Javac编译原理
文章目录
-
- 1. Javac是什么
- 2. Javac编译器的基本结构
- 3. Javac工作原理分析
1. Javac是什么
Javac是一种编译器,能将一种语言规范转成另一种语言规范,javac编译器将Java编译器对所有机器都非常友好的一种语言。注意这种语言不是针对某个机器的,甚至包括不同种类,不同平台的机器。如果消除不同种类、不同平台机器之间的差别,这个任务就由jvm来完成,而javac的任务就是将java源代码语言先转换成JVM能够识别的一种语言,然后由JVM将JVM语言再转化成当前这个机器能够识别的机器语言。所以这样看来,Java语言要比其它语言多一层转换,这一层转换虽然牺牲了一些执行效率,但是向Java语言的开发者屏蔽了很多和目标机器相关的细节,使得Java语言的执行和平台无关,这也成就了Java语言的繁荣。
2. Javac编译器的基本结构
Javac编译器的作用就是将符合Java语言规范的源代码转化成符合Java虚拟机规范的字节码。
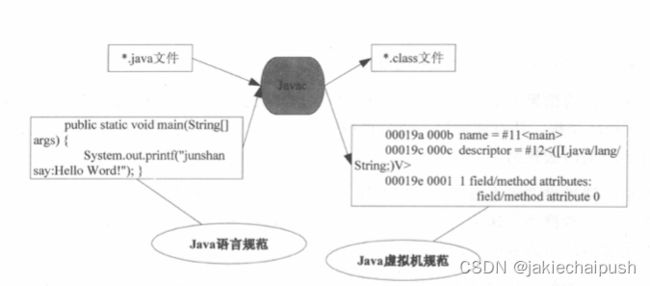
要理解Javac编译器,我们需要先了解编译程序的过程 。
- 首先,要读取源代码,一个字节一个字节读进来,找出哪些是我们定义的语法关键字,如java的if、else、for、while等,要识别哪些if是合法的关键词、哪些不是,这个步骤也就是词法分析的过程。词法分析的结果是从源代码中找出一些规范化的Token流,就像人类语言中,给你一句话你要分辨哪些是一个词语、哪些是标点符号、哪些是动词、哪些是名词等。
- 接着就是对这些Token流进行语法分析,这一步就是检查这些关键字组合在一起是不是符号Java语言规范,即检查语法是否正确。语法分析的结果就是形成一个符合Java语言规范的抽象语法树,抽象语法树是一个结构化的语法表达形式,它的作用是把语言的主要词法用一个结构化的形式组织在一起。
- 接下来是语义分析,虽然上面一步中语法分析已经完成,也就不存在语法问题了,但是语义是不是正确?语义分析的主要工作是把一些难懂的、复杂的语法转化为更加简单的语法(如把文言文翻译成白话文)。语义分析的结果是将复杂的语法转化成简单的语法,对应到java中,如将foreach转成for循环结构,还有注解等,最后形成一个注解过后的抽象语法树,这棵语法树更接近目标的语法规则。
- 最后,通过字节码生成器生成字节码,将会根据经过注解的抽象语法树生成字节码,也就是将一个数据结构转换成另一个数据结构。
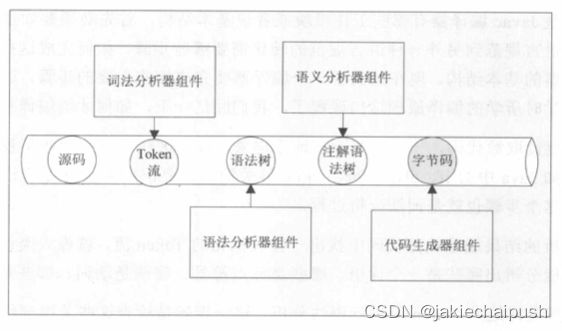
javac各个模块就是完成了将Java源代码转变成Java字节码的任务,所以Javac主要就有四大模块,分别是词法分析器、语法分析器、语义分析器和代码生成器。
3. Javac工作原理分析
这一节将详细分析如何从java的源文件一步步转化成calss文件的过程。
- 词法分析器
定义如下类:
class Cifa{
int a;
int c=a+1;
}
然后调用compile(String[])方法来编译cifa这个类
public static int compile(String[] args){
com.sun.tools.javac.main.Main compiler= new com.sun.tools.javac.main.Main("javac");
return compiler.compile(args).ordinal();
}
在分析Javac如何编译这个类之前,先看一下Javac关于词法分析器的类结构,Javac的主要词法分析器的接口类是com.sun.tools.javac.parser.Lexer,它的默认实现类是com.sun.tools.javac.parser.Scanner,Scanner会逐个读取Java源文件的单个字符,然后解析出符合java语言规范的Token序列。
