【模型量化】神经网络量化基础及代码学习总结
1 量化的介绍
量化是减少神经网络计算时间和能耗的最有效的方法之一。在神经网络量化中,权重和激活张量存储在比训练时通常使用的16-bit或32-bit更低的比特精度。当从32-bit降低到8-bit,存储张量的内存开销减少了4倍,矩阵乘法的计算成本则二次地减少了16倍。
神经网络已被证明对量化具有鲁棒性,这意味着它们可以被量化到较低的位宽,而对网络精度的影响相对较小。然而,神经网络的量化并不是自由的。低位宽量化会给网络带来噪声,从而导致精度的下降。虽然一些网络对这种噪声具有鲁棒性,但其他网络需要额外的工作来利用量化的好处。
量化实际上是将FLOAT32(32位浮点数)的参数量化到更低精度,精度的变化并不是简单的强制类型转换,而是为不同精度数据之间建立一种数据映射关系,最常见的就是定点与浮点之间的映射关系,使得以较小的精度损失代价得到较好的收益。
2 均匀仿射量化
均匀仿射量化也称为非对称量化,定义如下:
s s s:放缩因子(scale factor)/量化步长(step size),是浮点数
z z z:零点(zero-point),是整数,保证真实的0不会有量化误差,对ReLU和zero-padding很重要
b b b:位宽(bit-width),是整数,比如2, 4, 6, 8
s s s和 z z z的作用是将浮点数转化为整数,范围由b来定
1)将真实输入的浮点数 x \mathbb x x转化为无符号整数:
x i n t = c l a m p ( ⌊ x s ⌉ + z ; 0 , 2 b − 1 ) \mathbf{x}_{int} = \mathrm{clamp}(\lfloor\frac{\mathbf{x}}{s}\rceil+z; 0, 2^b-1) xint=clamp(⌊sx⌉+z;0,2b−1)
截断/四舍五入函数的定义:
c l a m p ( x ; a , c ) = { a , x < a , x , a ≤ x ≤ b , b , x > c . \mathrm{clamp}(x; a, c) = \begin{cases} a, x < a, \\ x, a \leq x\leq b,\\ b, x>c. \end{cases} clamp(x;a,c)=⎩ ⎨ ⎧a,x<a,x,a≤x≤b,b,x>c.
2)反量化(de-quantization)近似真实的输入 x \mathbf x x:
x ≈ x ^ = s ( x i n t − z ) \mathbf x\approx \mathbf{\hat x} =s(\mathbf x_{int} -z) x≈x^=s(xint−z)
结合以上1)2)步骤,得到如下量化函数的普遍定义:
x ^ = q ( x ; s , z , b ) = s ( c l a m p ( ⌊ x s ⌉ + z ; 0 , 2 b − 1 ) − z ) \mathbf{\hat x}=q(\mathbf x; s, z, b)=s(\mathrm{clamp}(\lfloor\frac{\mathbf{x}}{s}\rceil+z; 0, 2^b-1)-z) x^=q(x;s,z,b)=s(clamp(⌊sx⌉+z;0,2b−1)−z)
可以发现,量化函数包含了1)中的“浮点转整数”以及“反量化近似浮点”两个过程,这个过程通常被称为 伪量化(fake quantization)操作。
对伪量化的理解:把输入的浮点数据量化到整数,再反量化回 浮点数,以此来模拟量化误差,同时在反向传播的时候,采用Straight-Through-Estimator (STE)把导数回传到前面的层。
由上面的公式,有两个误差概念:
1) 截断误差(clipping error):浮点数 x x x超过量化范围时,会被截断,产生误差
2)舍入误差(rounding error):在做 ⌊ ⋅ ⌉ \lfloor \cdot\rceil ⌊⋅⌉时,会产生四舍五入的误差,误差范围在 [ − 1 2 , 1 2 ] [-\frac{1}{2}, \frac{1}{2}] [−21,21]
为了权衡两种误差,就需要设计合适的s和z,而它们依赖于量化范围和精度。
根据反量化过程,我们设 整数格 上的最大和最小值分别是 Q P = q m a x / s , Q N = q m i n / 2 Q_P=q_{max}/s, Q_N=q_{min}/2 QP=qmax/s,QN=qmin/2,量化值(浮点) 范围为 ( q m i n , q m a x ) (q_{min}, q_{max}) (qmin,qmax),其中 q m i n = s Q P = s ( 0 − z ) = − s z , q m a x = s Q N = s ( 2 b − 1 − z ) q_{min}=sQ_P=s(0-z)=-sz, q_{max}=sQ_N=s(2^b-1-z) qmin=sQP=s(0−z)=−sz,qmax=sQN=s(2b−1−z)。 x \mathbf x x超过这个范围会被截断,产生截断误差,如果希望减小截断误差,可以增大s的值,但是增大s会增大舍入误差,因为舍入误差的范围是 [ − 1 2 s , 1 2 s ] [-\frac{1}{2}s, \frac{1}{2}s] [−21s,21s]。
怎么计算放缩因子 s s s?
