hive调优扩充
1.数据采样
采样函数:
tablesample(bucket x out of y [on column])
使用位置: 查询的时候,紧紧跟在表名的后面, 如果表名有别名, 必须放置别名的前面
普通表:
说明:
x: 从第几个桶进行采样, x 不能大于 y
y: 临时分几个桶
column: 分桶的字段, 可以省略
分桶表:
说明:
x: 从第几个桶开始进行采样, x 不能大于 y
y: 抽样比例 y 必须是桶表的分桶数量的倍数或者因子
column: 分桶的字段, 可以省略
分桶表抽样案例:
1) 假设 A表有10个桶, 请分析, 下面的采样函数, 会将那些桶抽取出来呢?
tablesample(bucket 2 out of 5 on xxx)
会抽取出几个桶数据呢? 总桶数 / 抽样比例 = 分桶数量 2个桶
抽取那几个桶呢? (x + y)
2, 7
-
假设 A 表有20个桶, 请分析, 下面的抽样函数, 会将那些桶抽取出来呢?
tablesample(bucket 4 out of 4 on xxx)会抽取出几个桶数据呢? 总桶数 / 抽样比例 = 分桶数量 5个桶
抽取那几个桶呢?
4 , 8,12,16,20tablesample(bucket 8 out of 40 on xxx)
会抽取出几个桶数据呢? 总桶数 / 抽样比例 = 分桶数量 二分之一个桶
抽取那几个桶呢?
8号桶二分之一
大多数情况下, 都是因子, 取某几个桶的操作
2.Join优化
Map Join
Map Join: 每一个mapTask在读取数据的时候, 每读取一条数据, 就会和内存中班级表数据进行匹配, 如果能匹配的上, 将匹配上数据合并在一起, 输出即可
好处: 将原有reduce join 问题全部都可以解决
弊端:
1- 比较消耗内存
2- 要求整个 Join 中, 必须的都有一个小表, 否则无法放入到内存中
仅适用于: 小表 join 大表 | 大表 join 小表
在老版本(1.x以下)中, 需要将小表放置在前面, 大表放置在后面, 在新版本中, 无所谓
建议, 如果明确知道那些表示小表, 可以优先将这些表, 放置在最前面
如何使用呢?
-- map join
set hive.auto.convert.join=true; -- 开启 map join的支持 默认值为True
set hive.mapjoin.smalltable.filesize= 25000000; --设置 小表的文件大小(23.84m)
set hive.auto.convert.join.noconditionaltask.size=20971520; -- 设置 join任务数据量
如果不满足条件, HIVE会自动使用 reduce join 操作
Bucket Map Join
适用场景: 中型表 和 大表 join:
- 方案一: 如果中型表能对数据进行提前过滤, 尽量提前过滤, 过滤后, 有可能满足了Map Join 条件 (并不一定可用)
- 方案二: Bucket Map Join
-- bucket map join
set hive.optimize.bucketmapjoin; -- 默认false
/*
1- Join两个表必须是分桶表
2- 开启 Bucket Map Join 支持: set hive.optimize.bucketmapjoin = true;
3- 一个表的分桶数量是另一个表的分桶数量的整倍数
4- 分桶列 必须 是 join的ON条件的列
5- 必须建立在Map Join场景中(中型表是小表的3倍, 此时分至少3个桶)
*/
SMB Join
- 适用场景: 大表 和 大表 join
- 解决方案: SMB Join ( sort merge bucket map join)
- -- 使用条件:
-- 1- 两个表必须都是分桶表
-- 2- 开启 SMB Join 支持:
set hive.auto.convert.sortmerge.join; -- 默认false
set hive.optimize.bucketmapjoin.sortedmerge ;-- 默认false
