Shell脚本学习指南(三)——文本处理工具
文章目录
- 排序文本
-
- 行的排序
- 以字段的排序
- 文本块排序
- sort的效率
- sort的稳定性
- sort小结
- 删除重复
- 重新格式化段落
- 计算行数、字数以及字符数
- 打印
-
- 打印技术的演化
- 其他打印软件
- 提取开头或结尾数行
排序文本
含有独立数据记录的文本文恶剪,通常都可以拿来排序。一个可预期的记录次序,会让用户的生活更便利:书的索引、字典、目录以及电话薄,如果没有次序依据就毫无价值。排序后的记录更易于程序化;也更有效率。
就像awk、cut与join一样:sort将输入看做具有多条记录的数据流,而记录是由可宽度的字段组成,记录是以换行字符作为定界符,字段的定界符则是空白哦字符或是用户指定的单个字符。
行的排序
以最简单的情况来说,未提供命令行选项时,整个记录都会根据当前locale所定义的次序排序。在传统的C locale中,也就是ASCII顺序。也可以像之前介绍的那样,设置另一种locale。


排序的惯例,完全视语言、国家以及文化而定,且这样的规则有时会非常复杂。即便是英文这种看起来与重音不相关的语言,都有复杂的排序规则。
以字段的排序
如果要进一步控制排序操作,可以用-k选项指定排序字段,并且用-t选项来选择字段定界符。
如未指定-t则表示字段以空白分隔且记录内开头与结尾的空白都将忽略;如指定-t选项,则被指定的字符会分割字段,且空白是有意义的。因此一个包括“空白-X-空白”三个字符的记录,如果没有指定-t则只由一个字段,如果使用-t,则为三个字段。
-k选项的后面接着的是一个字段的编号,或是一对数字,有时在-k之后可用空白分隔。每个编号后面都可以接一个点号的字符位置,及/或修饰符字母之一,如下。
| b | 忽略开头的空白 |
|---|---|
| d | 字典排序 |
| f | 不区分字母的大小写 |
| g | 以一般的浮点数字进行比较,只适用于GNU版本 |
| i | 忽略无法打印的字符 |
| n | 以整数数字比较 |
| r | 倒序排序的顺序 |
字段以及字段里的字符是由1开始。
如果仅指定一个字段编号,则排序键值会自该字段的起始处开始,一直继续到记录的结尾(而非字段的结尾)。
如果给的是一对用逗号隔开的字段数字,则排序键值将由第一个字段值的其实处开始,结束于第二个字段的结尾。
使用点号字符位置,则比较的开始(一对数组的第一个)或结束(一对数字的第二个)在该字符位置处:-k2.4,5.6指的是从第二个字段的第四个字符开始比较,一直逼到第五个字段的第六个字符。
如果一个排序键值的起始正好落在记录的结尾之后,在排序键值为空,且空的排序键值在排序时将有限与所有非空的键值。
当出现多个-k选项时,会先从第一个键值开始排序,找出匹配该键值的记录后,再进行第二个键值字段的排序,以此类推。
实例:我们可以在password范例文件上试试这些选项,以冒号隔开的第一个字段:用户名称,进行排序:
sort -t: -k 1,1 /etc/passwd
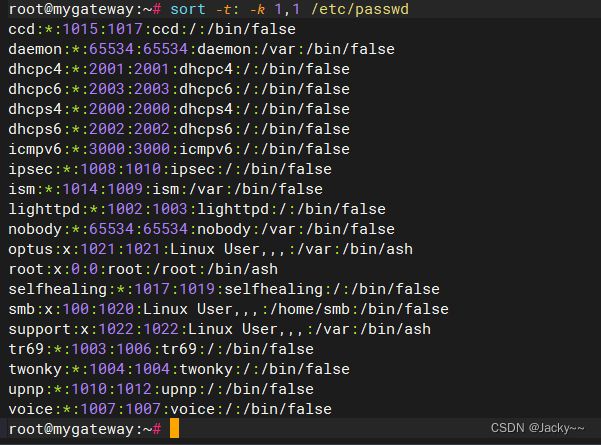
如果要再进一步控制排序后的结果,可在字段选择器内,加入一个修饰字母,定义字段里的数据类型及排序顺序。这里显示按照反向顺序的UID来排序password文件的结果:
sort -t: -k3nr /etc/passwd

