JavaEE:多线程(1):线程是啥?怎么创建和操作?
进程的问题
本质上来说,进程可以解决并发编程的问题
但是有些情况下进程表现不尽如人意
1. 如果请求很多,需要频繁的创建和销毁进程的时候,此时使用多进程编程,系统开销就会很大
2. 一个进程刚刚启动的时候,需要把依赖的代码和数据从磁盘加载到内存中
但是从系统分配一个内存不是件容易事情
申请内存的时候需要指定大小,系统内部把各种大小的空闲内存,通过一定的数据结构组织起来
实际申请的时候要去这样的空间中查找,找到大小合适的空间,再进行分配
所以引入一个概念,线程
线程
线程称为轻量级进程,保持进程的独立调度执行,同时省去了分配资源和释放资源带来的额外开销
使用PCB描述一个线程
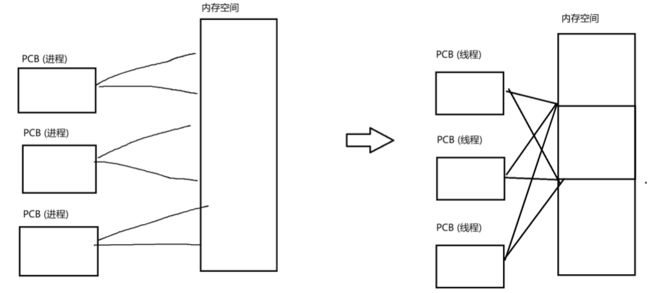
多个线程的PCB的内存指针指向同一个内存空间
这意味着只用创建第一个线程的时候需要从系统分配资源,后续的线程就不必分配,直接共用前面的那份资源就可以了
除了内存之外,文件描述符表(硬盘资源)也是多个线程共用一份的
把能够进行资源共享的线程分成组,称为线程组
一个进程可以有1个PCB,也可以有多个PCB(意味着这个进程包含了一个线程组,也就是包含多个线程)
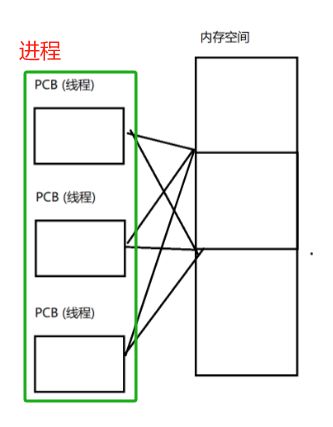 上面图中这多个线程合起来就是一个进程
上面图中这多个线程合起来就是一个进程
进程和线程的关系
有线程之前,进程要扮演两个角色:资源分配的基本单位;调度执行的基本单位
有线程之后,进程专注于资源分配,线程专注于调度执行
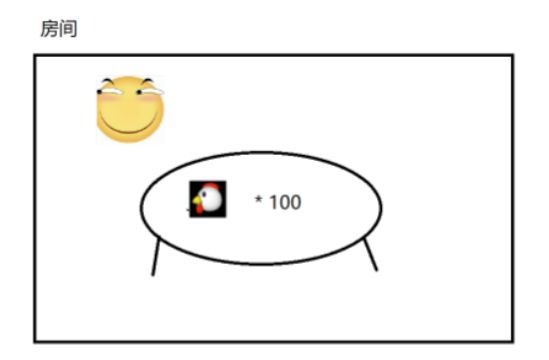
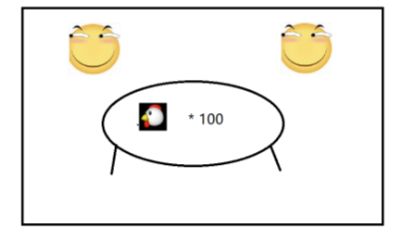
例子:一个滑稽吃100只鸡,消耗的时间比较多
第一个方案:搞两个房间,每个滑稽吃50只,速度大幅度增加
这个相当于多进程,创建新的进程就要申请更多的资源(房间和桌子)
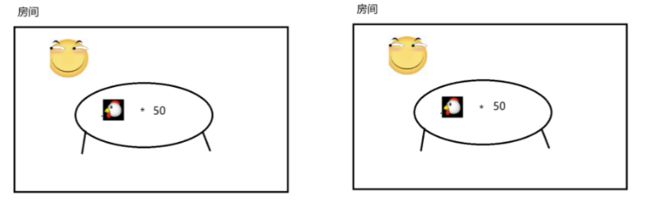
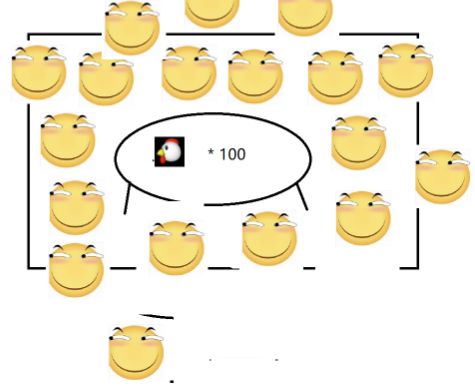
第二个方案,房间和桌子数量不变,但是滑稽数量增加到两个
这种就是多线程,资源开销更小
更多的滑稽,每个滑稽分到的鸡就更少了,但是速度更快了
但是线程分配越多越好吗?