set hive.auto.convert.sortmerge.join.noconditionaltask;-- Hive 0.13.0默认开启
-- 3- 两个表的分桶的数量是一致的
-- 4- 分桶列 必须是 join的 on条件的列, 同时必须保证按照分桶列进行排序操作
-- 开启强制排序
set hive.enforce.sorting; -- hive2.x移除 默认true
-- 在建分桶表使用: 必须使用sorted by()
-- 5- 应用在Bucket Map Join 场景中
-- 开启 bucket map join
set hive.optimize.bucketmapjoin ; --默认false
3.hive索引
hive原始索引
hive的原始索引可以针对某个列, 或者某几列构建索引信息, 构建后提升查询执行列的查询效率
存在弊端:
hive原始索引不会自动更新,每次表中数据发生变化后, 都是需要手动重建索引操作, 比较耗费时间和资源, 整体提升性能一般
所以在HIVE3.x版本后, 已经直接将这种索引废弃掉了, 无法使用, 而且官方描述在hive1.x 和 hive2.x版本中, 也不建议优先使用原始索引
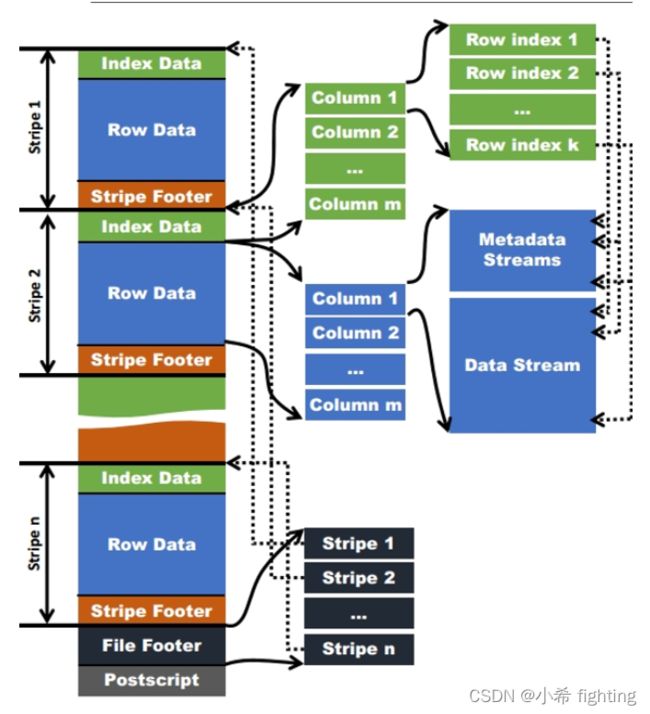
ORC相关索引
ORC的全称是(Optimized Record Columnar),使用ORC文件格式可以提高hive读、写和处理数据的能力。
在ORC格式的hive表中,记录首先会被横向的切分为多个stripes,然后在每一个stripe内数据以列为单位进行存储,所有列的内容都保存在同一个文件中。每个stripe的默认大小为256MB,相对于之前RCFile每个4MB而言,更大的stripe使ORC的数据读取更加高效。
ORC在RCFile的基础上进行了一定的改进,所以与RCFile相比,具有以下一些优势:
1、ORC中的特定的序列化与反序列化操作可以使ORC file writer根据数据类型进行写出。
2、提供了多种RCFile中没有的indexes,这些indexes可以使ORC的reader很快的读到需要的数据,并且跳过无用数据,这使得ORC文件中的数据可以很快的得到访问。
3、由于ORC file writer可以根据数据类型进行写出,所以ORC可以支持复杂的数据结构(比如Map等)。
4、除了上面三个理论上就具有的优势之外,ORC的具体实现上还有一些其他的优势,比如ORC的stripe默认大小更大,为ORC writer提供了一个memory manager来管理内存使用情况。
Row Group Index 索引(行组索引/最小最大索引)
条件:
1) 要求表的存储类型为ORC存储格式
2) 在创建表的时候, 必须开启 row group index 索引支持
‘orc.create.index’=‘true’
3) 在插入数据的时候, 必须保证需求进行索引列, 按序插入数据
适用于: 数值类型的, 并且对数值类型进行 > < >= <=操作
思路:
插入数据到ORC表后, 会自动进行划分为多个script片段, 每个片段内部, 会保存着每个字段的最小, 最大值, 这样, 当执行查询 > < = 的条件筛选操作的时候, 根据最小最大值锁定相关的script片段, 从而减少数据扫描量, 提升效率
操作:
CREATE TABLE lxw1234_orc2 (字段列表 …) stored AS ORC
TBLPROPERTIES (
‘orc.compress’=‘SNAPPY’,
– 开启行组索引
‘orc.create.index’=‘true’
)
插入数据的时候, 需要保证数据有序的
insert overwrite table lxw1234_orc2
SELECT id, pcid FROM lxw1234_text
-- 插入的数据保持排序(可以使用全局排序, 也可以使用局部排序, 只需要保证一定有序即可, 建议使用局部排序 插入数据效率高一些, 因为全局排序只有一个reduce)
DISTRIBUTE BY id sort BY id;
使用:
