一文入门Elasticsearch
大纲
Elasticsearch是什么?
Elasticsearch,分布式,高性能,高可用,可伸缩的搜索和分析系统。
Elasticsearch的适用场景
- 电商网站搜索
- 数据分析
- BI系统
- 日志分析 elk 等等
Lucene和Elasticsearch
- Lucene
Lucene是apache软件基金会 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)
- Elasticsearch
Elasticsearch是对于Lucene进行封装提供更加简易的APi给用户使用。每个Elasticsearch分片都是一个Lucene实例
基本概念
- Cluster
集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的。 config目录下的elasticsearch.yml文件
- Node
节点,集群中的一个节点,节点也有一个名称(默认是随机分配的),如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,一个节点也可以组成一个elasticsearch集群
- Document&field:
文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
- Index
索引,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
- Type
类型,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。 再7.0后慢慢舍弃了Type的概念:https://blog.csdn.net/zhanghongzheng3213/article/details/106281436/
样例:
商品index,里面存放了所有的商品数据,商品document
但是商品分很多种类,每个种类的document的field可能不太一样,比如说电器商品,可能还包含一些诸如售后时间范围这样的特殊field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊field
type,日化商品type,电器商品type,生鲜商品type
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一个type里面,都会包含一堆document
- aliases
别名。索引别名可以指向一个或多个索引,并且可以在任何需要索引名称的API中使用。 这个功能很强大,把多个索引合并成一个逻辑视图。
- shard
单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
- replica
任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
基本的API
集群/索引基本API
- 快速检查集群的健康状况
GET /_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1637731073 05:17:53 my.elk yellow 1 1 12 12 0 0 3 0 - 80.0%
// 这里解释下status字段, status字段是标识集群的健康状态的
green:每个索引的primary shard和replica shard都是active状态的
yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
- 查看全部索引
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open test2 MrmwSSNZQOyElfEZVAm0Bw 1 1 0 0 208b 208b
- 删除索引
DELETE /test_index?pretty
- 创建索引 注意这里只是创建最基本的索引,有些参数都是默认的,所以demo情况下可以这样操作,实际开发不可这样创建
PUT /test_index?pretty
简单crud
注意代码中有对列的含义的解释
- 新增
// id 可以指定也可以不指定,不指定的话,es会默认生成分布式id
// es会自动建立index和type,不需要提前创建,而且es默认会对document每个field都建立倒排索引,让其可以被搜索
PUT /index/type/id
{
"属性":"值"
}
// 样例:
PUT /test/test/1
{
"name":"xia",
"age":26
}
// 返回值
{
"_index" : "test", // 索引
"_type" : "test", // type
"_id" : "1", // 唯一文档标识符
"_version" : 1, // 老版本的并发控制版本号, es中使用乐观锁实现并发控制
"result" : "created", // created 标明本次文档操作是新建
"_shards" : { // 分片信息
"total" : 2, // 请求发到不同的分片,大部分分片正常响应,这些就是successful,如果某个分片没有响应,这就是failed
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0, // 新版本的并发控制版本号
"_primary_term" : 1 // 新版本的并发控制版本号
}
- 检索文档
GET /index/type/id
// 返回值
{
"_index" : "test",
"_type" : "test",
"_id" : "1",
"_version" : 1,
"_seq_no" : 4,
"_primary_term" : 1,
"found" : true,
"_source" : { // 文档实体
"name" : "xia",
"age" : 26
}
}
- 替换文档
// id是已经存在的, 这里会全量替换整个文档, es 底层会把历史文档修改为已删除(逻辑删除),然后新增