当引入的线程达到一定数量之后,再继续引入线程就没办法提升了,因为线程之间会竞争CPU资源,但是CPU资源是有限的,非但提高不了效率,还会增加调度的开销
而且多个线程之间会打架,可能导致代码中出现逻辑错误
这种就是线程安全问题
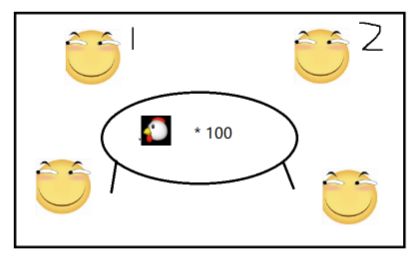
另外,多线程共享资源也有副作用,1号和2号滑稽抢鸡腿,1号抢到了,2号勃然大怒:都别吃了!直接把整个桌子给破坏了
也就是说,一个线程如果抛出异常而且没有处理好的话,可能会导致整个进程被终止
总结一下
1. 进程包含线程
2. 每个线程是一个独立的执行流,可以执行代码并参与CPU调度中(每个线程都有状态,优先级,记账信息和上下文)
3. 每个线程都有自己的资源,进程中的线程共享一份资源
4. 进程和线程之间,不会相互影响。但是如果同一个进程中某个线程抛出异常,可能导致进程中其他线程异常终止
5. 同一个进程中的线程之间会互相干扰,引起线程安全问题
6. 线程太多会导致调度开销过多的问题
多线程编程
Java推荐多线程编程,系统提供了多线程编程的API
Java里一般把跑起来的程序称为进程,没有运行起来的程序(exe),称为可执行文件
一个进程里的第一个线程称为主线程,main方法就是主线程的入口
创建线程
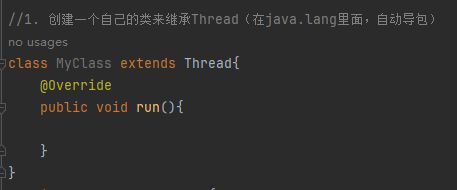
这里的run类似于main方法,是一个Java进程的入口方法;不需要程序员手动调用,会在合适的时机(线程创建好了之后),被JVM自动调用执行
这种风格的函数被称为回调函数
(回调函数是一种特殊的函数,它作为参数传递给另一个函数,并在被调用函数执行完毕后被调用)
为什么要override呢?