更精确的字段规定应为-k3nr,3(也就是从3字段开始,以数值类型反向排序,并结束于字段3的结尾),或是-k3,3nr,甚至-k3,3 -n -r,由于sort会在遇到第一个非阿拉伯数字处停止收集数据,所以-k3nr也正确。
在我们的password返利文件里,有三个用户拥有GID(字段4),因此我们可以先以GID排序,再以UID排序:
sort -t: -k4n -k3n /etc/passwd

-u选项的好用是在于:它可以要求sort仅输出唯一的记录,而“唯一的”是指他们的排序键值字段匹配,即使在记录的其他地方有差异也无所谓。我们再利用password文件看一次:
sort -t: -k4n -u /etc/passwd

对比上面发现输出结果变短了。
文本块排序
有时,不会需要将多行记录组合而成的数据进行排序。地址清单就是一个很好的例子,为了方便阅读,地址记录经常会切断,以一个或数个空行将彼此隔开。像这种数据,没有一定的排序键值位置可供-k选项使用,所以你得自救,提供一些额外的标记给这些数据,这里是一个简单的范例:


这里排序的小技巧,就是利用awk处理较一般性的记录分隔字符的能力,识别段落间隔,在每个地址内暂时使用一个未使用过的字符(例如使用一个无法打印的控制字符)。取代分行,以及用换行字符取代段落间隔。sort看到的行就会变成这样:

在这里,^Z是一个Ctrl-Z字符。第一步过滤步骤就通过sort排序后恢复换行与段落的分隔符号,且排序键值行是容易删除的,如有需要,可以使用grep轻松删除他们。整个管道看起来就像这样:
cat my-friends | # 在地址数据文件里的管道
awk -v RS="" '{gsub("\n","^Z"); print}' | # 转换地址为单个行
sort -f | # 排序地址结构,忽略大小写
awk -v ORS="\n\n" '{gsub("^Z", "\n);print}' | #恢复行结构
grep -v '# SORTKEY' # 删除标记行
函数gsub()功能为全局性替换,类似sed下的s/x/y/g架构。RS变量是输入数据的记录分隔器。通常输入数据是以换行字符隔开,使每一行成为单个的记录。RS=""是一个特殊的用法,指的是记录以空行的方式隔开;例如每个块或文本段楼自称一个记录。这就是我们的例子里输入的数据形式。最后,ORS指的是输出记录分隔器;以print显示的每条输出记录会以其值作为终止。一般来说默认值为单个换行符;在此设置它为"\n\n",是为了保持用空包行分隔记录的输入格式。
最后输出结果如下


sort的效率
UNIX的sort命令实现,已有许多人在进行研究并优化调整:你可以相信它的工作效率,它一定可以比你自己做的好,而且几乎不必学习一堆的排序算法。
sort的稳定性
在排序算法里有个重要的问题:是否稳定?这个问题指的是:相同的记录输入顺序是否在输出时也可保持原状?当你以多个键值为记录进行排序,或是以管道处理时,排序稳定性就非常重要了。POSIX不需要这个所谓的sort的稳定性,绝大多数的实现也不需要,来看看下面这个范例:
$ sort -t_ -k1,1 -k2,2 <<EOF
> one_two
> one_two_three
> one_two_four
> one_two_five
> EOF
one_two
one_two_five
one_two_four
one_two_three> EOF
每条记录内的排序字段都相同,但输出却与输入不一致,所以我们说sort并不稳定。幸好:GNU实现了coreutils包弥补不足。可以通过--stable选项补救此问题:设置此选项,上例输出便可与输入一致了。

