验证码自动识别并模拟登陆
本文介绍使用pytesseract进行验证码识别,并使用request和xpath解析模拟登陆。
如这个网站,当我们爬取关于这个网站个人信息数据时,需要模拟登陆,而并且还有验证码的反爬虫机制,这时候我们可以使用验证码识别,再进行模拟登陆。
以下是一些常用的自动识别验证码的方法:
- Tesseract OCR: Tesseract是一个开源的OCR引擎,由Google维护。它可以识别多种语言的文本,包括英文、中文等。你可以使用Python的pytesseract库来与Tesseract进行集成。
- OpenCV: OpenCV是一个计算机视觉库,它可以用于图像处理和识别。你可以使用OpenCV来处理验证码图像,包括预处理和文本提取。
- 第三方OCR API: 有一些云服务提供商,如Google Cloud Vision、Microsoft Azure Computer Vision等,提供了OCR服务。你可以通过调用这些API来自动识别验证码。
- 机器学习: 你可以使用机器学习算法来训练一个自定义的OCR模型,以识别特定类型的验证码。这需要大量的训练数据和专业知识。
- 深度学习: 深度学习模型,如卷积神经网络(CNN)和循环神经网络(RNN),在验证码识别中也表现出色。你可以使用深度学习框架如TensorFlow或PyTorch来构建自定义的验证码识别模型。
- 图像处理技术: 对于一些简单的验证码,可以使用图像处理技术来分割字符、去除噪音和增强图像,以便更容易地进行手动或自动识别。
本文选自第第一种,使用Python的第三方库Tesseract和Pillow进行验证码识别。其中,Pillow是Python的一个图像处理库,可以用于图像的压缩、旋转、缩放等。
步骤总结:
- 安装Tesseract和Pillow
- 安装Tesseract-OCR
- 验证码识别
- 模拟登陆
- 运行测试
一、安装Tesseract和Pillow
pip install pytesseract
pip install Pillow但是,使用pytesseract进行验证码识别时,会报以下错误:
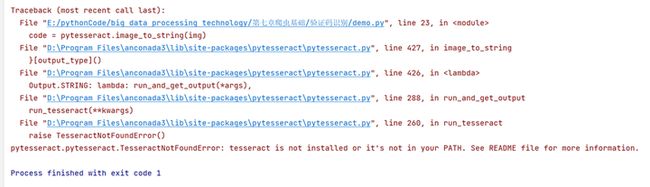
pytesseract.pytesseract.TesseractNotFoundEFror: tesseract is not installed or it's not in your PATH.See READNME file for more infonation.
原因:在安装pytesseract库后还需要安装Tesseract-OCR才能正常使用,但是使用pip install Tesseract-OCR 会报错,这时需要手动安装Tesseract-OCR,