s = q m a x − q m i n 2 b − 1 . s=\frac{q_{max}-q_{min}}{2^b-1}. s=2b−1qmax−qmin.
2.1 对称均匀量化
对称均匀量化是上面非对称量化的简化版,限制了放缩因子 z = 0 z=0 z=0,但是偏移量的缺失限制了整数和浮点域之间的映射。
反量化(de-quantization)近似真实的输入 x \mathbf x x:
x ≈ x ^ = s x i n t x\approx \hat x =s\mathbf x_{int} x≈x^=sxint
将真实输入的浮点数 x \mathbb x x转化为无符号整数:
x i n t = c l a m p ( ⌊ x s ⌉ ; 0 , 2 b − 1 ) \mathbf{x}_{int} = \mathrm{clamp}(\lfloor\frac{\mathbf{x}}{s}\rceil; 0, 2^b-1) xint=clamp(⌊sx⌉;0,2b−1)
将真实输入的浮点数 x \mathbb x x转化为有符号整数:
x i n t = c l a m p ( ⌊ x s ⌉ ; − 2 b , 2 b − 1 ) \mathbf{x}_{int} = \mathrm{clamp}(\lfloor\frac{\mathbf{x}}{s}\rceil; -2^b, 2^b-1) xint=clamp(⌊sx⌉;−2b,2b−1)

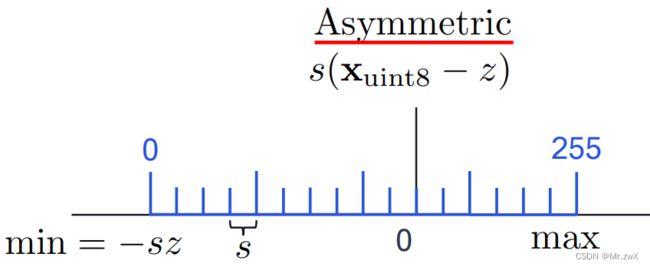
坐标轴上方(蓝色)表示整数量化格,下方(黑色)表示浮点格。可以很清楚地看到,放缩因子 s s s就是量化的步长(step size), s x i n t s\mathbf x_{int} sxint是反量化近似真实浮点数。
2.2 Power-of-two量化(2的幂)
Power-of-two量化是对称量化的特例,放缩因子被限制到2的幂, s = 2 − k s=2^{-k} s=2−k,这对硬件是高效的,因为放缩 s s s相当于简单的比特移位操作(bit-shifting)。
2.3 量化的粒度
1)Per-tensor(张量粒度):神经网络中最常用,硬件实现简单,累加结果都用同样的放缩因子 s w s x s_ws_x swsx
2)Per-channel(通道粒度):更细粒度以提升模型性能,比如对于权重的不同输出通道采用不同的量化
3)Per-group(分组粒度)
3 量化模拟过程/伪量化
量化模拟:为了测试神经网络在量化设备上的运行效果,我们经常在用于训练神经网络的相同通用硬件上模拟量化行为。
我们的目的:使用浮点硬件来近似的定点运算。
优势:与在实际的量化硬件上实验或在使用量化的卷积核上实验相比,这种模拟明显更容易实现
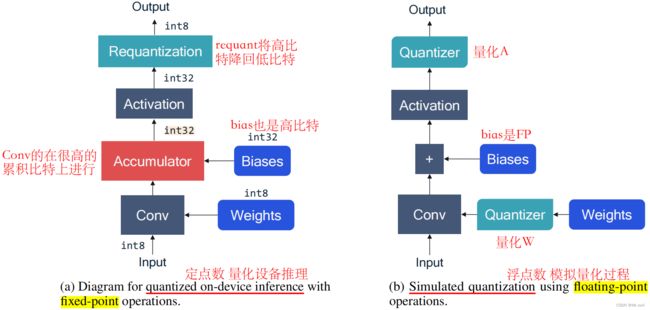
(a)在设备推理过程中,对硬件的所有输入(偏置、权重和输入激活)都是定点格式
(b)然而,当我们使用通用的深度学习框架和通用硬件来模拟量化时,这些量都是以浮点格式表示的。这就是为什么我们在计算图中引入量化器块来诱导量化效应的原因
值得注意的是:
1)每个量化器都由一组量化参数(放缩因子、零点、位宽)来定义
2)量化器的输入和输出都是浮点格式,但输出都在量化网格上
3)每个量化器都由该公式计算: x ^ = q ( x ; s , z , b ) = s ( c l a m p ( ⌊ x s ⌉ + z ; 0 , 2 b − 1 ) − z ) \mathbf{\hat x}=q(\mathbf x; s, z, b)=s(\mathrm{clamp}(\lfloor\frac{\mathbf{x}}{s}\rceil+z; 0, 2^b-1)-z) x^=q(x;s,z,b)=s(clamp(⌊sx⌉+z;0,2b−1)−z),也就是包含了反量化过程
