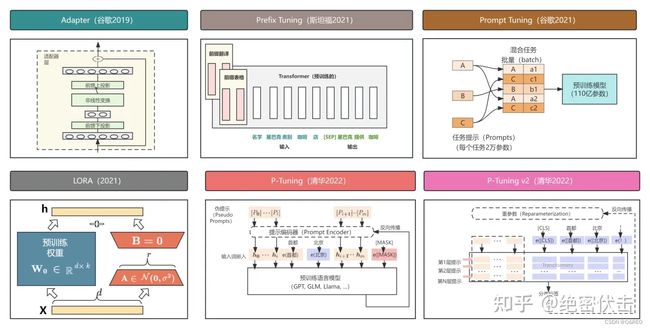
简述大模型微调方案:Prefix-Tuning Prompt-Tuning P-Tuning Lora QLora IA3 PEFT
Prefix Tuning
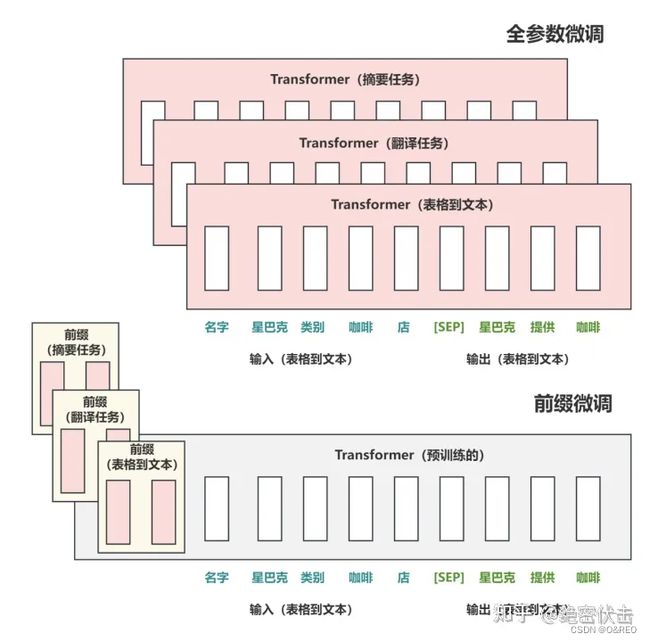
2021年斯坦福的研究人员在论文《Prefix-Tuning: Optimizing Continuous Prompts for Generation》中提出了 Prefix Tuning 方法。与Full-finetuning 更新所有参数的方式不同,该方法是在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。该方法其实和构造 Prompt 类似,只是 Prompt 是人为构造的“显式”的提示,并且无法更新参数,而Prefix 则是可以学习的“隐式”的提示。
Prompt-Tuning
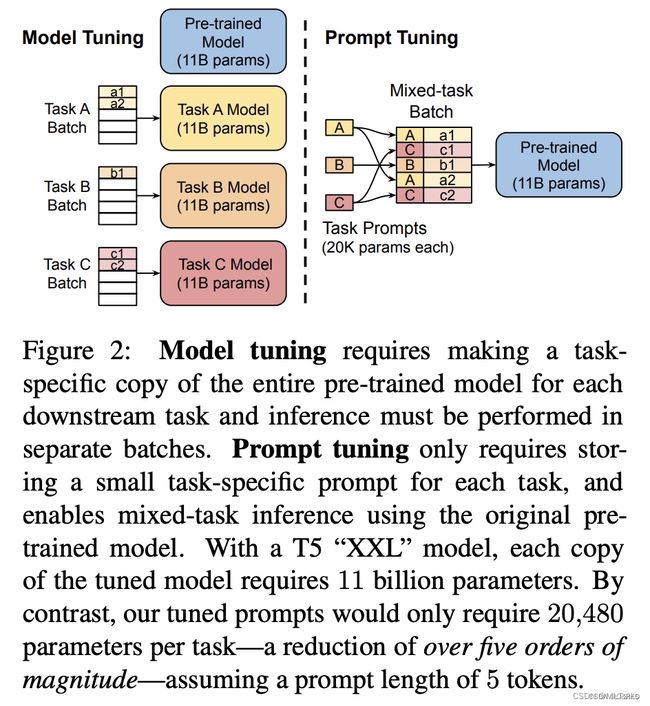
该方法可以看作是 Prefix Tuning 的简化版本,只在输入层加入 prompt tokens,并不需要加入 MLP 进行调整来解决难训练的问题https://arxiv.org/pdf/2104.08691.pdf

Figure 4: Parameter usage of various adaptation techniques
Prefix Tuning: Activations are tuned in the prefix of each layer, requiring 0.1–1% task-specific parameters for inference, but more are used for training.
Prompt Tuning: Only prompt embeddings are tuned, reaching under 0.01% for most model sizes