二、安装Tesseract-OCR
下载链接:https://digi.bib.uni-mannheim.de/tesseract/ ,自行选择版本。双击exe程序,默认安装好。
要记住自己的安装路径,
接着,将安装的路径添加到环境变量中
将安装路径的根目录添加到path路径中,比如我安装Tesseract-OCR 软件的目录为:C:\Program Files\Tesseract-OCR
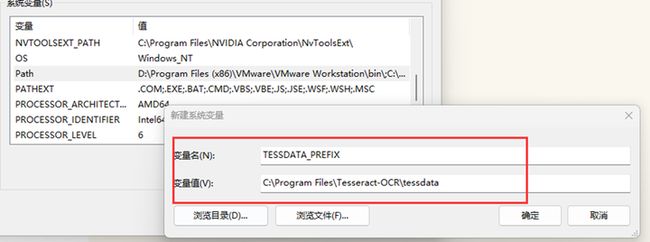
那么path变量的值就新增一个C:\Program Files\Tesseract-OCR,如下图:
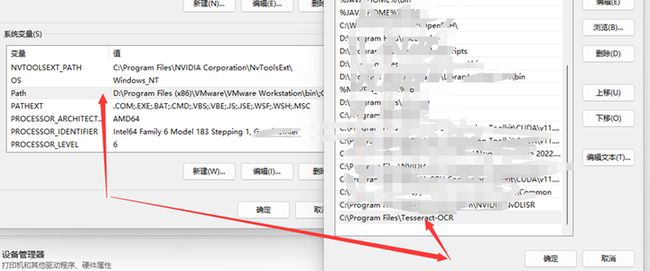
并且,新增一个新的变量TESSDATA_PREFIX 其值为:C:\Program Files\Tesseract-OCR\tessdata
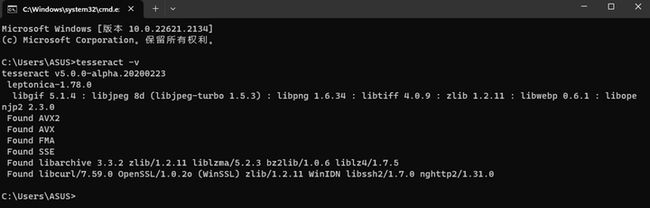
然后打开终端cmd,执行以下命令测试是否安装以及添加环境变量是否成功:
tesseract -V
如下图表示成功:
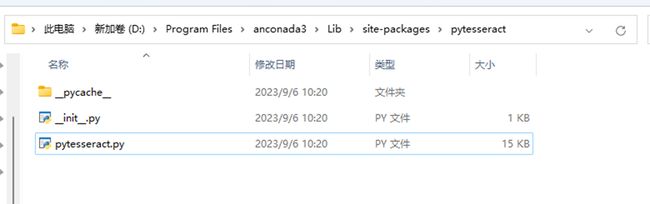
最后一步:前面执行pip安装pytesseract包后,会在python环境下有对应的数据包,比如我的python环境是使用anconada3集成的,那么找到对应的依赖包路径:如我的路径为:
D:\Program Files\anconada3\Lib\site-packages\pytesseract
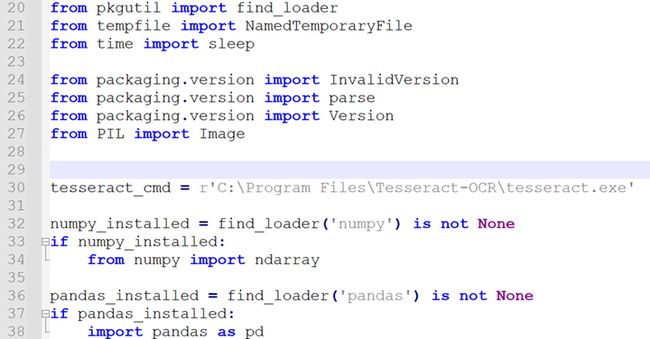
如下图:找到该路径后,打开pytesseract.py文件(使用编辑器,不要双击运行),
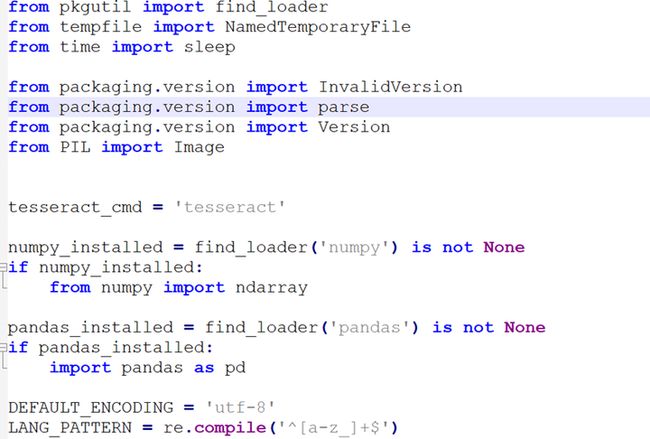
定位到30行左右,将tesseract_cmd = ' tesseract '改成
tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
如下图:
三、验证码识别
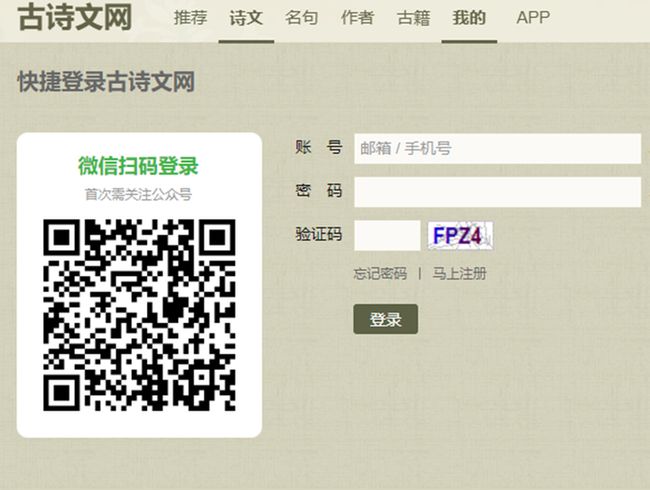
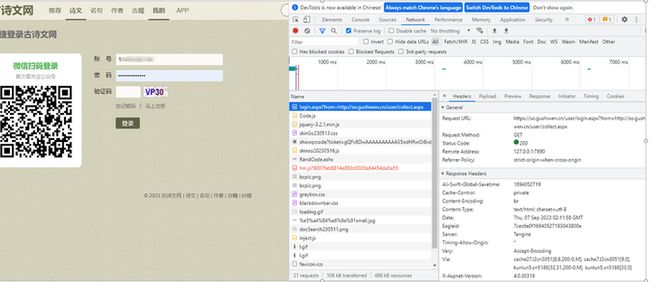
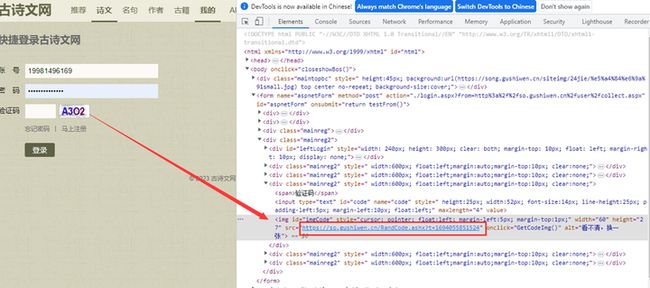
•打开网站,进入登录网页 https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx ,如图所示。