4)模拟量化实际上还是在浮点数上计算,模拟的其实是(截断与舍入)误差
4 基于STE的反向传播优化过程
严峻的优化问题:量化公式中中的round函数的梯度要么为零,要么到处都不定义,这使得基于梯度的训练不可能进行。一种解决方案就是采用straight-through estimator (STE)方法将round函数的梯度近似为1:
∂ ⌊ y ⌉ ∂ y = 1 \frac{\partial \lfloor y\rceil}{\partial y}=1 ∂y∂⌊y⌉=1
于是,量化的梯度就可求了,现对输入 x \mathbf x x进行求导:
∂ x ^ ∂ x = ∂ q ( x ) ∂ x = ∂ c l a m p ( ⌊ x s ⌉ ; Q N , Q P ) s ∂ x = { s ∂ Q N ∂ x = 0 , x < q m i n , s ∂ ⌊ x / s ⌉ ∂ x = s ∂ ⌊ x / s ⌉ ∂ ( x / s ) ∂ ( x / s ) ∂ x = s ⋅ 1 ⋅ 1 s = 1 , q m i n ≤ x ≤ q m a x , s ∂ Q P ∂ x = 0 , x > q m a x . = { 0 , x < q m i n , 1 , q m i n ≤ x ≤ q m a x , 0 , x > q m a x . \frac{\partial\mathbf{\hat x}}{\partial\mathbf x}=\frac{\partial q(\mathbf x)}{\partial\mathbf x}\\~~~~~~=\frac{\partial \mathrm{clamp}(\lfloor\frac{\mathbf x}{s}\rceil; Q_N, Q_P)s}{\partial\mathbf x}\\~~~~~~=\begin{cases} s\frac{\partial Q_N}{\partial \mathbf x}=0, \mathbf x < q_{min}, \\ s\frac{\partial \lfloor \mathbf x/s\rceil}{\partial \mathbf x}=s\frac{\partial \lfloor \mathbf x/s\rceil}{\partial (\mathbf x/s)}\frac{\partial (\mathbf x/s)}{\partial \mathbf x}=s\cdot 1\cdot \frac{1}{s}=1, q_{min} \leq x\leq q_{max},\\ s\frac{\partial Q_P}{\partial \mathbf x}=0, x>q_{max}. \end{cases}\\~~~~~~=\begin{cases} 0, \mathbf x < q_{min}, \\ 1, q_{min} \leq \mathbf x\leq q_{max},\\ 0, \mathbf x>q_{max}. \end{cases} ∂x∂x^=∂x∂q(x) =∂x∂clamp(⌊sx⌉;QN,QP)s =⎩ ⎨ ⎧s∂x∂QN=0,x<qmin,s∂x∂⌊x/s⌉=s∂(x/s)∂⌊x/s⌉∂x∂(x/s)=s⋅1⋅s1=1,qmin≤x≤qmax,s∂x∂QP=0,x>qmax. =⎩ ⎨ ⎧0,x<qmin,1,qmin≤x≤qmax,0,x>qmax.
