrBuffer bitmapAggrBuffer = (RoaringBitMapNavigableUDAF.BitmapAggrBuffer) aggregationBuffer;
ByteArrayOutputStream out = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = null;
try {
objectOutputStream = new ObjectOutputStream(out);
bitmapAggrBuffer.writeBytes(objectOutputStream);
objectOutputStream.flush();
return out.toByteArray();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 清理流的状态
try {
out.close();
if (objectOutputStream != null) {
objectOutputStream.close(); // 关闭外部流即可 内部流会自己关闭
}
} catch (IOException e) {
e.printStackTrace();
}
}
return new byte[0];
}
}
/**
* @description 聚合去重BitMap去重buffer处理器
* */
static class BitmapAggrBuffer extends GenericUDAFEvaluator.AbstractAggregationBuffer implements Serializable {
// Bitmap 64位实例化对象
Roaring64NavigableMap roaring64NavigableMap = new Roaring64NavigableMap();
// 重置
public void reset() {
roaring64NavigableMap.clear();
}
/**
* @param value 传入的为Text类型,如果不能转成数字 说明会出错
* @description 计算结果
* */
public void calcResult(Text value) {
String s = value.toString();
if(s != null && !"".equals(s)) {
try{
roaring64NavigableMap.add(Long.parseLong(s));
} catch (Exception e){
e.printStackTrace();
}
}
}
/**
* @param o 传入的另一RoaringBitmap对象
* @description 这里去重使用位图的OR操作,只要任何一个bitmap对象的某一个bit有值,说明这个bit代表的内容是有值的,也就是说合并之后的RoaringBitmap在这一位应该置为1
* */
public void merge(Object o){
roaring64NavigableMap.or((Roaring64NavigableMap) o);
}
public Long getResult() {
if (roaring64NavigableMap.isEmpty()) {
return null;
}
return roaring64NavigableMap.getLongCardinality();
}
/**
* @description 将结果输出到output流里面
* */
public void writeBytes(ObjectOutputStream objectOutputStream){
try {
this.roaring64NavigableMap.writeExternal(objectOutputStream);
objectOutputStream.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
public void or(Roaring64NavigableMap roaring64NavigableMap){
this.roaring64NavigableMap.or(roaring64NavigableMap);
}
}
}
将RBM二进制数据序列化成ClickHouse的存储方式
这里注意,我测试的是ClickHouse 21.1版本以上,20及之前版本序列化格式会有所区别,这三个是ClickHouse RBM实现相关代码,根据这些代码,我弄了一个java二进制序列化ClickHouse存储方式的版本。
Croing实现
ClickHouseRBM实现
ClickHouse VarInt实现
/**
* 将二进制的Roaring64NavigableMap对象先反序列化成对象
* 这里对应的是ClickHouse21.1版本以上 将其定制序列化为ClickHouse的CRoaring
* 序列化主要分为四部分
* * 第一部分:一个byte 如果基数小于32用smallSet,用0表示。否则用1表示,用RBM
* * 第二部分:实际数据需要的字节大小
* * 第三部分:针对RBM实用的,RBM高位的字节数
* * 第四部分:数据内容
* 最后BASE64编码成字符串,最终写入到ClickHouse
*/
public class BinToRbm64NavigableWithClickHouse extends UDF {
public String evaluate(Object o) {
String encodeResult = "";
byte[] bytes = (byte[]) o;
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
ObjectInputStream objectInputStream = null;
Roaring64NavigableMap roaring64NavigableMap = new Roaring64NavigableMap();
try {
objectInputStream = new ObjectInputStream(in);
roaring64NavigableMap.readExternal(objectInputStream);
// 先获取容量
long longCardinality = roaring64NavigableMap.getLongCardinality();
// 当基数小于32时,采用SmallSet存储
if(longCardinality <= 32){
// 分配缓冲区大小
ByteBuffer initBuffer = ByteBuffer.allocate(2 + 8 * roaring64NavigableMap.getIntCardinality());
ByteBuffer bosBuffer = null;
if(initBuffer.order() == ByteOrder.LITTLE_ENDIAN){
bosBuffer = initBuffer;
} else {
bosBuffer = initBuffer.slice().order(ByteOrder.LITTLE_ENDIAN);
}
bosBuffer.put((new Integer(0)).byteValue());
bosBuffer.put(new Integer((roaring64NavigableMap.getIntCardinality())).byteValue());
long[] roaring64BitMapLong = roaring64NavigableMap.toArray();
for (long l : roaring64BitMapLong) {
bosBuffer.putLong(l);
}
encodeResult = Base64.getEncoder().encodeToString(bosBuffer.array());
}else {
//rb.serializedSizeInBytes() 需要序列化的字节数
int serialByteSize = (int)roaring64NavigableMap.serializedSizeInBytes();
int rbTotalSize = serialByteSize - 5 + 8;
int varLongLen = VarIntParse.varIntSize(rbTotalSize);
ByteBuffer initBuffer = ByteBuffer.allocate(varLongLen + 1 + rbTotalSize);
ByteBuffer bosBuffer;
if(initBuffer.order() == ByteOrder.LITTLE_ENDIAN){
bosBuffer = initBuffer;
} else {
bosBuffer = initBuffer.slice().order(ByteOrder.LITTLE_ENDIAN);
}
bosBuffer.put((new Integer(1)).byteValue());
VarIntParse.putVarInt((int)serialByteSize, bosBuffer);