•打开Chrome开发者工具后打开网络面板,勾选Preserve log(保持日志)。按“F5”键刷新网页显示各项资源,如图所示。
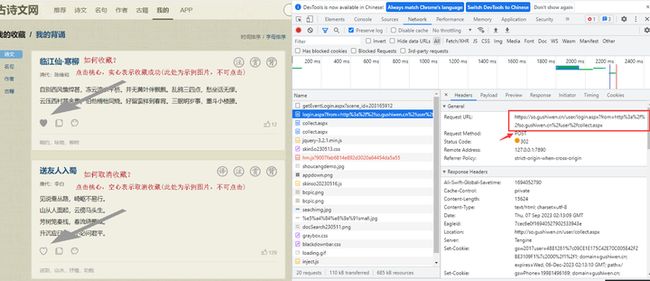
•在登录网页输入账号、秘密、验证码,单击“登录”按钮,提交表单数据,此时Chrome开发者工具会加载新的资源。观察Chrome开发者工具左侧的资源,找到“login.aspx”资源并单击,观察右侧的Headers标签下的General信息,如图 所示,发现Request Method信息为POST,即请求方法为POST,可以判断Request URL信息即为提交入口。
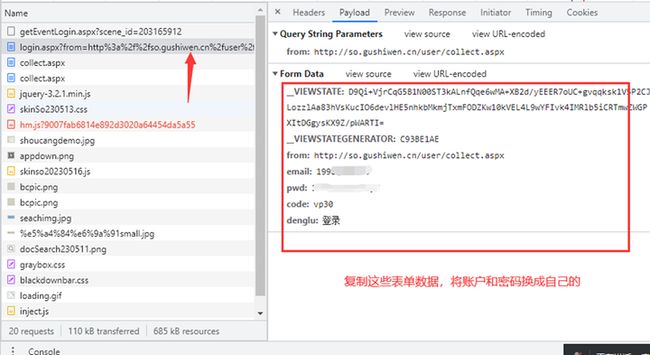
使用Chrome开发者工具获取到的提交入口,观察Headers标签,Form Data信息为服务器端接收到的表单数据,如图 所示。其中,email表示账号;pwd表示密码;code表示验证码;from表示跳转网址。其余几项自动生成,在登录网页时无需输入,复制该表单数据,作为后续爬虫发送post请求的data数据。
•观察Chrome开发者工具的资源,找到验证码对应的网页标签位置,可以发现,img的src属性里面的网址就是验证码下载的网址,可以通过request库进行获取并xpath进行解析,得到验证码的网址。
•需要注意的是有的网站的验证码链接是动态生成的,并且验证码的验证可能依赖于服务器生成的动态验证码,那么简单地下载验证码图片并手动输入可能无法正常工作。这时就需要使用session对象进行对话。
验证码识别的代码如下:
from PIL import Image, ImageFilter
import pytesseract
def VerifiCode(image_path):
img = Image.open(image_path)
# 将图片变成灰色
img_gray = img.convert('L')
# 转成黑白图片
img_black_white = img_gray.point(lambda x: 255 if x > 60 else 0)#自行更改阈值
img_qucao = img_black_white.filter(ImageFilter.SMOOTH_MORE)
img_RGB = img_qucao.convert('RGB')
captcha_text = pytesseract.image_to_string(img_RGB, config='--psm 6')
# print('识别结果:', captcha_text)
captcha_text = captcha_text.strip()