也就是说,根据STE方法,当输入 x \mathbf x x在量化范围内时,其量化值对真实浮点值的梯度为1,反之为0。
对 s s s求导的数学推导过程如下文中LSQ工作所示。
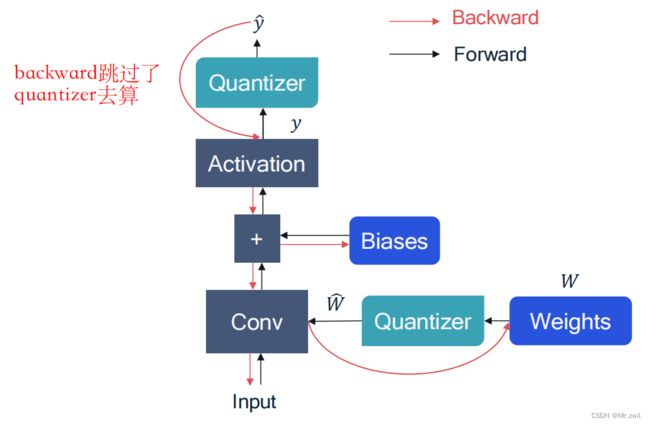
下图展示了基于STE的反向传播过程,计算时有效跳过了量化器。
5 经典量化工作
Learned Step Size Quantization (ICLR 2020)
顾名思义,LSQ这篇文章就是在上述介绍的伪量化中引入可学习/训练的放缩因子 s s s。
设clamp的在 整数格 上的最大和最小值分别是 Q P = q m a x / s , Q N = q m i n / 2 Q_P=q_{max}/s, Q_N=q_{min}/2 QP=qmax/s,QN=qmin/2。
x ^ = s ( c l a m p ( ⌊ x s ⌉ ; Q N , Q P ) ) = { s Q N , x s < Q N , s ⌊ x s ⌉ , Q N ≤ x s ≤ Q P , s Q P , x s > Q P . \hat x=s(\mathrm{clamp}(\lfloor\frac{\mathbf{x}}{s}\rceil; Q_N, Q_P))\\~~~~=\begin{cases} sQ_N, \frac{\mathbf{x}}{s} < Q_N, \\ s\lfloor\frac{\mathbf{x}}{s}\rceil, Q_N \leq \frac{\mathbf{x}}{s}\leq Q_P,\\ sQ_P, \frac{\mathbf{x}}{s}>Q_P. \end{cases} x^=s(clamp(⌊sx⌉;QN,QP)) =⎩ ⎨ ⎧sQN,sx<QN,s⌊sx⌉,QN≤sx≤QP,sQP,sx>QP.
x ^ \mathbf{\hat x} x^对 s s s求导有:
∂ x ^ ∂ s = { Q N , x s < Q N , ⌊ x s ⌉ + s ∂ ⌊ x s ⌉ ∂ s , Q N ≤ x s ≤ Q P , Q P , x s > Q P . \frac{\partial\mathbf{\hat x}}{\partial s}=\begin{cases} Q_N, \frac{\mathbf{x}}{s} < Q_N, \\ \lfloor\frac{\mathbf{x}}{s}\rceil + s\frac{\partial\lfloor\frac{\mathbf{x}}{s}\rceil}{\partial s}, Q_N \leq \frac{\mathbf{x}}{s}\leq Q_P,\\ Q_P, \frac{\mathbf{x}}{s}>Q_P. \end{cases} ∂s∂x^=⎩ ⎨ ⎧QN,sx<QN,⌊sx⌉+s∂s∂⌊sx⌉,QN≤sx≤QP,QP,sx>QP.