set hive.optimize.index.filter; – 默认true
SELECT COUNT(1) FROM lxw1234_orc1 WHERE id >= 1382 AND id <= 1399;
Bloom Fliter index 索引(布隆过滤索引/布隆过滤器)
条件:
1) 要求表的存储类型为 ORC存储方案
2) 在建表的时候, 必须设置为那些列构建布隆索引
3) 仅能适合于等值过滤查询操作
思路:
在开启布隆过滤索引后, 可以针对某个列, 或者某几列来建立索引, 构建索引后, 会将这一列的数据的值存储在对应script片段的索引信息中, 这样当进行 等值查询的时候, 首先会到每一个script片段的索引中, 判断是否有这个值, 如果没有, 直接跳过script, 从而减少数据扫描量, 提升效率
操作:
CREATE TABLE lxw1234_orc2 (字段列表…)
stored AS ORC
TBLPROPERTIES (
‘orc.compress’=‘SNAPPY’,
– 开启 行组索引 (可选的, 支持全部都打开, 也可以仅开启一个)
‘orc.create.index’=‘true’,
– pcid字段开启BloomFilter索引
‘orc.bloom.filter.columns’=‘pcid,字段2,字段3…’
)
插入数据: 没有要求, 当然如果开启行组索引, 可以将需要使用行组索引的字段, 进行有序插入即可
使用:
set hive.optimize.index.filter; – 默认true
SELECT COUNT(1) FROM lxw1234_orc1
WHERE id >= 0 AND id <= 1000 – 底层用了行组索引
AND pcid IN (‘001’,‘002’); – 底层用了布隆过滤索引
1- 对于行组索引: 我们建议只要数据存储格式为ORC, 建议将这种索引全部打开, 至于导入数据的时候, 如果能保证有序, 那最好, 如果保证不了, 也无所谓, 大不了这个索引的效率不是特别好
2- 对于布隆过滤索引: 建议将后续会大量的用于等值连接的操作字段, 建立成布隆索引, 比如说: JOIN的字段 经常在where后面出现的等值连接字段
4.解决数据倾斜问题
Join数据倾斜
方案一:
Map Join (默认开启),
Bucket Map Join(默认关闭,条件是分桶表,且数量是倍数关系) ,
SMB Join(条件是分桶表,且桶数量必须一致,插入数据的时候要排序)
注意:
通过 Map Join,Bucket Map Join,SMB Join 来解决数据倾斜, 但是 这种操作是存在使用条件的, 如果无法满足这些条件, 无法使用 这种处理方案
方案二:
思路: 将那些产生倾斜的key和对应v2的数据, 从当前这个MR中移出去, 单独找一个MR来处理即可, 处理后, 和之前的MR进行汇总结果即可
关键问题: 如何找到那些存在倾斜的key呢? 特点: 这个key数据有很多
1.运行期处理方案:
思路: 在执行MR的时候, 会动态统计每一个 k2的值出现重复的次数, 当这个重复的次数达到一定的阈值后, 认为当前这个k2的数据存在数据倾斜, 自动将其剔除, 交由给一个单独的MR来处理即可,两个MR处理完成后, 将结果基于union all 合并在一起即可
实操:
set hive.optimize.skewjoin=true; -- 开启运行期处理倾斜参数默认false
set hive.skewjoin.key=100000; -- 阈值, 此参数在实际生产环境中, 需要调整在一个合理的值(否则极易导致大量的key都是倾斜的),默认100000
判断依据: 查看 join的 字段 对应重复的数量有多少个, 然后选择一个合理值
比如判断: id为 1 大概有 100w id为 2 88w id 为 3 大概有 500w 设置阈值为 大于500w次数据
或者: 总数量大量1000w, 然后共有 1000个班级, 平均下来每个班级数量大概在 1w条, 设置阈值: 大于 3w条 ~5w条范围 (超过3~5倍才认为倾斜)