# 输出识别结果
# print('识别结果:', captcha_text)
return captcha_text注意:这个验证码识别可能有识别失败的情况,如果失败可以多尝试几次,或者手动识别。
四、模拟登陆
模拟登陆的思路是,创建一个seesion回话,先对登陆页面进行get访问,通过浏览器调试,写出解析验证码的xpath表达式,并下载验证码,将验证码图片输入到上述的验证识别的方法VerifiCode()中,再将验证码识别结果封装到Cookie表单数据中,再次对登陆发送请求,即可以登陆成功。
if __name__=='__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)',
}
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
# 创建一个会话对象,以便在多个请求之间共享cookies
session = requests.Session()
page_text = session.get(url=url,headers=headers).text
# 解析验证码图片img史src属性值
tree = etree.HTML(page_text)
img_src=tree.xpath( '//*[@id="imgCode"]/@src')[0]
# print(img_src)
code_img_src = 'https://so.gushiwen.org'+img_src#
# print(code_img_src)
img_data = session.get(url=code_img_src,headers=headers).content#图片是二进制的所以使用content
# 资验证码图片保存到了本地
img_path='./验证码/code.jpg'
with open( img_path,'wb' ) as fp:
fp.write( img_data)
img = Image.open(img_path)
resultVerifiCode=VerifiCode(img_path)#调用工具方法进行验证码自动识别
plt.figure(figsize=(10, 5))
plt.subplot(111)
plt.title('Original Image')
plt.imshow(img)
print('识别结果:', resultVerifiCode)
plt.show()
#登陆时的表单数据
data={