重写的本质是扩展现有的类,Thread标准库里面的run是不知道你的需求是什么,必须要手动指定
//1. 创建一个自己的类来继承Thread(在java.lang里面,自动导包)
class MyClass extends Thread{
@Override
public void run(){
System.out.println("hello world");
}
}
public class ThreadDemo1 {
public static void main(String[] args) {
//2. 根据刚才的类创建出实例(线程实例才是真正的线程)
Thread t = new MyClass();
//3.调用Thread的start方法,才会真正调用API,在系统内核中创建出线程
//对于同一个Thread对象来说,start只能调用一次
t.start();
}
}操作系统的内核:操作系统最核心的功能模块,负责管理硬件,给软件提供稳定的运行环境
例子:
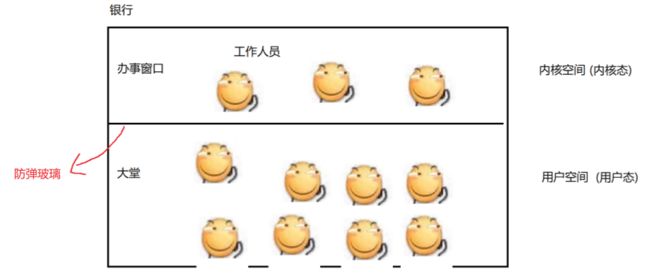
我们平时运行的idea,qq音乐这些应用程序都是运行在用户态了
但是这些程序有时候需要针对一些系统提供的软硬件资源进行操作,这些操作需要调用系统的api,进一步在内核钟完成这样的操作
为什么要划分出用户态和内核态?
为了稳定,防止应用程序把硬件设备或者软件资源给搞坏了
系统封装了一些API,这些API属于合法操作,这些应用程序只能调用这些合法API,就不会被系统/硬件设备造成伤害
操作系统 = 内核+配套的应用程序
观察线程流
例子
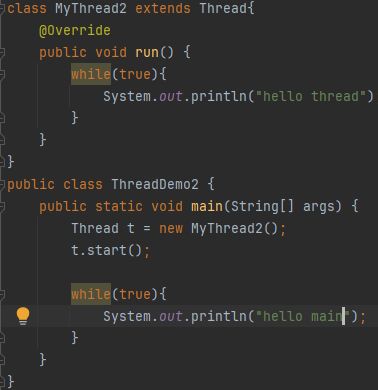
按照之前的理解,如果一个代码中出现两个死循环,最多只能执行一个,另一个循环就进不去了
但真正运行程序可以看到两个循环都在执行
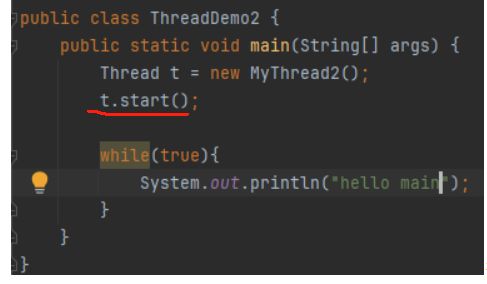
此处调用start创建线程之后,兵分两路;一路沿着main方法继续执行,打印hello main
另一路进入到线程的run方法,打印hello thread
此时两个线程并发执行,但是这些线程执行的先后顺序是不确定的