适用于: 并不清楚那个key容易产生倾斜, 此时交由系统来动态检测
2.编译期处理方案:
思路1: 在创建这个表的时候, 我们就可以预知到后续插入到这个表中数据, 那些key的值会产生倾斜, 在建表的时候, 将其提前配置设置好即可, 在后续运行的时候, 程序会自动将设置的key的数据单独找一个MR来进行处理即可, 处理完成后, 再和原有结果进行union all 合并操作
实操1:
set hive.optimize.skewjoin.compiletime=true; -- 开启编译期处理倾斜参数
CREATE TABLE list_bucket_single (key STRING, value STRING)
-- 倾斜的字段和需要拆分的key值
SKEWED BY (key) ON (1,5,6)
-- 为倾斜值创建子目录单独存放
[STORED AS DIRECTORIES];
思路2: 大量的key可以拼接rand()
实操2: 举例: 如果大量相同的男,可以拼接随机数: concat('男',rand())
适用于: 提前知道那些key存在倾斜
在实际生产环境中, 应该使用那种方式呢? 两种方式都会使用的
一般来说, 会将两个都开启, 编译期的明确在编译期将其设置好, 编译期不清楚, 通过运行期动态捕获即可
底层union all 优化方案
说明: 不管是运行期 还是编译期的join倾斜解决, 最终都会运行多个MR, 将多个MR结果通过union all 进行汇总, union all也是需要单独一个MR来处理
解决方案:
让每一个MR在运行完成后, 直接将结果输出到目的地即可, 默认 是各个MR将结果输出临时目录, 通过 union all 合并到最终目的地
开启此参数即可:
set hive.optimize.union.remove=true;
Group by数据倾斜
方案一:
MR的 combiner(规约, 提前聚合) 减少数据达到reduce数量, 从而减轻倾斜问题
方案二:
负载均衡的解决方案(需要运行两个MR来处理) (大combiner方案)
默认关闭,如果需要,手动开启
set hive.groupby.skewindata=true;
负载均衡解决:
第一个MR执行完成了, 随机打乱分配,假设每个reduce都接收到四条数据, 自然也就不存在数据倾斜的问题了
第二个MR进行处理: 严格按照相同k2发往同一个reduce
细细发现, 方案一 和 方案二, 是有类似之处的, 方案一, 让每一个mapTask内部进行提前聚合, 然后到达reduce进行汇总合并得出结构, 方案二: 让第一个MR进行打散并对数据进行聚合计算 得出局部结果, 然后让第二个MR进行最终聚合计算操作, 得出最终结果
说明: 方案二, 比方案一, 更能彻底解决数据倾斜问题, 因为其处理数据范围更大, 整个整个数据集来处理, 而方案一, 只是每个MapTask处理, 仅仅局部处理
如何使用方案二:
只需要开启负载均衡的HIVE参数配置即可:
set hive.groupby.skewindata=true;
这两种方式: 建议在生产中, 优先使用第一种, 如果第一种无法解决, 尝试使用第二种解决
注意事项: 使用第二种负载均衡的解决group by 的数据倾斜, 一定要注意, SQL语句中不能出现多次 distinct操作, 否则 HIVE会直接报错的
错误信息:
Error in semantic analysis: DISTINCT on different columns not supported with skew in data.
比如说:
SELECT ip, count(DISTINCT uid), count(DISTINCT uname) FROMlog GROUP BY ip 此操作就直接报错了,只能使用方案一解决数据倾斜
思考: 如何才能知道发生了数据倾斜呢?
倾斜发生后, 出现的问题, 程序迟迟无法结束, 或者说翻译的MR中reduceTask有多个, 大部分的reduceTask都执行完成了, 只有其中一个或者几个没有执行完成, 此时认为发生了数据倾斜
关键点: 如何查看每一个reduceTask执行时间