P-Tuning
该方法将Prompt转换为可以学习的Embedding层,并用MLP/LSTM的方式来对Prompt Embedding进行处理。
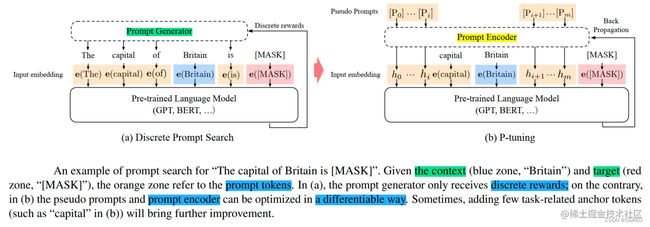
相比Prefix Tuning,P-Tuning加入的可微的virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的。这里的出发点实际是把传统人工设计模版中的真实token替换成可微调的virtual token。


Lora
利用 LoRA 可以锁定原模型参数不参与训练,只训练少量 LoRA 参数的特性使得训练所需的显存大大减少。
可以对多个不同的任务分别训练多个 LoRA 模块,部署推理时只部署一份主干模型,根据不同的任务换着使用不同的 LoRA 模块,大大节省显存。

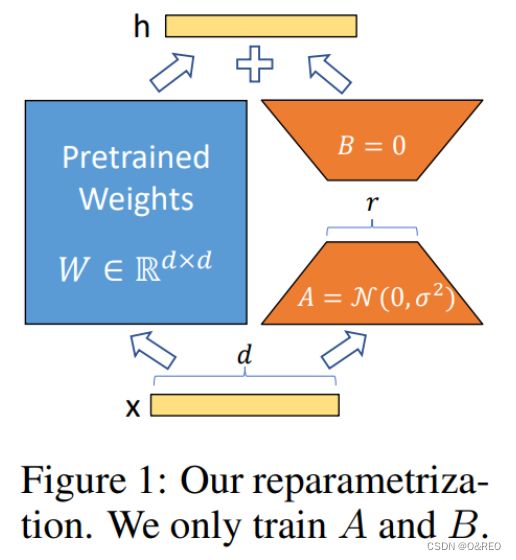

QLora
QLoRA,重点改进是将模型采用 4bit 量化后加载,训练时把数值反量化到 bf16 后进行训练。
llama7B+lora

llama7b+50000中文数据集

lit-llama尝试lora 微调后vs微调前
IA3
IA3(论文:Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning),通过学习向量来对激活层加权进行缩放,从而获得更强的性能,同时仅引入相对少量的新参数,如下图左边所示,它的诞生背景是为了改进 LoRA。IA3 权重被添加到 Transformer 模型的 key, value 和 feedforward 层
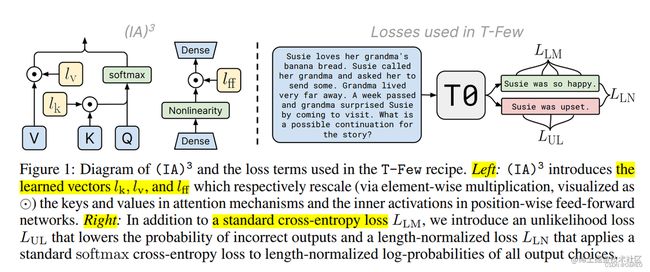
为了使微调更有效,IA3(通过抑制和放大内部激活注入适配器)使用学习向量重新调整内部激活。 这些学习到的向量被注入到典型的基于transformer的架构中的attention和feedforward模块中。 原始权重保持冻结,这些学习到的向量是微调期间唯一可训练的参数。 与学习 LoRA 更新低秩权重矩阵不同,处理学习向量可以使可训练参数的数量少得多。
与 LoRA 类似,IA3 具有许多相同的优点:
-
IA3 通过大幅减少可训练参数的数量,使微调更加高效。对于 T0 模型,使用 IA3 只有大约 0.01% 的可训练参数,而使用 LoRA 有 > 0.1% 的可训练参数。
-
原始的预训练权重保持冻结状态,这意味着您可以拥有多个轻量级、便携式 IA3 模型,用于在其之上构建的各种下游任务。
-
使用 IA3 微调的模型的性能与完全微调的模型的性能相当。
-
IA3 不会增加任何推理延迟,因为适配器(adapter)权重可以与基础模型合并。
原则上,IA3 可以应用于神经网络中权重矩阵的任何子集,以减少可训练参数的数量。 根据作者的实现,IA3 权重被添加到 Transformer 模型的 key, value 和 feedforward 层。 给定注入 IA3 参数的目标层,可训练参数的数量可以根据权重矩阵的大小确定。

PEFT
PEFT 可以使 PLM 高效适应各种下游应用任务,而无需微调预训练模型的所有参数。 微调大规模 PLM 所需的资源成本通常高得令人望而却步。 在这方面,PEFT 方法仅微调少量或额外的模型参数,固定大部分预训练参数,大大降低了计算和存储成本,同时最先进的 PEFT 技术也能实现了与全量微调相当的性能。

Huggface 开源的一个高效微调大模型的库PEFT,该算法库支持以下四类方法:
LoRA: LoRA: Low-Rank Adaptation of Large Language Models Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks P-Tuning: GPT Understands, Too Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
pefthttps://github.com/huggingface/peft/tree/main
litllamahttps://github.com/Lightning-AI/lit-llama/tree/main
汇总https://zhuanlan.zhihu.com/p/627642632?utm_id=0
eghttps://github.com/zyds/transformers-code/blob/master