因为操作系统的内核中有一个调度器模块,这个模块的实现方式是一种类似于随机调度的效果
随即调度?(也是抢占式执行)
1. 一个线程什么时候被调度到CPU上执行,时机是不确定的
2.一个线程什么时候从CPU上下来,给别的线程让位,时机也是不确定的
不只是可以用打印来观察,我们还可以用jdk中的jconsole工具来进一步分析出线程流

点进去,选择本地连接,连接到我们刚刚的程序中(注意刚刚的程序要运行起来才能在这里找到)
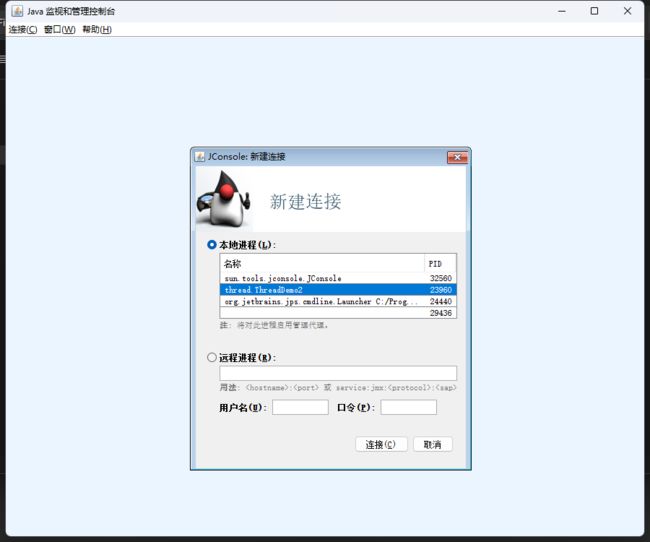
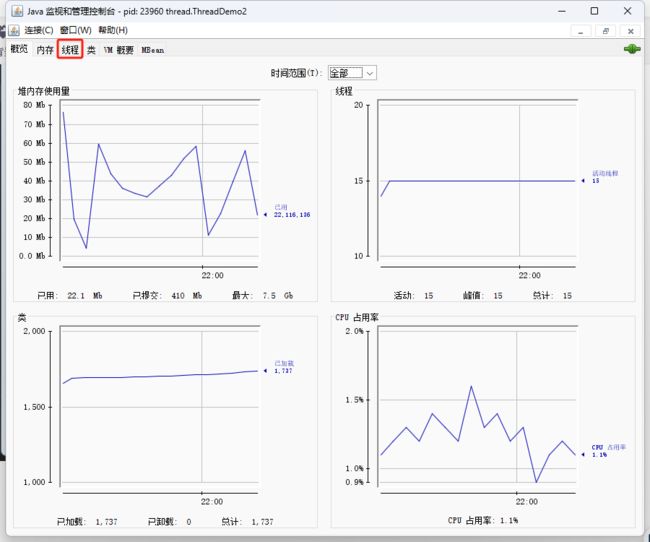
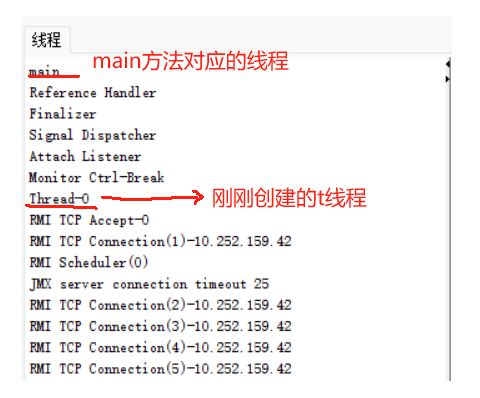
一个Java进程中,包含的线程很多,除了我标出来的两个线程
其余的线程都是JVM自带的线程,进行一些垃圾回收,监控统计各种指标,把统计指标通过网络的方式传输给其他程序

![]()
由于我们的程序中的两个循环都是死循环,循环体就单纯打印,一旦程序运行起来,这俩循环就会转地飞快;也会导致CPU占用率比较高,进一步提高电脑的功耗
我们可以在循环中加入一个Thread提供的静态方法sleep来降低循环速度
class MyThread2 extends Thread{
@Override
public void run() {
while(true){
System.out.println("hello thread");
try {
sleep(1000);//每秒钟打印一次
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class ThreadDemo2 {
public static void main(String[] args) {
Thread t = new MyThread2();
t.start();
while(true){
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}这里为什么不能直接用sleep(1000)呢?
因为sleep这个过程中可能被提前唤醒
为什么第一个sleep只有一个try catch的处理选项而不能throws,而第二个sleep可以throws异常?
