风速预测(五)基于Pytorch的EMD-CNN-LSTM模型
目录
前言
1 风速数据EMD分解与可视化
1.1 导入数据
1.2 EMD分解
2 数据集制作与预处理
2.1 先划分数据集,按照8:2划分训练集和测试集
2.2 设置滑动窗口大小为96,制作数据集
3 基于Pytorch的EMD-CNN-LSTM模型预测
3.1 数据加载,训练数据、测试数据分组,数据分batch
3.2 定义EMD-CNN-LSTM预测模型
3.3 定义模型参数
3.4 模型训练
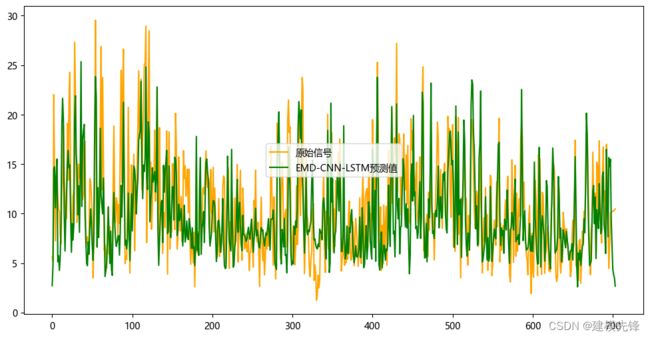
3.5 结果可视化

往期精彩内容:
风速预测(一)数据集介绍和预处理-CSDN博客
风速预测(二)基于Pytorch的EMD-LSTM模型-CSDN博客
风速预测(三)EMD-LSTM-Attention模型-CSDN博客
风速预测(四)基于Pytorch的EMD-Transformer模型-CSDN博客
前言
LSTF(Long Sequence Time-Series Forecasting)问题是指在时间序列预测中需要处理长序列的情况。在实际应用中,时间序列可能会包含非常大量的数据点,在这种情况下,传统的时间序列预测模型可能会遇到一些挑战,因为处理长序列时会出现一些问题,例如:
-
长期依赖性: 随着时间序列数据的增长,模型需要能够捕捉长期的依赖关系和趋势。
-
计算复杂性: 针对长序列进行训练和预测通常需要更多的计算资源和时间。
-
内存消耗: 长序列通常需要大量的内存来存储数据和模型参数,这可能会导致内存耗尽或者性能下降的问题。
在处理LSTF问题时,选择合适的窗口大小(window size)是非常关键的。选择合适的窗口大小可以帮助模型更好地捕捉时间序列中的模式和特征,为了提取序列中更长的依赖建模,本文把窗口大小提升到96,运用EMD-CNN-LSTM模型来充分提取序列中的特征信息。
本文基于前期介绍的风速数据(文末附数据集),先经过经验模态EMD分解,然后通过数据预处理,制作和加载数据集与标签,最后通过Pytorch实现EMD-CNN-LSTM模型对风速数据的预测。风速数据集的详细介绍可以参考下文:
风速预测(一)数据集介绍和预处理
1 风速数据EMD分解与可视化
1.1 导入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
# 读取已处理的 CSV 文件
df = pd.read_csv('wind_speed.csv' )
# 取风速数据
winddata = df['Wind Speed (km/h)'].tolist()
winddata = np.array(winddata) # 转换为numpy
# 可视化
plt.figure(figsize=(15,5), dpi=100)
plt.grid(True)
plt.plot(winddata, color='green')
plt.show()
1.2 EMD分解
from PyEMD import EMD
# 创建 EMD 对象
emd = EMD()
# 对信号进行经验模态分解
IMFs = emd(winddata)
# 可视化
plt.figure(figsize=(20,15))
plt.subplot(len(IMFs)+1, 1, 1)
plt.plot(winddata, 'r')
plt.title("原始信号")
for num, imf in enumerate(IMFs):
plt.subplot(len(IMFs)+1, 1, num+2)
plt.plot(imf)
plt.title("IMF "+str(num+1), fontsize
=
10
)
# 增加第一排图和第二排图之间的垂直间距
plt.subplots_adjust(hspace=0.8, wspace=0.2)
plt.show()
2 数据集制作与预处理
2.1 先划分数据集,按照8:2划分训练集和测试集

2.2 设置滑动窗口大小为96,制作数据集

3 基于Pytorch的EMD-CNN-LSTM模型预测
3.1 数据加载,训练数据、测试数据分组,数据分batch
# 加载数据
import torch
from joblib import dump, load
import torch.utils.data as Data
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 参数与配置
torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载数据集
def dataloader(batch_size, workers=2):
# 训练集
train_set = load('train_set')
train_label = load('train_label')
# 测试集
test_set = load('test_set')
test_label = load('test_label')
# 加载数据
train_loader = Data.DataLoader(dataset=Data.TensorDataset(train_set, train_label),
batch_size=batch_size, num_workers=workers, drop_last=True)
test_loader = Data.DataLoader(dataset=Data.TensorDataset(test_set, test_label),
batch_size=batch_size, num_workers=workers, drop_last=True)
return train_loader, test_loader
batch_size = 64
# 加载数据
train_loader, test_loader = dataloader(batch_size)3.2 定义EMD-CNN-LSTM预测模型

注意:输入风速数据形状为 [64, 10, 96], batch_size=64, 维度10维代表10个分量,96代表序列长度(滑动窗口取值)。
3.3 定义模型参数
# 定义模型参数
batch_size = 64
input_len = 96 # 输入序列长度为96 (窗口值)
input_dim = 10 # 输入维度为10个分量
conv_archs = ((1, 32), (1, 64)) # CNN 层卷积池化结构 类似VGG
hidden_layer_sizes = [64, 128] # LSTM 层 结构
output_size = 1 # 单步输出
model = EMDCNNLSTMModel(batch_size, input_len, input_dim, conv_archs, hidden_layer_sizes, output_size=1)
# 定义损失函数和优化函数
model = model.to(device)
loss_function = nn.MSELoss() # loss
learn_rate = 0.003
optimizer = torch.optim.Adam(model.parameters(), learn_rate) # 优化器3.4 模型训练

训练结果

采用两个评价指标:MSE 与 MAE 对模型训练进行评价,100个epoch,MSE 为0.00412,MAE 为 0.000241,EMD-CNN-LSTM预测效果良好,性能提升明显,适当调整模型参数,还可以进一步提高模型预测表现。通过CNN模型来处理输入的长窗口时间序列数据,能够有效地捕获局部模式和特征,将CNN模型的输出作为LSTM模型的输入,LSTM模型能够更好地捕捉时间序列数据中的长期依赖关系。EMD-CNN-LSTM模型效果明显,可见其性能的优越性。
注意调整参数:
-
可以适当调整CNN中卷积池化的层数和维度,微调学习率;
-
调整LSTM层数和维度,增加更多的 epoch (注意防止过拟合)
-
可以改变滑动窗口长度(设置合适的窗口长度)
3.5 结果可视化