// getHighToBitmap是Roaring64NavigableMap的私有方法 不能直接调用,利用反射调用即可
Method method = roaring64NavigableMap.getClass().getDeclaredMethod("getHighToBitmap", null);
method.setAccessible(true);
NavigableMap<Integer, BitmapDataProvider> highToBitMap = (NavigableMap<Integer, BitmapDataProvider>) method.invoke(roaring64NavigableMap, null);
bosBuffer.putLong(highToBitMap.size());
ByteArrayOutputStream byteOutputStream = new ByteArrayOutputStream();
roaring64NavigableMap.serialize(new DataOutputStream(byteOutputStream));
byte[] outPutPre = byteOutputStream.toByteArray();
byte[] outPutResult = Arrays.copyOfRange(outPutPre, 5, serialByteSize);
bosBuffer.put(outPutResult);
encodeResult = Base64.getEncoder().encodeToString(bosBuffer.array());
}
} catch (IOException | ClassNotFoundException | NoSuchMethodException | IllegalAccessException | InvocationTargetException e) {
e.printStackTrace();
} finally {
try {
if(objectInputStream != null) {
objectInputStream.close();
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
return encodeResult;
}
}
VarInt是参考Git上人家的实现,忘记地址啦。
/**
* @date 2022/11/09
* @description VarInt解析 主要用来序列化和ClickHouse保持一致 详见https://github.com/bazelbuild/bazel/blob/master/src/main/java/com/google/devtools/build/lib/util/VarInt.java
*/
public class VarIntParse {
/**
* Maximum encoded size of 32-bit positive integers (in bytes)
*/
public static final int MAX_VARINT_SIZE = 5;
/**
* maximum encoded size of 64-bit longs, and negative 32-bit ints (in bytes)
*/
public static final int MAX_VARLONG_SIZE = 10;
private VarIntParse() { }
/** Returns the encoding size in bytes of its input value.
* @param i the integer to be measured
* @return the encoding size in bytes of its input value
*/
public static int varIntSize(int i) {
int result = 0;
do {
result++;
i >>>= 7;
} while (i != 0);
return result;
}
/**
* Reads a varint from src, places its values into the first element of dst and returns the offset
* in to src of the first byte after the varint.
*
* @param src source buffer to retrieve from
* @param offset offset within src
* @param dst the resulting int value
* @return the updated offset after reading the varint
*/
public static int getVarInt(byte[] src, int offset, int[] dst) {
int result = 0;
int shift = 0;
int b;
do {
if (shift >= 32) {
// Out of range
throw new IndexOutOfBoundsException("varint too long");
}
// Get 7 bits from next byte
b = src[offset++];
result |= (b & 0x7F) << shift;
shift += 7;
} while ((b & 0x80) != 0);
dst[0] = result;
return offset;
}
/**
* Reads a varint from the current position of the given ByteBuffer and returns the decoded value
* as 32 bit integer.
*
* The position of the buffer is advanced to the first byte after the decoded varint.
*
* @param src the ByteBuffer to get the var int from
* @return The integer value of the decoded varint
*/
public static int getVarInt(ByteBuffer src) {
int tmp;
if ((tmp = src.get()) >= 0) {
return tmp;
}
int result = tmp & 0x7f;
if ((tmp = src.get()) >= 0) {
result |= tmp << 7;
} else {
result |= (tmp & 0x7f) << 7;
if ((tmp = src.get()) >= 0) {
result |= tmp << 14;
} else {
result |= (tmp & 0x7f) << 14;
if ((tmp = src.get()) >= 0) {
result |= tmp << 21;
} else {
result |= (tmp & 0x7f) << 21;
result |= (tmp = src.get()) << 28;
while (tmp < 0) {
// We get into this loop only in the case of overflow.
// By doing this, we can call getVarInt() instead of
// getVarLong() when we only need an int.
tmp = src.get();
}
}
}
}
return result;
}
/**
* Reads a varint from the given InputStream and returns the decoded value as an int.
*
* @param inputStream the InputStream to read from
*/
public static int getVarInt(InputStream inputStream) throws IOException {
int result = 0;
int shift = 0;
int b;
do {
if (shift >= 32) {
// Out of range
throw new IndexOutOfBoundsException("varint too long");
}
// Get 7 bits from next byte
b = inputStream.read();
result |= (b & 0x7F) << shift;
shift += 7;
} while ((b & 0x80) != 0);
return result;
}
/**
* Encodes an integer in a variable-length encoding, 7 bits per byte, into a destination byte[],
* following the protocol buffer convention.