" __VIEWSTATE": "HGoCyqcXPB5M2yaO3lGPOCpWN6KZy4/ZxY6qNiMUsXK5oDoacCt67HVF+5+Og9Vxf3wuJn2XlihWg2khl5akVJRl/R7R/xOwSZ8VpBEUIRyEqB55bk+vxY2K0xzNxVyjEVv0Zn5rDPHQTRvQyrvCL5V4KNc=",
"__VIEWSTATEGENERATOR": "C93BE1AE",
"from":"http://so.gushiwen.cn/user/collect.aspx",
"email":"****",#换成你的账户
"pwd": "***",#换成你的密码
"code": resultVerifiCode,
"denglu": "登录",
}
login_url="https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx"
login_response = session.post(url=login_url, headers=headers,data=data)
print(login_response.status_code)
if login_response.status_code==200:
login_page_text=login_response.text
# 检查是否成功登录
if "我的收藏_古诗文网" in login_page_text:
print("登录成功")
with open('../爬取结果/验证码识别登陆/login_page_text.html', 'w', encoding='utf-8') as fp:
fp.write(login_page_text)
print("保存成功")
else:
print("登录失败")
# 关闭会话
session.close()需要注意的是,需要提前注册一个账号,并且爬虫发送请求时要使用session发起对话,因为这个网站的验证码是动态发送的,访问是需要携带Cookie信息的
五、运行测试
这是一个识别失败的测试:
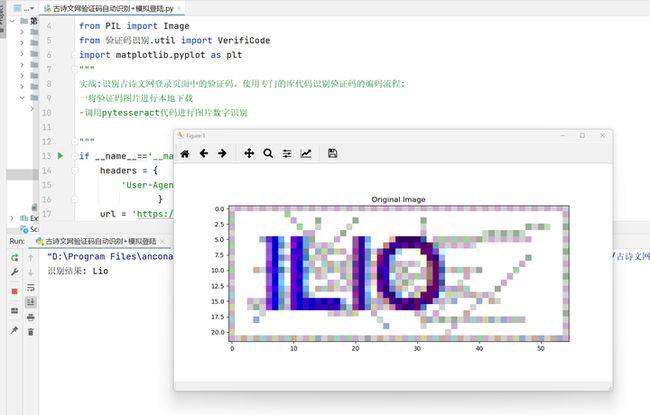
可以提前终止程序不用再次发起请求。
这是一个识别成功并成功登陆的测试:
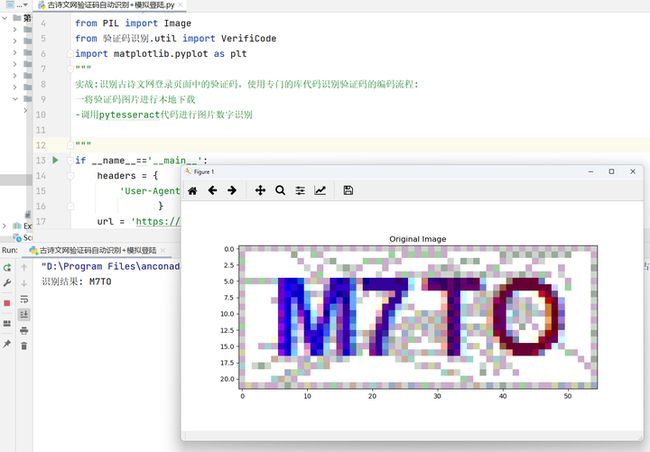
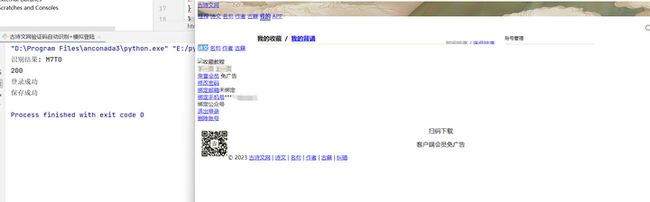
总结,本文是通过对一个网站的验证码反爬机制使用python的第三方库pytesseract进行识别,当然分享的代码是不适应其他的网站登陆的,毕竟有的网站的验证码是其他的情况(如,中文识别、滑块滑动等),这时就需要其他的技术了,如:使用图像处理的技术、第三方平台、Selenium自动登陆等。