PUT /index/type/id
PUT /test/test/1
{
"name":"xia1",
"age":28
}
// 返回值
{
"_index" : "test",
"_type" : "test",
"_id" : "1",
"_version" : 2, // 版本号变动
"result" : "updated", // 本次是修改
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1, // 版本号
"_primary_term" : 1 // 这里是分片变动才会变动
}
- 更新文档 指定字段
POST /test/test/1/_update
{
"doc": {
"name": "xia2"
}
}
// 返回值
{
"_index" : "test",
"_type" : "test",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
- 删除文档
DELETE /test/test/1
// 返回值
{
"_index" : "test",
"_type" : "test",
"_id" : "1",
"_version" : 4,
"result" : "deleted", // 标识为删除
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
query DSL
- 查询全部
GET /test/test/_search
or
GET /test/test/_search
{
"query": { "match_all": {} }
}
// 返回值
{
"took" : 1, // 耗费了几毫秒
"timed_out" : false, // 是否超时 false没有
"_shards" : { // 数据有几个分片,搜索请求就会会打到几个primary shard(或者是它的某个replica shard也可以)
"total" : 1, // 总量
"successful" : 1, // 成功响应的
"skipped" : 0, // 跳过的
"failed" : 0 // 未响应的
},
"hits" : {
"total" : {
"value" : 1, // 查询结果的数量
"relation" : "eq"
},
"max_score" : 1.0, // score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
"hits" : [ // 包含了匹配搜索的document的详细数据
{
"_index" : "test",
"_type" : "test",
"_id" : "1",
"_score" : 1.0, // 当前文档的匹配值
"_source" : {
"name" : "xia",
"age" : 26
}
}
]
}
}
- 条件查询、排序、分页
GET /test/test/_search
{
"query" : {
"match" : {
"name" : "xia" // 匹配某个属性
}
},
"sort": [
{ "age": "desc" } // 排序
],
"from":2, // 分页初始偏移量
"size":1 // 分页本次偏移量
}
// 返回值 同上
- query filter
GET /test/test/_search
{
"query" : {
"bool" : {
"must" : {
"match" : {
"name" : "xia"
}
},
"filter" : {
"range" : {
"age" : { "gt" : 25 }
}
}
}
}
}
// and
GET /test/test/_search
{
"query":{
"bool":{
"must":[
{
"term":{
"name":"xia"
}
},
{
"term":{
"age":"2"
}
}
]
}
},
"from":0,
"size":10
}
- full-text search(全文检索)
GET /test/test/_search
{
"query" : {
"match" : {
// 先对’xia’进行分词, 然后和库里面的数据进行匹配
"name": "xia"
}
}
}
- phrase search(短语搜索)
GET /test/test/_search
{
"query" : {
"match_phrase" : {
// 要求输入的搜索串,必须在指定的字段文本中,完全包含一模一样的,才可以算匹配,才能作为结果返回
"name" : "xia"
}
}
}
- 定制返回结果
GET /test/test/_search
{
"query" : {
"bool" : {
"must" : {
"match" : {
"name" : "xia"
}
},
"filter" : {
"range" : {
"age" : { "gt" : 25 }
}
}
}
},
"_source":["age"] // 这里写你想要查询的属性
}
- highlight search(高亮搜索结果)。去百度吧,当作作业
聚合 聚合是Elasticsearch非常强的功能
- 简单聚合 注意 文本字段聚合需要将文本field的fielddata属性设置为true
GET /test/test/_search
{
"aggs": { // 简单分桶
"group_by_tags": { // 分桶的返回值属性
"terms": { "field": "age" }
}
},
"query" : { // 查询条件
"match" : {
"name": "xia"
}
},
"from":"0","size":2 // 这里是控制返回值 hits 的偏移量
}
// 返回值
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : { // 查询结果
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "test",
"_type" : "test",
"_id" : "1",