其中, Q N , Q P , ⌊ x s ⌉ Q_N, Q_P, \lfloor\frac{\mathbf{x}}{s}\rceil QN,QP,⌊sx⌉都可以直接得到,但是 s ∂ ⌊ x s ⌉ ∂ s s\frac{\partial\lfloor\frac{\mathbf{x}}{s}\rceil}{\partial s} s∂s∂⌊sx⌉就不那么好算了。
根据STE,将round函数梯度近似为一个直通操作:
s ∂ ⌊ x s ⌉ ∂ s = s ∂ x s ∂ s = − s x s 2 = − x s s\frac{\partial\lfloor\frac{\mathbf{x}}{s}\rceil}{\partial s}=s\frac{\partial\frac{\mathbf{x}}{s}}{\partial s}=-s\frac{\mathbf x}{s^2}=-\frac{\mathbf x}{s} s∂s∂⌊sx⌉=s∂s∂sx=−ss2x=−sx
于是,得到LSQ原文中的导数值:
∂ x ^ ∂ s = { Q N , x s < Q N , ⌊ x s ⌉ − x s , Q N ≤ x s ≤ Q P , Q P , x s > Q P . \frac{\partial\mathbf{\hat x}}{\partial s}=\begin{cases} Q_N, \frac{\mathbf{x}}{s} < Q_N, \\ \lfloor\frac{\mathbf{x}}{s}\rceil - \frac{\mathbf x}{s}, Q_N \leq \frac{\mathbf{x}}{s}\leq Q_P,\\ Q_P, \frac{\mathbf{x}}{s}>Q_P. \end{cases} ∂s∂x^=⎩ ⎨ ⎧QN,sx<QN,⌊sx⌉−sx,QN≤sx≤QP,QP,sx>QP.
在LSQ中,每层的权重和激活值都有不同的 s s s,被初始化为 2 ⟨ ∣ x ∣ ⟩ Q P \frac{2\langle| \mathbf x|\rangle}{\sqrt{Q_P}} QP2⟨∣x∣⟩。
计算 s s s的梯度时,还需要兼顾模型权重的梯度,二者差异不能过大,LSQ定义了如下比例:
R = ∇ s L s / ∣ ∣ ∇ w L ∣ ∣ ∣ ∣ w ∣ ∣ → 1 R=\frac{\nabla_sL}{s}/\frac{||\nabla_wL||}{||w||}\rightarrow1 R=s∇sL/∣∣w∣∣∣∣∇wL∣∣→1。
为了保持训练的稳定,LSQ在 s s s的梯度上还乘了一个梯度缩放系数 g g g,对于权重, g = 1 / N W Q P g=1/\sqrt{N_WQ_P} g=1/NWQP,对于激活, g = 1 / N F Q P g=1/\sqrt{N_FQ_P} g=1/NFQP。其中, N W N_W NW是一层中的权重的大小, N F N_F NF是一层中的特征的大小。
代码实现
参考:LSQuantization复现
import torch
import torch.nn.functional as F
import math
from torch.autograd import Variable
class FunLSQ(torch.autograd.Function):
@staticmethod
def forward(ctx, weight, alpha, g, Qn, Qp):
assert alpha > 0, 'alpha = {}'.format(alpha)
ctx.save_for_backward(weight, alpha)
ctx.other = g, Qn, Qp
q_w = (weight / alpha).round().clamp(Qn, Qp) # round+clamp将FP转化为int
w_q = q_w * alpha # 乘scale重量化回FP
return w_q
@staticmethod
def backward(ctx, grad_weight):
weight, alpha = ctx.saved_tensors
g, Qn, Qp = ctx.other
q_w = weight / alpha
indicate_small = (q_w < Qn).float()
indicate_big = (q_w > Qp).float()
indicate_middle = torch.ones(indicate_small.shape).to(indicate_small.device) - indicate_small - indicate_big