*
* @param v the int value to write to sink
* @param sink the sink buffer to write to
* @param offset the offset within sink to begin writing
* @return the updated offset after writing the varint
*/
public static int putVarInt(int v, byte[] sink, int offset) {
do {
// Encode next 7 bits + terminator bit
int bits = v & 0x7F;
v >>>= 7;
byte b = (byte) (bits + ((v != 0) ? 0x80 : 0));
sink[offset++] = b;
} while (v != 0);
return offset;
}
/**
* Encodes an integer in a variable-length encoding, 7 bits per byte, to a ByteBuffer sink.
*
* @param v the value to encode
* @param sink the ByteBuffer to add the encoded value
*/
public static void putVarInt(int v, ByteBuffer sink) {
while (true) {
int bits = v & 0x7f;
v >>>= 7;
if (v == 0) {
sink.put((byte) bits);
return;
}
sink.put((byte) (bits | 0x80));
}
}
/**
* Encodes an integer in a variable-length encoding, 7 bits per byte, and writes it to the given
* OutputStream.
*
* @param v the value to encode
* @param outputStream the OutputStream to write to
*/
public static void putVarInt(int v, OutputStream outputStream) throws IOException {
byte[] bytes = new byte[varIntSize(v)];
putVarInt(v, bytes, 0);
outputStream.write(bytes);
}
/**
* Returns the encoding size in bytes of its input value.
*
* @param v the long to be measured
* @return the encoding size in bytes of a given long value.
*/
public static int varLongSize(long v) {
int result = 0;
do {
result++;
v >>>= 7;
} while (v != 0);
return result;
}
/**
* Reads an up to 64 bit long varint from the current position of the
* given ByteBuffer and returns the decoded value as long.
*
* The position of the buffer is advanced to the first byte after the
* decoded varint.
*
* @param src the ByteBuffer to get the var int from
* @return The integer value of the decoded long varint
*/
public static long getVarLong(ByteBuffer src) {
long tmp;
if ((tmp = src.get()) >= 0) {
return tmp;
}
long result = tmp & 0x7f;
if ((tmp = src.get()) >= 0) {
result |= tmp << 7;
} else {
result |= (tmp & 0x7f) << 7;
if ((tmp = src.get()) >= 0) {
result |= tmp << 14;
} else {
result |= (tmp & 0x7f) << 14;
if ((tmp = src.get()) >= 0) {
result |= tmp << 21;
} else {
result |= (tmp & 0x7f) << 21;
if ((tmp = src.get()) >= 0) {
result |= tmp << 28;
} else {
result |= (tmp & 0x7f) << 28;
if ((tmp = src.get()) >= 0) {
result |= tmp << 35;
} else {
result |= (tmp & 0x7f) << 35;
if ((tmp = src.get()) >= 0) {
result |= tmp << 42;
} else {
result |= (tmp & 0x7f) << 42;
if ((tmp = src.get()) >= 0) {
result |= tmp << 49;
} else {
result |= (tmp & 0x7f) << 49;
if ((tmp = src.get()) >= 0) {
result |= tmp << 56;
} else {
result |= (tmp & 0x7f) << 56;
result |= ((long) src.get()) << 63;
}
}
}
}
}
}
}
}
return result;
}
/**
* Encodes a long integer in a variable-length encoding, 7 bits per byte, to a
* ByteBuffer sink.
* @param v the value to encode
* @param sink the ByteBuffer to add the encoded value
*/
public static void putVarLong(long v, ByteBuffer sink) {
while (true) {
int bits = ((int) v) & 0x7f;
v >>>= 7;
if (v == 0) {
sink.put((byte) bits);
return;
}
sink.put((byte) (bits | 0x80));
}
}
public static void putVarLong(long v, OutputStream outputStream) throws IOException {
byte[] bytes = new byte[varLongSize(v)];
ByteBuffer sink = ByteBuffer.wrap(bytes);
putVarLong(v, sink);
outputStream.write(bytes);
}
}
经过RBM二进制对象序列化然后加密后,导入到Clickhouse,
ClickHouse建表
create table ...(
dim1 string,
dim2 string,
encode string, -- 加密二进制RBM
roaring_bitmap AggregateFunction(groupBitmap, UInt32)
MATERIALIZED base64Decode(encode) -- 解密并反序列化成Croaring
)
select
groupBitMapOr(roaring_bitmap)
from table
where dim1 = 'ak' and dim2 = 'ko
...
这样查询基本毫秒级别查询了,而且从数仓底层一直到ClickHouse,可以从几个小时缩短到半个小时以内,聚合层更是从2个小时,缩短到5min。按需查询。
下一步优化和思考
要知道RBM存储空间仍然是非常大的,仍然解决不了问题,甚至DWS层直接聚合到用户粒度的存储,都没得聚合到最细粒度,采用Roaring存储的存储空间大。这样让我觉得,其实也可以导入一个明细表去ClickHouse,然后基于这个明细表再构建一个RoaringBitMap表,这样总存储能省更多,甚至都不用RoaringBitMap表,可以直接在查询时临时buildBitMap,查询可以保证在秒级别,但是对ck的CPU消耗和磁盘IO我没怎么评估过,要是ClickHouse能出一个官方的实践就好了。