"_score" : 0.6931471,
"_source" : {
"name" : "xia",
"age" : 26
}
}
]
},
"aggregations" : { // 聚合结果
"group_by_tags" : { // 请求中定义分桶的返回值属性
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ // 聚合后的桶
{
"key" : 26, // key 已什么分桶, 同Mysql groupBy age
"doc_count" : 1 // 桶内文档的数量
}
]
}
}
}
- 先分组,再算每组的平均值
GET /test/test/_search
{
"size": 0,
"aggs" : {
"group_by_tags" : {
"terms" : { "field" : "name" },
"aggs" : {
"avg_price" : {
"avg" : { "field" : "age" }
}
}
}
}
}
// 返回值
{
"took" : 27,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "xia",
"doc_count" : 1,
"avg_price" : {
"value" : 26.0
}
}
]
}
}
}
3.排序
GET /test/test/_search
{
"size": 0,
"aggs" : {
"group_by_tags" : {
"terms" : { "field" : "name", "order": { "avg_price": "desc" } },
"aggs" : {
"avg_price" : {
"avg" : { "field" : "age" }
}
}
}
}
}
- Elasticsearch中支持嵌套桶,日期直方图。。。。 感兴趣的可以参考官网进行学习,https://www.elastic.co/guide/en/elasticsearch/reference/7.15/search-aggregations-bucket.html
Elasticsearch-SQL
在Elasticsearch高版本官方中已经支持sql了,虽然对sql支持度很高了,但是由于NoSql本身的限制,仍然有很多限制,例如:不支持JOIN, JDBC连接收费等。
简单使用
- 简单查询
GET /_sql?format=txt
{
"query": """ SELECT * FROM "test" limit 10 """
}
// 返回值
age |name
---------------+---------------
26 |xia
GET /_sql
{
"query": """ SELECT * FROM "test" limit 10 """ // " sql 语句 " 这样也行, 但是只能使用''
}
// 返回值
{
"columns" : [ 、 // 表头
{
"name" : "age", // 属性
"type" : "long" // 类型
},
{
"name" : "name",
"type" : "text"
}
],
"rows" : [
[
26,
"xia"
]
]
}
- 将SQL转化为DSL
GET /_sql/translate
{
"query": """
SELECT * FROM "test" limit 10
"""
}
// 返回值
{
"size" : 10,
"_source" : false,
"fields" : [ // 查询的字段
{
"field" : "age"
},
{
"field" : "name"
}
],
"sort" : [
{
"_doc" : {
"order" : "asc"
}
}
]
}
- 混用
GET /_sql
{
"query": """
SELECT * FROM "test" limit 10
""",
"filter":{
"range": {
"age": {
"gte" : 20,
"lte" : 35
}
}
},
"fetch_size": 10
}
// 返回值同上
- 嵌套对象
PUT /test_index/sql_type/1
{
"name":"xia",
"info":{
"iphone":"1352468487"
}
}
GET /_sql
{
"query": """
SELECT name, info.iphone FROM "test_index" limit 10 // 如果直接查询* 就会报错
"""
}
// 对数组支持并不友好,暂时未找到解决方式
- 语法
SELECT select_expr [, …]
[ FROM table_name ]
[ WHERE condition ]
[ GROUP BY grouping_element [, …] ]
[ HAVING condition]
[ ORDER BY expression [ ASC | DESC ] [, …] ]
[ LIMIT [ count ] ]
[ PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, …] ) )]
脚本
| 语言 | 沙盒 | 必需的插件 | 目的 |
|---|---|---|---|
| painless | 支持 | 内置 | 专为 Elasticsearch 而构建 |
| expression | 支持 | 内置 | 快速自定义排名和排序 |
| mustache | 支持 | 内置 | 模板 |
| Java | 自己写 | API |
介绍
通过编写脚本,用户可以在 Elasticsearch 中计算自定义表达式,所以在解决复杂问题(自定义评分、自定义文本相关度、自定义过滤、自定义聚合分析)时,脚本依然是Elasticsearch强悍的利器之一。 下文以painless 来进行讲解。
Painless是一种简单,安全的脚本语言,专为与Elasticsearch一起使用而设计。它是Elasticsearch的默认脚本语言,可以安全地用于内联和存储脚本。