grad_alpha = ((indicate_small * Qn + indicate_big * Qp + indicate_middle * (
-q_w + q_w.round())) * grad_weight * g).sum().unsqueeze(dim=0) # 计算s梯度时的判断语句
grad_weight = indicate_middle * grad_weight
return grad_weight, grad_alpha, None, None, None
nbits = 4
Qn = -2 ** (nbits - 1)
Qp = 2 ** (nbits - 1) - 1
g = 1.0 / 2
2 LSQ+: Improving low-bit quantization through learnable offsets and better initialization (CVPR 2020)
LSQ+和LSQ非常相似,就放在一起讲了。LSQ在LSQ+的基础上,引入了可学习的offset,也就是零点 z z z,其定义如下:
x i n t = c l a m p ( ⌊ x − β s ⌉ ; Q N , Q P ) \mathbf x_{int}=\mathrm{clamp}(\lfloor\frac{\mathbf{x-\beta}}{s}\rceil; Q_N, Q_P) xint=clamp(⌊sx−β⌉;QN,QP)
x ^ = s x i n t + β \mathbf{\hat x}=s\mathbf x_{int}+\beta x^=sxint+β
然后按照LSQ的方式对 s , β s,\beta s,β求偏导数进行优化。
3 XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
算是非常早期将二值(1-bit)表示引入神经网络的文章了,本文提出两种近似:
1)Binary-Weight-Network:只有权重是1-bit
对于输入 I \mathbf I I,我们用二值滤波器 B ∈ { + 1 , − 1 } \mathbf B\in \{+1, -1\} B∈{+1,−1}和一个放缩因子 α \alpha α来近似真实浮点滤波器 W \mathbf W W: W ≈ α B \mathbf W\approx \alpha \mathbf B W≈αB,于是卷积的计算可以近似为:
I ∗ W ≈ ( I ⊕ B ) α \mathbf I*\mathbf W\approx (\mathbf I\oplus \mathbf B)\alpha I∗W≈(I⊕B)α
如何优化二值权重?我们的目标是找到 W = α B \mathbf W=\alpha \mathbf B W=αB的最优估计,解决如下优化问题:
J ( B , α ) = ∣ ∣ W − α B ∣ ∣ 2 α ∗ , B ∗ = a r g m i n α , B J ( B , α ) J(\mathbf B, \alpha)=||\mathbf W-\alpha \mathbf B||^2~~~~\alpha^*, \mathbf B^*=\mathrm{argmin_{\alpha, \mathbf B}}J(\mathbf B, \alpha) J(B,α)=∣∣W−αB∣∣2 α∗,B∗=argminα,BJ(B,α)
展开后得到:
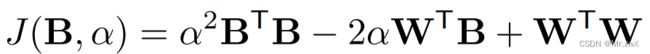
其中, B ⊤ B , W ⊤ W \mathbf B^\top \mathbf B, \mathbf W^\top \mathbf W B⊤B,W⊤W都是常数,因此优化目标集中在第二项 W ⊤ B \mathbf W^\top \mathbf B W⊤B上:

这个优化问题的解可以是使 B = + 1 ( W ≥ 0 ) , B = − 1 ( W < 0 ) \mathbf B=+1(\mathbf W\geq 0), \mathbf B=-1(\mathbf W< 0) B=+1(W≥0),B=−1(W<0),原因是这样可以保持 W ⊤ B \mathbf W^\top \mathbf B W⊤B取最大值+1。因此,可以得到 B ∗ = s i g n ( W ) \mathbf B^*=\mathrm{sign}(\mathbf W) B∗=sign(W)。
然后,求解放缩因子 α \alpha α的最优解,我们用 J J J对 α \alpha α求偏导数:
∂ J ∂ α = 2 α B ⊤ B − 2 W ⊤ B \frac{\partial J}{\partial \alpha}=2\alpha\mathbf B^\top\mathbf B-2\mathbf W^\top \mathbf B ∂α∂J=2αB⊤B−2W⊤B
