Presto------分布式SQL查询引擎
Presto简介
大数据分析类软件发展历程。
- Apache Hadoop-MapReduce
- 优点:统一、通用、简单的编程模型,分而治之思想处理海量数据。
- 缺点:java学习成本高、MR执行慢、内部过程繁琐
- Apache Hive
- 优点:SQL on Hadoop。sql语言上手方便。学习成本低。
- 缺点:底层默认还是MapReduce引擎、慢、延迟高
- 各种SQL类计算引擎开始出现,主要追求的就是一个问题:计算如何更快,延迟如何降低。
- Presto/trino
- Spark On Hive、Spark SQL
- Flink
- …
FaceBook维护的原始版本: presto, 也叫prestoDB
Presto创始人团队离职后研发并维护的: PrestoSQL 因为版权更名为Trino
已经给大家整理好了对应网址如下:
FaceBook维护的, Presto的官网: https://prestodb.io/
创始人团队维护的, Trino的官网: https://trino.io/
Presto创始人团队维护的, 因为版权更名为Trino: http://github.com/trinodb/trino
相关文章如下:
Presto在有赞的实践之路: https://cloud.tencent.com/developer/news/606849
Presto更名为-Trino: https://www.sohu.com/a/441836081_106784
- 介绍
-
Presto是一个开源的分布式SQL查询引擎,适用于交互式查询,数据量支持GB到PB字节。
Presto的设计和编写完全是为了解决Facebook这样规模的商业数据仓库交互式分析和处理速度的问题。
presto简介: 一条Presto查询可以将多个数据源进行合并,可以跨越整个组织进行分析;
presto特点: Presto以分析师的需求作为目标,他们期望响应速度小于1秒到几分钟;
- 优缺点
优点
1)Presto与Hive对比,都能够处理PB级别的海量数据分析,但Presto是基于内存运算,减少没必要的硬盘IO,所以更快。
2)能够连接多个数据源,跨数据源连表查,如从Hive查询大量网站访问记录,然后从Mysql中匹配出设备信息。
3)部署也比Hive简单,因为Hive是基于HDFS的,需要先部署HDFS。
缺点
1)虽然能够处理PB级别的海量数据分析,但不是代表Presto把PB级别都放在内存中计算的。而是根据场景,如count,avg等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而Hive此时会更擅长。
2)为了达到实时查询,可能会想到用它直连MySql来操作查询,这效率并不会提升,瓶颈依然在MySql,此时还引入网络瓶颈,所以会比原本直接操作数据库要慢。
Presto-架构、相关术语
- 架构图
Presto是一个运行在多台服务器上的分布式系统。 完整安装包括一个coordinator和多个worker。
由客户端提交查询,从Presto命令行CLI提交到coordinator; coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker。

Presto查询引擎是一个Master-Slave的架构,由一个coordinator节点,一个Discovery Server节点,多个Worker节点组成,注意Discovery Server通常内嵌在Coordinator节点中。
主角色:Coordinator负责SQL的解析,生成执行计划,分发给Worker节点进行执行;
从角色:Worker节点负责实时查询执行任务。Worker节点启动后向discovery Server服务注册,Coordinator 从discovery server获取可以工作的Worker节点。
如果配置了hive connector,需要配置hive MetaSote服务为Presto提供元信息,worker节点和HDFS进行交互数据。
- Connector 连接器
1、Presto通过Connector连接器来连接访问不同数据源,例如Hive或mysql。连接器功能类似于数据库的驱动程序。允许Presto使用标准API与资源进行交互。
2、Presto包含几个内置连接器:JMX连接器,可访问内置系统表的System连接器,Hive连接器和旨在提供TPC-H基准数据的TPCH连接器。许多第三方开发人员都贡献了连接器,因此Presto可以访问各种数据源中的数据,比如:ES、Kafka、MongoDB、Redis、Postgre、Druid、Cassandra等。
- Catalog 连接目录: hive或者mysql等数据源
1、Presto Catalog是数据源schema的上一级,并通过连接器访问数据源。
2、例如,可以配置Hive Catalog以通过Hive Connector连接器提供对Hive信息的访问。
3、在Presto中使用表时,标准表名始终是被支持的。
例如,hive.test_data.test的标准表名将引用hive catalog中test_data schema中的test table。
Catalog需要在Presto的配置文件中进行配置。
- schema 库
Schema是组织表的一种方式。Catalog和Schema共同定义了一组可以查询的表。
当使用Presto访问Hive或关系数据库(例如MySQL)时,Schema会转换为目标数据库中的对应Schema(database)。
= schema通俗理解就是我们所讲的database.