- 高效:Painless直接编译成JVM字节码,以利用JVM提供的所有可能的优化。此外,Painless 通常避免在运行时需要额外进行较慢检查的功能。
- 安全性强:使用白名单来限制函数与字段的访问,避免了可能的安全隐患。
- 可选输入:变量和参数可以使用显式类型或动态def类型。
- 简单: :Painless实现了一种语法,对于任何具有一些基本编码经验的人来说,它都是天生熟悉的。Painless使用Java语法的子集,并进行了一些额外的改进,以增强可读性并删除样板
使用
GET test/_search
{
"script_fields": {
"my_doubled_field": { // 返回的属性值
"script": {
"source": "doc['age'].value * params['multiplier']", // 把age字段 * 输入参数 'multiplier'
"params": {
"multiplier": 2 // 输入参数 可以多个输入参数
}
}
}
}
}
// 返回值
{
"took" : 30,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "test",
"_id" : "1",
"_score" : 1.0,
"fields" : {
"my_doubled_field" : [ // 结果
52
]
}
}
]
}
}
// 聚合
1GET test/_search
{
"aggs" : {
"groups" : {
"terms" : {
"script" : {
"source": "doc['age'].value",
"lang": "painless"
}
}
}
}
}
存储脚本
POST _scripts/calculate-score // calculate-score 标识符,类似方法名
{
"script": {
"lang": "painless",
"source": "Math.log(_score * 2) + params['my_modifier']"
}
}
// 获取
GET _scripts/calculate-score
自定义评分
GET test/_search
{
"query": {
"script_score": { // 脚本评分
"query": {
"match": {
"name": "xia"
}
},
"script": { // 使用脚本
"id": "calculate-score", // 存储的脚本id
"params": { // 输入参数
"my_modifier": 2
}
}
}
}
}
// 返回值
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.3266342, // 这里
"hits" : [
{
"_index" : "test",
"_type" : "test",
"_id" : "1",
"_score" : 2.3266342, // 结果
"_source" : {
"name" : "xia",
"age" : 26
}
}
]
}
}
为什么可以用于搜索引擎 快? 快在哪里
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
倒排索引
- 什么是倒排索引?
我的理解就是把属性的值当作索引,然后指向具体的地址,形如mysql 的普通索引 就是反向索引 , 先找key 再找行记录。key可以对应多个行记录,只是匹配值不同。
- 官网详解倒排索引
例如,假设我们有两个文档,每个文档的 content 域包含如下内容:
The quick brown fox jumped over the lazy dog
Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,es首先将每个文档的 content 域拆分成单独的 词(一般称为为 词条 或 tokens ),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。结果如下所示:
Term Doc_1 Doc_2
-------------------------
Quick | | X
The | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
quick | X |
summer | | X
the | X |
------------------------
现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:
Term Doc_1 Doc_2
-------------------------
brown | X | X
quick | X |
------------------------
Total | 2 | 1
两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 ,那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
这就完美了吗?并不是,现有如下问题
- Quick 和 quick 以独立的词条出现,然而用户可能认为它们是相同的词。
- fox 和 foxes 非常相似, 就像 dog 和 dogs ;他们有相同的词根。
- jumped 和 leap, 尽管没有相同的词根,但他们的意思很相近。他们是同义词。
使用前面的索引搜索 +Quick +fox 不会得到任何匹配文档。(记住,+ 前缀表明这个词必须存在。)只有同时出现 Quick 和 fox 的文档才满足这个查询条件,但是第一个文档包含 quick fox ,第二个文档包含 Quick foxes 。
如果我们希望能匹配到对应的两个文档,应该如何做?
例如:
- Quick 可以小写化为 quick 。
- foxes 可以 词干提取 --变为词根的格式-- 为 fox 。类似的, dogs 可以为提取为 dog 。
- jumped 和 leap 是同义词,可以索引为相同的单词 jump 。
那么现在索引是这样的
Term Doc_1 Doc_2