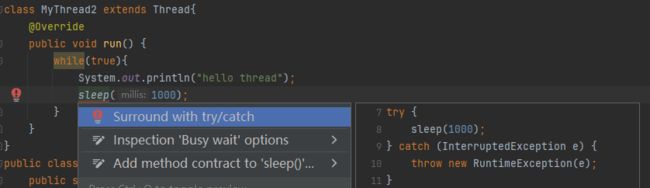
如果这里加上throws,修改方法签名,此时就无法构成重写了,因为父类的run没有throws这个异常,子类重写的时候就不能throws异常
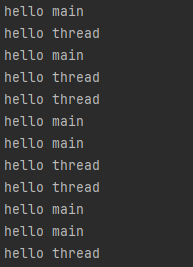
我们可以看见两个线程交替运行,而且先执行main还是thread是不一定的
但是,由于我们主线程main调用start方法之后就立即往下执行打印了,内核就要通过刚才线程的API构建出线程出来,并且执行run
因为线程创建本身就有开销,所以第一轮打印的时候,在创建线程开销本身的影响下,hello thread会比hello main慢一点打印出来
创建线程其他方式
上面是线程创建的第一种方式:继承Thread,重写run
下面介绍第二种方式:实现Runnable接口,重写run

class MyThread3 implements Runnable{
@Override
public void run() {
while(true){
System.out.println("hello runnable");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class ThreadDemo3 {
public static void main(String[] args) {
Runnable runnable = new MyThread3();//只是一段可执行的代码
Thread t = new Thread(runnable);//还要搭配Thread类,才能真正在系统中创建出线程
t.start();
while(true){
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}这种写法其实就是把线程和要执行的任务进行了解耦合了
第三种写法:继承Thread,重写run,但是使用匿名内部类
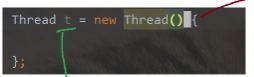
写{ }意思是要定义一个类,这个新类继承自Thread,此处{ }中可以定义子类的属性和方法。这里最主要重写run方法
public class ThreadDemo4 {
public static void main(String[] args) {
Thread t = new Thread(){
@Override
public void run() {
while(true){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
t.start();
while (true){
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}第四种方法:实现Runnable,重写run,实现匿名内部类
public class ThreadDemo5 {
public static void main(String[] args) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
while(true){
System.out.println("hello runnable");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
});
t.start();
while(true){
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}第五种方法:使用lambda表达式(推荐使用)
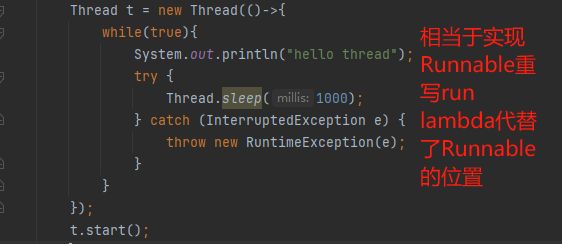
Thread构造方法有好几个版本,编译器在编译的时候挨个往里匹配,其中匹配到Runnable这个版本的时候发现run方法无参数,正好能和lambda对上
Thread其他属性和方法
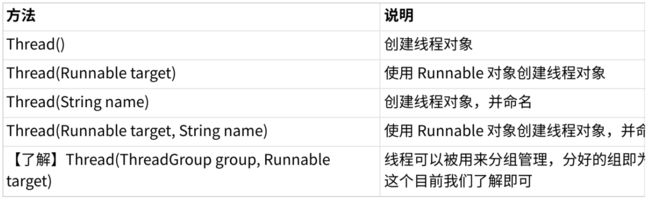
Thread(String name) :自己创建的线程,默认是按照Thread-0 1 2 3 ...
给线程起名字不会影响线程执行,只是方便调试
⚠线程之间的名字是可以重复的
public static void main(String[] args) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
while(true){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
},"这是我的线程");
t.start();
}运行起来查看一下线程
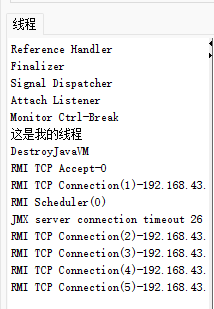 这里的“这是我的线程”就是刚刚创建的新线程
这里的“这是我的线程”就是刚刚创建的新线程
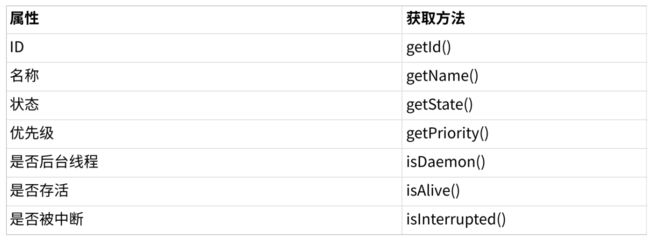
getId():JVM自动分配的身份标识,会保证唯一性
isDaemon:判断是否是守护线程(后台线程)
后台?