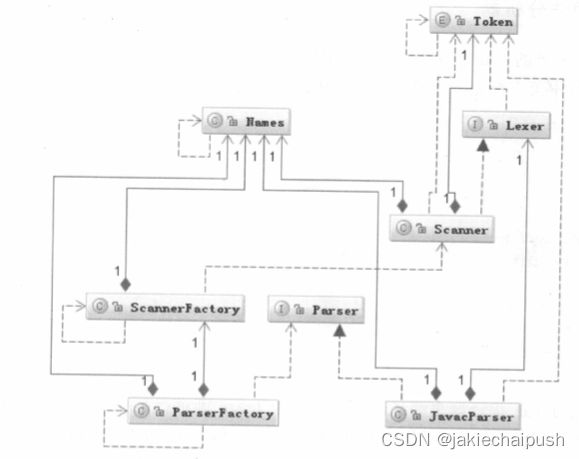
从类关系图可以看出,由两个Factory生成了两个接口的实现类Scanner和JavacParser。这两个类负责整个词法分析的过程控制。JavacParser规定哪些词是符合Java 语言规范的词,而汲取读取和归类不同词法的操作由Scanner完成。Token规定类所有java语言的合法关键词,Names用来存储和表示解析后的词法。
词法分析过程是在javacParser的parserCompilationUnit方法中完成
,该方法总源文件的一个字符开始,按照java语法规范依次找出package、import、类定义一季熟悉和方法定义等,最后构建一个抽象语法树。词法分析的结果就是将这个类的所有关键词匹配到Token类的所有项中的任何一项,如上面类的结果就是:第一个Token是Token.PACKAGE,接着是一个Token.IDENTIFIER,后面是Token.SEMI,再后面是类的修饰符Token.PUBLIC ,然后是类的关键词Token.CLASS,后面是类名Token.IDENTIFIER,接着是Token.LBRACE;再然后就是类的属性定义了,变量类型为Token .INT,变量名为Token.IDENTIFIER,后面跟着Token.SEMI,最后类的结束符Token.RBRACE
上面cifa对应的Token流是

这样经过词法分析器的处理,java源代码就变成了Token流了。
- 语法分析器
词法分析器的作用是将Java源文件的字符流转换为对应的Token流。而语法分析器的作用是将词法分析器分析的Token流组建为更加结构化的语法树,也就是将一个一个单词组装成一句话,一个完整的语句。Javac的语法树使得Java源码更加结构化,这种结构化可以为后面进一步处理提供方便,每个语法树上的节点com.sum.tools.javac.tree.JCTree的一个实例,关于语法树有一些规则:
- 每个语法节点都会实现一个接口xxxTree,这个接口又继承于
com.sun.source.tree.Tree接口,如IfTree 语法节点表示一个if类型的表达式,BinaryTree语法节点代表一个二元操作表达式 - 每个语法节点都是
com.sun.tools.javac.tree.JCTree的子类,并且会实现第一点中的xxxTree接口类,这个类的类名类似于JCxxx,如实现IfTree接口的实现类为JCIF,实现BinaryTree接口的类为JCBinary - 所有的JCxxx类都作为一个静态内部类定义在JCTree中
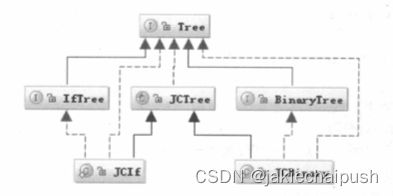
JCTree类中有如下三个重要的属性项:
4. Tree tag:每个语法节点都会用一个整型常数表示,并且每个节点类型的数组是在前一个基础上加1。顶层节点TOPLEVEL是1,而IMPORT节点等于TOPLEVEL加1,等于2
5. pos:也是一个常数,它存储的是这个语法节点在源代码的起始位置,一个文件的一个位置是0,-1表示是一个不存在的位置
6. try:它表示这个节点是什么java类型,如int、float还是String
下面来分析cifa的语法树:
构建Import语法树
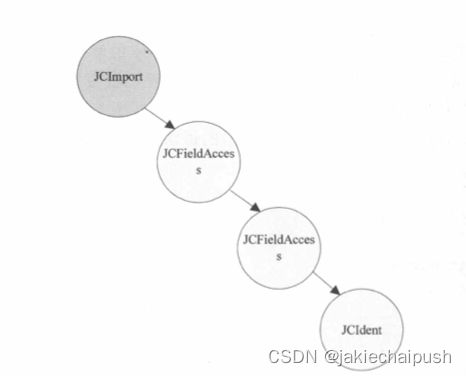
首先检查Token是不是Token.IMPORT,如果是用import的语法规则来解析import节点,最后构造一个import语法树。(JCFieldAccess代表每一级目录,是一种嵌套关系,JCIdent代表结束)