= 想一下在hive中,下面这两个sql是否相等。
show databases; – presto不支持
show schemas;
presto-集群启停
[root@hadoop01 ~]# /export/server/presto/bin/launcher start
Started as 89560
# 可以使用jps 配合kill -9命令 关闭进程
web UI页面
链接: http://192.168.88.80:8090/ui/

Presto-Datagrip连接使用
-
JDBC 驱动:presto-jdbc-0.245.1.jar
-
JDBC 地址:jdbc:presto://192.168.88.80:8090/hive
-
step1:创建连接

Presto–时间日期类型注意事项
-
date_format(timestamp, format) ==> varchar
- 作用: 将指定的日期对象转换为字符串操作
-
date_parse(string, format) → timestamp
- 作用: 用于将字符串的日期数据转换为日期对象
select date_format( timestamp '2020-10-10 12:50:50' , '%Y/%m/%d %H:%i:%s');
select date_format( date_parse('2020:10:10 12-50-50','%Y:%m:%d %H-%i-%s') ,'%Y/%m/%d %H:%i:%s');
----
注意: 参数一必须是日期对象
所以如果传递的是字符串, 必须将先转换为日期对象:
方式一: 标识为日期对象, 但是格式必须为标准日期格式
timestamp '2020-10-10 12:50:50'
date '2020-10-10'
方式二: 如果不标准,先用date_parse解析成为标准
date_parse('2020-10-10 12:50:50','%Y-%m-%d %H:%i:%s')
扩展说明: 日期format格式说明
年:%Y
月:%m
日:%d
时:%H
分:%i
秒:%s
周几:%w(0..6)
-
date_add(unit, value, timestamp) → [same as input]
- 作用: 用于对日期数据进行 加 减 操作
-
date_diff(unit, timestamp1, timestamp2) → bigint
- 作用: 用于比对两个日期之间差值(后者-前者)
select date_add('hour',3,timestamp '2021-09-02 15:59:50');
select date_add('day',-1,timestamp '2021-09-02 15:59:50');
select date_add('month',-1,timestamp '2021-09-02 15:59:50');
select date_diff('year',timestamp '2020-09-02 06:30:30',timestamp '2021-09-02 15:59:50')
select date_diff('month',timestamp '2021-06-02 06:30:30',timestamp '2021-09-02 15:59:50')
select date_diff('day',timestamp '2021-08-02 06:30:30',timestamp '2021-09-02 15:59:50')
Presto-常规优化
数据存储优化:
–1)合理设置分区
与Hive类似,Presto会根据元信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能。
–2)使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好。
Parquet和ORC一样都支持列式存储,但是Presto对ORC支持更好,而Impala对Parquet支持更好。在数仓设计时,要根据后续可能的查询引擎合理设置数据存储格式。
–3)使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于需要快速解压的,建议采用Snappy压缩。
–4)预先排序
对于已经排序的数据,在查询的数据过滤阶段,ORC格式支持跳过读取不必要的数据。比如对于经常需要过滤的字段可以预先排序。
SQL优化:
- 列裁剪
- 分区裁剪
- group by优化
- 按照数据量大小降序排列
- order by使用limit
- join时候大表放置在左边
- 替换非ORC格式的Hive表
Presto-内存调优
内存管理机制–内存分类
Presto管理的内存分为两大类:user memory和system memory
-
user memory用户内存
跟用户数据相关的,比如读取用户输入数据会占据相应的内存,这种内存的占用量跟用户底层数据量大小是强相关的 -
system memory系统内存