当偏导数等于0时,可求解:
α ∗ = W ⊤ B B ⊤ B = W ⊤ B n \alpha^*=\frac{\mathbf W^\top \mathbf B}{\mathbf B^\top \mathbf B}=\frac{\mathbf W^\top \mathbf B}{n} α∗=B⊤BW⊤B=nW⊤B
其中,令 n = B ⊤ B n=\mathbf B^\top \mathbf B n=B⊤B,此时的 B \mathbf B B代入 B ∗ \mathbf B^* B∗,于是:
α ∗ = W ⊤ B n = W ⊤ s i g n ( W ) n = ∑ ∣ W ∣ n = 1 n ∣ ∣ W ∣ ∣ 1 \alpha^*=\frac{\mathbf W^\top \mathbf B}{n}=\frac{\mathbf W^\top \mathrm{sign}(\mathbf W)}{n}=\frac{\sum |\mathbf W|}{n}=\frac{1}{n}||\mathbf W||_1 α∗=nW⊤B=nW⊤sign(W)=n∑∣W∣=n1∣∣W∣∣1
其中, ∣ ∣ ⋅ ∣ ∣ 1 ||\cdot||_1 ∣∣⋅∣∣1表示 ℓ 1 \ell_1 ℓ1-norm,即对矩阵中的所有元素的绝对值求和。
总结
二值权重/滤波器的最优估计是权重的符号函数值,放缩因子的最优估计是权重的绝对值平均值。

训练过程
需要注意的是,反向传播计算梯度用的近似的权重 W ~ \tilde W W~,而真正被更新的权重应该是真实的高精度权重 W W W。

2)XNOR-Networks:权重和激活值都是1-bit,乘法全部简化为异或计算
二值dot product计算
X ⊤ W ≈ β H ⊤ α B \mathbf X^\top W\approx \beta \mathbf H^\top \alpha \mathbf B X⊤W≈βH⊤αB,其中, H , B ∈ { − 1 , + 1 } , β , α ∈ R + \mathbf H, \mathbf B\in \{-1, +1\}, \beta, \alpha\in\mathbb R^+ H,B∈{−1,+1},β,α∈R+,优化目标如下:

令 Y = X W , C ∈ { − 1 , + 1 } , C = H B , γ = α β \mathbf Y=\mathbf X \mathbf W, \mathbf C\in \{-1, +1\}, \mathbf C=\mathbf H \mathbf B, \gamma=\alpha\beta Y=XW,C∈{−1,+1},C=HB,γ=αβ,于是优化目标简化为:
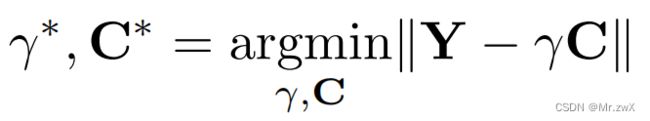
根据Binary-Weight-Network,通过符号函数可以求解最优的二值激活值和权重:
![]()
同理,根据,通过 ℓ 1 \ell_1 ℓ1-norm可以求解最优的放缩因子:
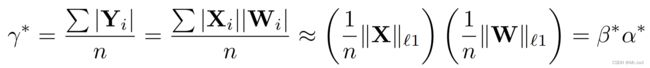
二值卷积计算
对于输入 I \mathbf I I,首先计算 A = ∑ ∣ I : , : , i ∣ c \mathbf A=\frac{\sum |\mathbf I_{:, :, i}|}{c} A=c∑∣I:,:,i∣,其中 c c c是输入通道数,这个过程计算了跨通道的输入 I \mathbf I I中元素的绝对值的平均值。然后将 I \mathbf I I和一个2D滤波器 k ∈ R w × h \mathbf k\in \mathbb R^{w\times h} k∈Rw×h做卷积, K = A ∗ k , k i j = 1 w h \mathbf K=\mathbf A * \mathbf k, \mathbf k_{ij}=\frac{1}{wh} K=A∗k,kij=wh1。 K \mathbf K K中包含了 I \mathbf I I中左右子张量的放缩因子 β \beta β。
于是,卷积的近似计算如下:
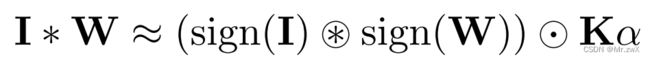
其中, ⊛ \circledast ⊛表示XNOR+bitcount操作。

代码参考:XNOR-Net-PyTorch
符号函数直接通过sign函数实现:
input = input.sign()
参考资料
- 量化训练之可微量化参数—LSQ
- A White Paper on Neural Network Quantization