类的解析
Import节点解析完成后就是类的解析类,包括interface、class、enum。下面一解析Class为例子,第一个Token是Token.CLASS这个关键字,接下来是用户自定义的Token.IDENTIFIER,这个Token也就是类名。接下去是这个类的类型可选参数,将这个参数解析成JCTypeParameter语法节点,下一个Token是或者是Token.EXTENDS或者Token.IMPLEMENTS。然后是classBody解析,classBody解析也是按照变量定义解析、方法定义解析和内部类定义解析进行的。这个解析过程比较复杂,节点也比较多,整个classBody解析结果保存在一个list集合中,最后将会把这些节点添加到JCClassDecl这棵class树中。如下面这个类:
public class Yufa{
int a;
private int c=a+1;
public int getC(){
return c;
}
public void setC(int c){
this.c=c;
}
}

未来理解简单上面语法树省略掉了一些节点
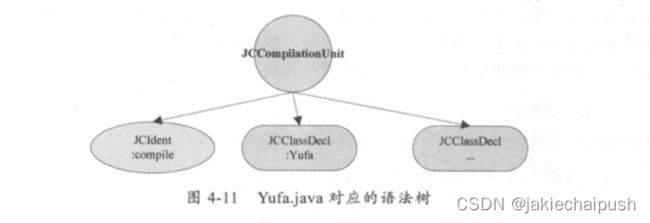
当这个类解析完成后,会接着将这个类节点加到这个类对应的包路径的顶层节点中,这个顶层节点就是JCCompilationUnit。JCComplilationUnit持有package作为pid和JCClassDecl的结合,这样整个xxx.java的文件就被解析完成了,这棵语法树如图所示:
所有的语法节点的生成都是在TreeMaker类中完成的,TreeMaker实现了JCTree.Factory接口中定义的所有节点的构成方法。
- 语义分析器
前吗介绍了将一个Java源文件先解析成一个一个的Token流,然后再经过语法分析器将Token流解析成更加结构化的、可操作的语法树,但是这棵语法树还是太粗糙了,离我们的Java字节码还是有点差距的。我们必须要在这棵语法树的基础上再做一些处理,如给类添加默认的构造函数、检查变量在使用前是否初始化、将一些常量进行类合并处理、检查操作变量类型是否匹配、检查所有的操作语句是否可达、检查checker exception异常是否已经捕获或抛出、解除java的语法糖等,当这些操作都完成后就可以按照这棵树形成我们的字节码文件了。
语法糖的存在主要是方便开发人员使用。但其实, Java 虚拟机并不支持这些语法糖。这些语法糖在编译阶段就会被还原成简单的基础语法结构,这个过程就是解语法糖。Java 中最常用的语法糖主要有泛型、变长参数、条件编译、自动拆装箱、内部类等。
在Java类中符号输入到符号表主要由com.sun.tools.javac.comp.Enter类完成,这个类主要执行下面两个步骤:
- 将所有类中出现的符号输入到类自身的符号表中,所有类符号、类的参数类型符号(范型参数类型)、超类符号和继承的接口类型符号都存储在一个未处理列表中(class文件的常量池)
- 将这个未处理的列表中的所有类都解析道各自的类符号列表 中,这个操作狮子啊Member.coplete()中完成的
其实两个步骤很好理解,首先一个类除了类本身会定义一些符号变量外,如类名词、变量名称和方法名称等,还有一些符号引用其他类的,符号调用其他类的方法或者变量等,还有一些这个类可能会继承或者实现超类和接口等。这些符号都是在其他类中定义的,那么就需要将这些类的符号也解析到符号表中。第二个步骤自然就是按照递归向下的顺序解析语法树,将所有的符号都输入到符号表中。
在Enter解析这个过程中,一个重要过程就是给源码添加默认构造函数