执行过程中衍生出的副产品,比如tablescan表扫描,write buffers写入缓冲区,跟查询输入的数据本身不强相关的内存。 -
内存管理机制–内存池

1、GENERAL_POOL:在一般情况下,一个查询执行所需要的user/system内存都是从general pool中分配的,reserved pool在一般情况下是空闲不用的。
2、RESERVED_POOL:大部分时间里是不参与计算的,但是当集群中某个Worker节点的general pool消耗殆尽之后,coordinator会选择集群中内存占用最多的查询,把这个查询分配到reserved pool,这样这个大查询自己可以继续执行,而腾出来的内存也使得其它的查询可以继续执行,从而避免整个系统阻塞。
注意:
reserved pool到底多大呢?这个是没有直接的配置可以设置的,他的大小上限就是集群允许的最大的查询的大小(query.total-max-memory-per-node)。
reserved pool也有缺点,一个是在普通模式下这块内存会被浪费掉了,二是大查询可以用Hive来替代。因此也可以禁用掉reserved pool(experimental.reserved-pool-enabled设置为false),那系统内存耗尽的时候没有reserved pool怎么办呢?它有一个OOM Killer的机制,对于超出内存限制的大查询SQL将会被系统Kill掉,从而避免影响整个presto。
- 内存相关参数
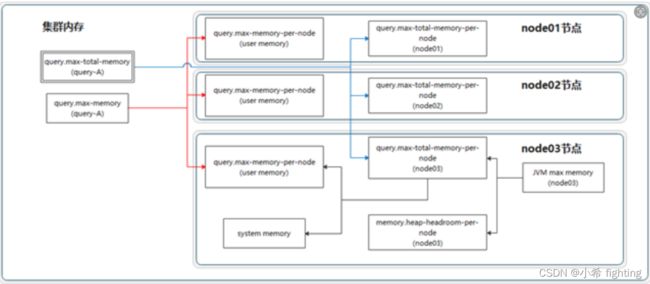
1、user memory用户内存参数
query.max-memory-per-node:单个query操作在单个worker上user memory能用的最大值
query.max-memory:单个query在整个集群中允许占用的最大user memory
2、user+system总内存参数
query.max-total-memory-per-node:单个query操作可在单个worker上使用的最大(user + system)内存
query.max-total-memory:单个query在整个集群中允许占用的最大(user + system) memory
当这些阈值被突破的时候,query会以insufficient memory(内存不足)的错误被终结。
3、协助阻止机制
在高内存压力下保持系统稳定。当general pool常规内存池已满时,操作会被置为blocked阻塞状态,直到通用池中的内存可用为止。此机制可防止激进的查询填满JVM堆并引起可靠性问题。
4、其他参数
memory.heap-headroom-per-node:这个内存是JVM堆中预留给第三方库的内存分配,presto无法跟踪统计,默认值是-Xmx * 0.3
5、结论
GeneralPool = 服务器总内存 - ReservedPool - memory.heap-headroom-per-node - Linux系统内存
常规内存池内存大小=服务器物理总内存-服务器linux操作系统内存-预留内存池大小-预留给第三方库内存
-
内存优化建议
- 常见的报错解决
1、Query exceeded per-node total memory limit of xx
适当增加query.max-total-memory-per-node。2、Query exceeded distributed user memory limit of xx
适当增加query.max-memory。3、Could not communicate with the remote task. The node may have crashed or be under too much load
内存不够,导致节点crash,可以查看/var/log/message。- 建议参数设置
1、query.max-memory-per-node和query.max-total-memory-per-node是query操作使用的主要内存配置,因此这两个配置可以适当加大。
memory.heap-headroom-per-node是三方库的内存,默认值是JVM-Xmx * 0.3,可以手动改小一些。-
各节点JVM内存推荐大小: 当前节点剩余内存*80%
-
对于heap-headroom-pre-node第三方库的内存配置: 建议jvm内存的%15左右
-
在配置的时候, 不要正正好好, 建议预留一点点, 以免出现问题
数据量在35TB , presto节点数量大约在30台左右 (128GB内存 + 8核CPU)
注意:
1、query.max-memory-per-node小于query.max-total-memory-per-node。
2、query.max-memory小于query.max-total-memory。
3、query.max-total-memory-per-node 与memory.heap-headroom-per-node 之和必须小于 jvm max memory,也就是jvm.config 中配置的-Xmx。