前台线程的运行会阻止进程结束
后台线程的运行不会阻止进程结束
观察我们上面的线程执行图,列表中已经没有main了,但是t仍在执行
此时的t就属于是前台线程,只要前台线程没执行完,进程就不会结束
把这个线程改成后台

我们发现啥都没打印,说明后台线程无法阻止进程结束
JVM里其他线程都是后台线程
isAlive:表示内核中的线程PCB是否还存在
当我们输入t.start()的时候就真正在内核中创建出这个PCB,此时isAlive就是true
⚠Java定义的线程对象的生命周期和内核中的PCB生命周期是不完全一样的
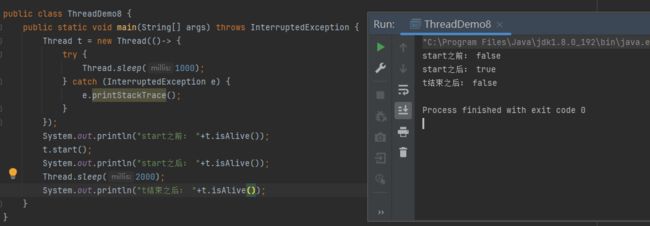
中断线程
让run()方法提前执行完毕,也就能提前终止线程了
private static boolean isQuit = false;
public static void main(String[] args) {
//lambda表达式本质上就是函数式接口,也就是匿名内部类,内部类访问外部类成员天经地义
Thread t = new Thread(()->{
while(!isQuit){
System.out.println("我是一个线程,工作中");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("线程工作完毕");
});
t.start();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("让进程结束");
isQuit = true;
}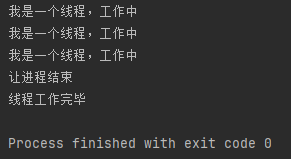
上面的代码是让main线程打印完毕之后才会设置isQuit,t线程的循环才会结束
如果是先isQuit = true之后再打印“让进程结束”的话,是主线程先进行打印还是t线程先进性打印就不确定了
诶?那能不能把isQuit写进main函数里把它变成局部变量呢?
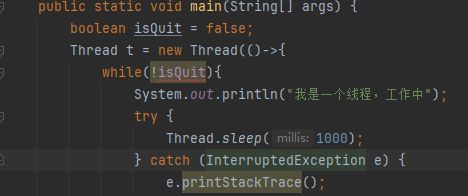 哦吼,编译出错!
哦吼,编译出错!
lambda表达式讲过一个语法:变量捕获,可以访问到外面定义的局部变量。那为啥还报错??
看看这里的报错信息,访问到的局部变量得是final或者事实final修饰的
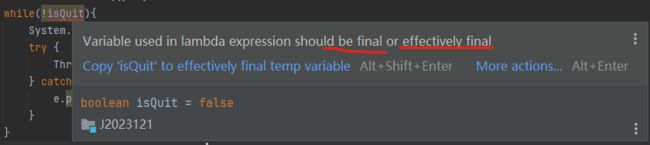
根据报错信息,我们得在上面加一个final
但是下面的isQuit = true又报错了,因为final定义的变量不能修改

所以嘞,isQuit无法作为局部变量
再继续挖~为啥Java这里对于变量捕获有final的限制?
isQuit是局部变量的时候是属于main方法的栈帧中,但是Thread lambda是有自己独立的栈帧的
这样可能导致main方法执行完了,栈帧销毁了,同时Thread的栈帧还存在,还想用isQuit。因为变量捕获本质上是传参,也就是让lambda表达式在自己的栈帧中创建一个新的isQuit,并把外面的isQuit的值拷贝进来
Java为了防止isQuit不同步,干脆不让你修改isQuit,就是让你加个final
上面那样写还不够优雅,下面推荐一手更优雅的写法
![]()
Thread提供了这种方法,用于获取当前的线程实例t
public class ThreadDemo13 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
//isInterrupted 判定标志位
while (!Thread.currentThread().isInterrupted()) {
System.out.println("我是一个线程, 正在工作中...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("线程执行完毕!");
});
t.start();
Thread.sleep(3000);
// 使用一个 interrupt 方法, 来修改刚才标志位的值,设置标志位
System.out.println("让 t 线程结束");
t.interrupt();
}
}t.interrupt相当于isQuit = true
但是上面的代码有一个报错异常,其实也是这里的interrupt导致sleep出现异常
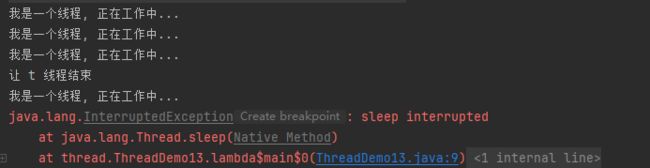
在在执行sleep的过程中,调用interrupt,大概率sleep的时间还没到,被提前唤醒了
提前唤醒的话程序会做两件事:
1. 抛出interruptedException(接着被catch到)
2. 清除Thread对象的isInterrupted标志位(sleep清除的)
sleep(1000),可能1000ms都没到就要终止线程,相当于前后两个矛盾的操作;
所以sleep清除标志位可以给程序员更多的可操作空间:
1)让线程提前结束(加break)
2)让线程不结束,继续执行(不加break)
3)让线程执行一些逻辑之后再结束(写其他代码再break)
要想让进程结束,只需要在catch里面加上break就行了
不想要打印异常信息就把![]() 这一行注释掉就行了
这一行注释掉就行了
实际开发中,catch里面需要写什么代码?