符号表输入完成后,下一个步骤就是处理annotation(注解),这个步骤是由com.sun.tools.javac.processing.JavacProcessingEnviroment类完成的。
再接下去是com.sun.tools.javac.comp.Attr(标注),这个步骤最重要的是检查语义的合法性和进行逻辑判断,如:
- 变量类型是是否匹配
- 变量使用前是否初始化
- 能够推到出范型方法的参数类型(解语法糖)
- 字符串合并
这个步骤除了使用Attr类外,还需要其他类来协助,如:
com.sun.tools.javac.comp.Check:辅助Attr检查语法树中的变量类型是否正确,如二元操作符两边的操作数的类型是否相等,返回的类型是否于接收的引用类型匹配等com.sun.tools.javac.comp.Resolve:主要检查变量、方法或者类的访问是否合法、变量是否为静态变量、变量是否已经初始化等com.sun.tools.javac.comp.ConstFole:常量折叠,这里主要针对字符串常量,会将一个字符串常量中的多个字符串合并为一个字符串
如String s=“a”+“b”;Attr解析后会变成String s=“ab”;
com.sun.tools.javac.comp.Infer:帮助推导范型方法的参数类型
标注完成后就是com.sun.tools.javac.comp.Flow类完成数据流分析,数据流分析主要做如下工作:
- 检查变量在使用前是否正确赋值,除了java中的原始类型,如int、long、byte、double、char、float,都会有默认初始值,其他像String类型和对象的引用都必须在使用前赋值
- 保证final修饰变量不会被重复赋值
- 方法返回值类型要确定
- 所有Checked Exception都要捕获或者向上抛出
- 所有的语句都要被执行到
总体来说这个过程是进一步对语法树进行语义分析,如消除一些无用的代码,永不真的条件将被去除。还有就是解除一些语法糖,如将foreach这种语法解析成标准的for循环形式,还有就是int和Integer等着中类型的子哦那个转换操作等。
- 代码生成器
经过语义分析器完成的语法树已经非常完美了,接下来会调用com.sun.tools.javac.jvm.Gen类遍历语法树生成最终的Java字节码了。这主要经过两个步骤:
- 将java方法中的代码转成符合JVM语法的命令形式,JVM的操作都是基于栈的,所有的操作都必须进过出栈和进栈来完成
- 按照JVM的文件组织格式将字节码输出到以class为扩展名的文件中
生成字节码除了Gen类之外还有两个非常重要的辅助类,它们是:
3. Items:这个类表示任何可寻址的操作项,这些包括本地变量、类实例变量或者常量池中用户自定义常量等,这些操作项都可以作为一个单位出现在操作栈上
4. Code:存储生成的字节码和提供一些能够快速映射操作码的方法
下面来一个例子讲解一下:
public class Daima{
public static void main(String[] args){
int rt=add(1,2);
}
public static int add(Integer a,Integer b){
return a+b;
}
}
这个方法中有一个加法表达式,我们知道Jvm是基于栈来操作操作数的,所以加法的流程可有如下表示:

上面的每个步骤都会由对应的方法来处理,计算表达式结果用Gen类中的getExpr方法,这个方法有两个参数,分别是JCTree(表达式对应的语法节点树)和Type(所期望的类型,这里是int)。getExpr返回值类型为Item(栈上操作单元都是Item对象)。不同的类型的Item对应不同的JVM操作码,这里就不详细介绍了。具体解析流程如下:

至此java文件解析class文件的过程已经结束。