-------------------------
brown | X | X
dog | X | X
fox | X | X
in | | X
jump | X | X
lazy | X | X
over | X | X
quick | X | X
summer | | X
the | X | X
------------------------
这样其实我们搜索+Quick +fox 仍然会失败,因为在我们的索引中,已经没有 Quick 了。所以我们需要在搜索输入时,和创建倒排索引时使用相同的分词方法。 再下文笔者将讲解分词器。
- 工作中分词粒度
建立倒排索引的时候细粒度分词 搜索的输入短语进行分词时时候用粗粒度分词,这样能有效的匹配到需要匹配的数据。
分词器&分析器&字符过滤器&令牌过滤器
- 什么是分词器 (Tokenizer)
字符串分解成单个词条或者词汇组的代码,标准分析器里使用的标准分词器把一个字符串根据单词边界分解成单个词条,并且移除掉大部分的标点符号。 例如: 我是中国人, 通过分词器规则 分成词组 我是、中国、人。
一个分析器包含一个分词器
2.字符过滤器(character filter)
字符过滤器用来整理一个尚未被分词的字符串。
例如,如果我们的文本是HTML格式的,它会包含像
或者
我们可以使用 html清除字符过滤器来移除掉所有的HTML标,
并且像把 Á 转换为相对应的Unicode字符 Á 这样,来转换HTML实体。
一个分析器可能有0个或者多个字符过滤器。
3.令牌过滤器
经过分词,作为结果的词组会按照指定的顺序通过指定的令牌过滤器 。
令牌过滤器可以修改、添加或者移除词组元素。
在 Elasticsearch里面还有很多可供选择的令牌过滤器。 词干过滤器 把单词遏制为词干。
ascii_folding 过滤器移除变音符,把一个像 “très” 这样的词转换为 “tres” 。
ngram 和 edge_ngram 词单元过滤器 可以产生适合用于部分匹配或者自动补全的词单元。
- 什么是分析器 (Analyzer)
把一个未处理的文本字段,进行标准化处理,形成倒排索引需要的词组。
- 内置分词器&分析器&字符过滤器&令牌过滤器。
分析器
- 标准分析器(默认):standard分析器将文本分为在字边界条件,如通过Unicode文本分割算法定义。它删除了大多数标点符号、小写术语,并支持删除停用词。
- 简单分析器:简单分析器在任何不是字母的地方分隔文本,将词条小写。
- 空格分析器:空格分析器在空格的地方划分文本。
- 空白分析器:文本每当遇到任何空白字符进行划分。它不使用小写术语。
- 停止分析器:停止分析仪和简单分析器 ,但增加了对移除停止字的支持。它默认使用_english_停止词。
- 关键字分析器:该分析器非常简单,它只是将提供的取值全部放行。也可以把相应的字段指定为not_analyzed达到相同的目的。
- 模式分析器:该分析器允许利用正则表达式对文本进行灵活的划分。
- 语言分析器:为特定语言设计的分析器,例如english或 french。
分词器
- 标准分词器:将文本分为单词边界条件,由Unicode文本分割算法定义。它删除了大多数标点符号。默认分词
- 小写分词器:在遇到不是字母的字符时将文本分成词条,但它也会将所有词条小写。
- 空白分词器:每次遇到空格进行分词
- N-Gram 分词器:所述ngram分词器可以分解文本成单词,当它遇到任何指定的字符的列表(例如,空格或标点),则它返回的n-gram的每个单词的:连续字母的滑动窗口,例如quick→ [qu, ui, ic, ck]。
在Elasticsearch内置了很多的分词器,感兴趣的可以去官网查看
https://www.elastic.co/guide/en/elasticsearch/reference/7.15/analysis-tokenizers.html
字符过滤器
- HTML字符过滤器:可以对html符号进行预处理
- 正则替换字符过滤器:通过正则表达式进行预处理
- 映射字符过滤器: 可以对配置的字符进行处理
令牌过滤
- 小写: 将结果文本小写,例如,把THE Lazy DoG更改为the lazy dog。
- 删除重复词:删除相同位置的重复词。
在Elasticsearch内置了很多的过滤器,感兴趣的可以去官网查看
https://www.elastic.co/guide/en/elasticsearch/reference/7.15/analysis-tokenfilters.html
- 自定义分词器之IK分词器
在elasticsearch中查询数据,使用默认的分词器,分词效果不太理想。会把字段分成一个一个汉字,搜索时会把搜索到的句子进行分词,非常不智能,所以出现了替换产品【IK分词器】
gitHub地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
- 分词核心 字典树
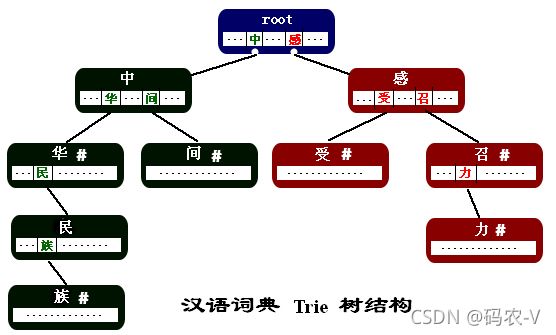
单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高
Trie树的三个性质:
根节点不包含字符,除根节点外每一个节点都只包含一个字符
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串
每个节点的所有子节点包含的字符都不相同
分析器工作流程
-
首先,字符过滤器对分析(analyzed)文本进行过滤和处理,例如从原始文本中移除HTML标记,根据字符映射替换文本等,
-
过滤之后的文本被分词器接收,分词器把文本分割成标记流,也就是一个接一个的标记,
-
然后,令牌过滤器对标记流进行过滤处理,例如,移除停用词,把词转换成其词干形式,把词转换成其同义词等,
-
最终,过滤之后的标记流被存储在倒排索引中;
-
ElasticSearch引擎在收到用户的查询请求时,会使用分析器对查询条件进行分析,根据分析的结构,重新构造查询,以搜索倒排索引,完成全文搜索请求,
分布式执行搜索
在ElasticSearch中,分布式存储和执行也是提升效率的一大方式,毕竟单点系统的瓶颈是客观存在的。那么ElasticSearch中是如何对数据进行分布式查询的呢?