1. 尝试自动回复的程序
2. 记录日志(非严重的问题)
3. 发出报警(严重问题)
4. 少数正常业务逻辑(比如文件操作)
等待线程
前面提到,多个线程底层的执行顺序是不确定的
但是我们可以在应用程序中,通过一些api来影响线程的执行顺序
join关键字:影响线程结束的先后顺序
实现t2线程等待t1线程,就要让t1先结束,t2后结束;join可以使t2线程阻塞
t.join();
在main线程中调用上面这个代码,意思是让main线程等待t线程结束(t执行,main阻塞)
具体来说,执行join的时候会先看t线程是否正在运行,如果t运行中,main线程就会阻塞
t运行结束,main线程就会从阻塞状态恢复,继续往下执行
练习:让主线程创建一个新线程,由新线程负责1+2+...+1000的运算
public class ThreadDemo15 {
private static int result = 0;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
for (int i = 0; i <= 1000 ; i++) {
result += i;
}
});
t.start();
//使用sleep,但是不知道t线程要执行多久,sleep里面的时间不好填
//Thread.sleep(1000);
//使用join,严格按照t线程执行结束来作为等待条件
//什么时候t运行结束,什么时候join结束等待
t.join();
System.out.println("result: " + result);
}
}如果数据量大一点,可能这个线程就会计算的很慢,比如
i <= 10_0000_0000L
我们可以分多几个线程一起计算

三个线程兵分三路,并发执行(并发 = 并行(t和t2在两个不同核心上同时执行)+并发(t和t2在同一个核心上分时复用执行))
关于join的细挖
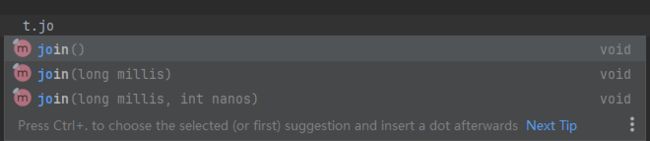
第一个join是死等,就一根筋一定要等到你的t线程执行完才能继续下一个线程
第二个是带有超时时间的等,等有一个时间上限的(超时时间),如果等待的时间超时了,那就不等了
获取线程引用
如果是继承Thread,直接使用this拿到线程实例
class MyThread5 extends Thread{
@Override
public void run() {
System.out.println(this.getId() + ", " + this.getName());
}
}
public class ThreadDemo16 {
public static void main(String[] args) {
MyThread5 t1 = new MyThread5();
MyThread5 t2 = new MyThread5();
t1.start();
t2.start();
System.out.println(t1.getId() + ", " + t1.getName());
System.out.println(t2.getId() + ", " + t2.getName());
}
}如果是Runnable 或者 lambda的方式,this就无能为力了,此时this已经不再指向Thread对象了
就只能使用Thread.currentThread
public class ThreadDemo17 {
public static void main(String[] args) {
Thread t1 = new Thread(()->{
Thread t = Thread.currentThread();
System.out.println(t.getName());
});
Thread t2 = new Thread(()->{
Thread t = Thread.currentThread();
System.out.println(t.getName());
});
t1.start();
t2.start();
}
}线程的状态/线程安全详见下一篇博客