sort小结
sort绝对排的进UNIX重要命令的前十名:把他学号一定没错,因为你会经常用到。sort经过POSIX的标准化,所以几乎在所有机器上都能使用。
删除重复
有时,将数据流里连续重复的记录删除是有必要的。前面我们介绍过sort -u,不过我们也知道,他的消除操作是依据匹配的键值,而非匹配的记录。uniq命令提供另一种过滤数据的方式:它常用于管道中,用来删除已使用sort排序完成的重复记录:
sort .. | uniq |...
uniq有三个好用的选项:-c可在每个输出行之前加上该行重复的次数,这部分我们后面会用到;-d选项则用于显示重复的行;而-u仅显示未重复的行。下面是例子:
uniq有时会拿来与diff工具搭配应用,找出两个相似数据流的异同的时候很方便,例如字典单词列表,在映射目录树内的路径、电话簿等等。在大部分的实现中有很多其他的选项可供使用,你可以在uniq手册里找到相关描述,不过它们很少使用。而uniq就像sort一样,已被POSIX标准化,所以在哪儿都可以使用。
重新格式化段落
大部分功能强大的文本编辑器都提供重新格式化段落的命令;供用户切分段落,使文本行数不要超出我们看到的屏幕范围;有时你在Shell脚本内处理数据流时需要完成重新格式化;或者在一个缺乏重新格式化命令但提供了Shell转义的编辑器内完成它。在不提供此功能的情况下,你使用fmt命令。虽然POSIX未提及fmt,但是你还是可以在许多现行的UNIX系统下找到它;如果你的旧系统中没有fmt,只要安装GNU的coreutils包即可。
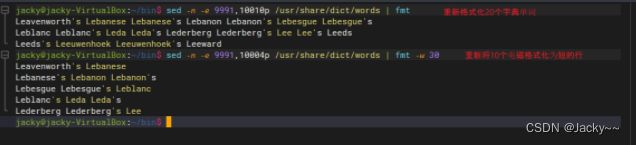
虽然fmt的实现有较多的选项可用,但其实我们发现只有两种比较常用的选项
-s仅切割较长行,但不会将短行结合成较长行
-w n则设置输出行宽度为n个字符(默认通常为75个左右)。举例如下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1y62FHeu-1668774903715)(file://C:\Users\g700382\AppData\Roaming\marktext\images\2022-11-18-19-30-07-image.png)]
仅做切割的选项:-s,在你想将长的行绕回,短的行保持不动时很好用,这么做也能使结果与原始版本间的差异达到最小:
$ fmt -s -w 10 << END_OF_DATA
> one two three four five
> six
> seven
> eight
> END_OF_DATA
one two
three
four five
six
seven
eight
jacky@jacky-VirtualBox:~/bin$
计算行数、字数以及字符数
我们已使用过数字计算工具wc好几次了。他可能是UNIX工具集里最古老也是最简单的工具程序;同时POSIX也已将它标准化。wc的默认输出是一行报告,包括行数、字数以及字节数:
$ echo This is a test of the emergency broadcast system | wc
1 9 49
这是一个计数报告,要求仅输出部分结果时,可使用的选项有:-c(字节数)、-l(行数)、-w(字数)。
$ echo Testing one two three | wc -c
22
$ echo Testing one two three | wc -l
1
$ echo Testing one two three | wc -w
4
-c选项原本是表示字符数,但是因为有多字节字符集的编码存在——像UTF-8,因此当前系统上,字节数已不再等同于字符数了。也因此,POSIX出现了-m选项,用于计算多字节字符,对于8位字符数据而言,他等同于-c的。
虽然wc最常处理的是来自于管道的输入数据,但它也接受命令行的文件参数,可以生成一行一行的结果,再附上报告:

打印
和计算机比起来,打印机是比较慢的设备,因为他们一般都是共享的,通常不希望用户直接传递工作给它们;因此,大部分的操作系统都是提供命令,让用户传送需要到打印daemon中,daemon将打印的工作放入队列,并处理打印机与队列管理。打印命令的处理可以很快,因为打印是在所需的资源呈现可用状态时,才能在后台中被执行。
UNIX里支持的打印功能包括了两类不同的命令,但拥有相同的功能,(商用的UNIX个GNU/Linux的都支持)如图所示

以下是案例

麻烦的是,使用现代网络化的智能型打印机的时候,lprm、cancel、lpq以及lpstat这样的命令已经不像以前那么好用了:打印工作很快就传到打印机,并出现在打印机daemon上,显示好了,然后从打印机队列中删除——即使打印机仍然将它们搁在内存或是文件系统里,这时,他仍能同时处理其他的打印工作。就这点来看,唯一要用到的资源,就是利用打印机的控制面板,取消不想要的工作。
打印技术的演化