在ElasticSearch中执行分为两个阶段,在ElasticSearch中称之为 query then fetch
1. 查询阶段
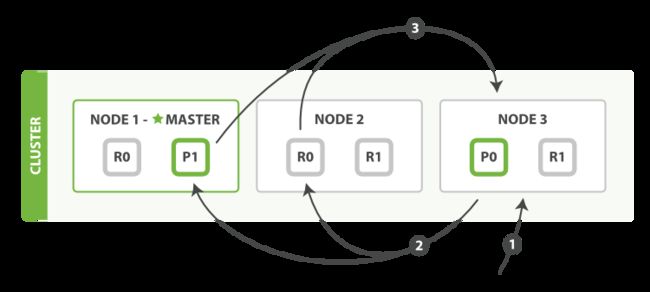
查询阶段包含以下三个步骤:
- 客户端发送一个 search 请求到 Node 3 , Node 3 会创建一个大小为 from + size 的空优先队列。
- Node 3 将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为 from + size 的本地有序优先队列中。
- 每个分片返回各自优先队列中所有文档的 ID和排序值给协调节点,也就是 Node 3,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
当一个搜索请求被发送到某个节点时,这个节点就变成了协调节点。 这个节点的任务是广播查询请求到所有相关分片并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
第一步是广播请求到索引中每一个节点的分片拷贝。 查询请求可以被某个主分片或某个副本分片处理, 这就是为什么更多的副本(当结合更多的硬件)能够增加搜索吞吐率。 协调节点将在之后的请求中轮询所有的分片拷贝来分摊负载。
每个分片在本地执行查询请求并且创建一个长度为 from + size 的优先队列—也就是说,每个分片创建的结果集足够大,均可以满足全局的搜索请求。 分片返回一个轻量级的结果列表到协调节点,它仅包含文档 ID 集合以及任何排序需要用到的值,例如 _score 。
协调节点将这些分片级的结果合并到自己的有序优先队列里,它代表了全局排序结果集合。至此查询过程结束。
2. 取回阶段
取回阶段由以下步骤构成:
- 协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。
- 每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。
- 一旦所有的文档都被取回了,协调节点返回结果给客户端。
协调节点首先决定哪些文档 确实 需要被取回。例如,如果我们的查询指定了 { “from”: 90, “size”: 10 } ,最初的90个结果会被丢弃,只有从第91个开始的10个结果需要被取回。这些文档可能来自和最初搜索请求有关的一个、多个甚至全部分片。
协调节点给持有相关文档的每个分片创建一个 multi-get request ,并发送请求给同样处理查询阶段的分片副本。
分片加载文档体-- _source 字段—如果有需要,用元数据和 search snippet highlighting 丰富结果文档。 一旦协调节点接收到所有的结果文档,它就组装这些结果为单个响应返回给客户端。
当然Elasticsearch远远不止这些,希望大家多去研究,看官网
官网地址:https://www.elastic.co/cn/
关注我的公众号,领取海量学习资料、面试资料,交流技术方案