其他打印软件
不要被pr的名字欺骗了,它其实并不是打印文件用的命令,他不过是过滤数据为打印做准备。以简单的情形来说,pr会以文件的修改时间作为页面标题的时间戳;如果输入自管道而来,则使用当前的时间,接上文件名称(如果输入的数据内容在管道中,则为空)以及页码,以每页股东行数的方式打印。也就是这样:
pr file(s) | lp
会显式适当的列表。不过,自从20世纪70年代古老的机械式打印机退役之后,这种简化的方式就不再有效了。每种打印机默认的字体大小与行列空间都不同,而且平常使用的纸张大小也不一样了。

反而比较常用的是-l选项设置输出页面长度、-w设置页面宽度、-o设置文本位移。另外还有-f也是必备的(有些系统是-F)——用来在首页后的每页页标题加入ASCII分页控制字符,这是为了保障每页页标题都起始于新的一页。所以实际上你应该会这样用
pr -f -l60 -o10 -w65 file(s) | lp
pr有一个功能可通用于多数情况下:以-ch选项要求n栏输出。如果搭配-t选项可省略页标题,这样就可以产生适当的多栏列表。下面这个例子便是将26个单词格式化为5栏的状态

如果栏宽太小,pr会默认截去超出的数据,以避免该行过长。我们可以试试看将上例26个单词格式化为10栏,如下所示

关于文本到PostScript的过滤器这里不介绍
提取开头或结尾数行
有时,你会需要从文本文件里把几行字——多半是靠近开头或结尾的几行,提取出来。或者,有时你只要瞧瞧工作日志的后面几行,就可以了解最近工作活动的大概情况。
这两种操作都很简单,你可以用下面这几招,显示标准输入前n条记录,或是命令行文件列表中的每一个的前n条记录:

POSIX要求head选项需要设为-n 3,不接受-3但是实际上两种都可以
如果只有单个编辑命令时,sed允许省略-e选项。
如果这里显示的行少于n,其并非有误。
要显示结尾数行,可以这么做:

在交互式Shell通信期中,有时需要监控某个文件的输出——如日志这类持续写入状态的文件。-f选项这时就派上用场了,它可以要求tail显示指定的文件结尾数行,接着进入无止尽的循环中——休息一秒又再度醒来并检查是否需要显示更多的输出结果。在设置-f状态下,tail只有当你中断它时他才会停止——通常是输入Ctrl-C来中断:

由于tail加上-f选项后便不会自己中断,所以此选项不可用于Shell脚本。
因为tail的工作必须一直维护最近记录的历史,因此使用awk或者sed时,没有更短或更简单的方式替代tail。
虽然我们无法在这里详细解释这些工具,不过你应留意下面的几个命令,这些命令在后面的范例中都会用到,值得你加入工具箱:
-
dd以用户指定的块大小与数量拷贝数据。不过他也具有一些有限的能力,可进行大小写转换,以及ASCII与EBCDIC间的转换。以字符集转换而言,现在的,POSIX标准的iconv命令可以将文件从一种编码集转换为另一种更具灵活性的字码集。 -
file将其参数文件内容的前几个字节,与样式数据库进行比对,再在标准输出下,针对各文件显示一行简短报告。绝大多数厂商提供file版本可以识别100种左右的文件类型,不过无法分辨来自其他UNIX风格的二进制可执行文件与对象文件,或是来自其他操作系统的文件。还有一种更好用的开放源代码版本,由于许多人的贡献,让我们可以享受到它的便利:它识别的文件类型有1200多种,包含许多非UNIX操作系统下的文件。 -
od为八进制转储命令,显示ASCII码,八进制以及十六进制的字节数据流。可以在命令行选项中设置要读取的字节数,也可以选择删除格式。 -
strings针对输入数据查找以换行符号或NUL结尾的四个或以上可打印字符的序列,再将结果打印至标准输出。多半用来查看二进制文件——例如编译后的程序或数据文件的内部信息。桌面应用软件、图像以及声音文件有时也会在文件的开头处包含一些有用的文本数据,而GNU的head还提供一个方面的-c选项,让用户以限制输出的字符数:
