Linux磁盘管理(分区,SWAP,LVM,RAID,热备份)
分区
概念:
-
数据组织和管理: 磁盘分区允许将硬盘空间划分为多个逻辑单元,这有助于更有效地组织和管理数据。不同类型的数据可以存储在不同的分区中,使数据更易于维护和备份。
-
提高性能: 分区可以用于分隔操作系统文件、应用程序文件和用户数据,从而提高系统的性能。例如,将操作系统文件与用户数据分开可以减少碎片和提高文件访问速度。
-
数据安全: 如果整个磁盘只有一个分区,文件系统损坏或数据丢失的风险较大。通过分区,可以隔离不同类型的数据,以降低潜在的数据丢失风险。如果一个分区损坏,其他分区的数据通常不会受到影响。
-
备份和还原: 分区可以帮助更轻松地进行数据备份和还原。可以选择性地备份特定分区,而不是整个硬盘,从而节省时间和存储空间。
-
多操作系统支持: 如果需要在同一台计算机上安装多个操作系统(如Linux和Windows),分区是必要的。每个操作系统通常需要分配一个独立的分区来安装和运行。
-
磁盘空间利用率: 可以根据需要调整每个分区的大小,以便更有效地利用磁盘空间。这对于避免空间浪费和确保系统正常运行非常重要。
-
磁盘维护: 分区还有助于简化磁盘维护任务,如文件系统检查和碎片整理。可以定期检查和维护每个分区,而不必操作整个硬盘。
总之,磁盘分区在Linux系统中起到关键作用,帮助用户更好地管理磁盘空间、提高性能、确保数据安全性和实现灵活性。不同类型的分区可以满足不同的需求,根据具体情况划分分区将有助于提高系统的效率和可维护性。
mbr分区
-
4个主分区限制: MBR分区表支持最多4个主分区。这意味着最多可以将硬盘划分为4个独立的主分区,每个分区可以包含一个文件系统。
-
逻辑分区和扩展分区: 如果需要更多的分区,可以使用一个主分区来创建一个扩展分区,然后在扩展分区内创建多个逻辑分区。这种方式允许克服4个主分区的限制,但需要额外的步骤和管理。
-
2 TB分区大小限制: MBR分区表最大支持2 TB(2^41字节)的分区大小。如果硬盘容量超过2 TB,将无法充分利用所有可用空间。
-
不支持UEFI: MBR分区表在传统BIOS系统上工作得很好,但不支持现代UEFI(统一扩展固件接口)系统,这些系统通常使用GPT(GUID分区表)来替代MBR。
需要注意的是,MBR分区表在现代计算机中逐渐被GPT分区表所取代,因为GPT提供更多的分区支持、更大的硬盘容量支持以及更好的数据完整性和安全性。如果您的计算机支持UEFI,通常更推荐使用GPT分区表。但对于老旧的BIOS系统,MBR分区仍然是一种常见的分区方案。
分区实例
加装硬盘
找到设置




 刷新硬件设备,并查看磁盘,确认磁盘已被识别
刷新硬件设备,并查看磁盘,确认磁盘已被识别
设置一个别名方便刷新等操作
alias scan='echo "- - -" > /sys/class/scsi_host/host0/scan;echo "- - -" > /sys/class/scsi_host/host1/scan;echo "- - -" > /sys/class/scsi_host/host2/scan'
//设置一个别名,将硬件刷新的过程直接赋予给别名,方便后续使用 查看磁盘
查看磁盘
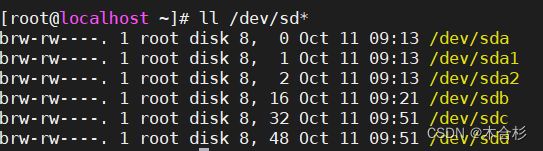

建立主分区,使用fdisk工具
 删除分区方法
删除分区方法
写入n改为d
2T以上分区
2T以上的就不太适合使用fdisk了,使用gdisk

下载gdisk
sudo yum install gdisk
建立文件系统
文件系统
-
组织和存储,文件系统提供了组织数据的结构,能够把文件分为不同的目录。然后经过组织的数据可以存储在物理设备上
-
数据访问:文件系统提供了对存储设备的访问接口,通过接口访问存储设备中的数据
-
数据管理:文件系统提供了数据的管理功能,包括文件或者目录的复制,移动,删除,重命名。
-
数据保护:文件通过权限的控制机制,限制不同用户的访问权限
创建(格式化)文件系统



查看一下文件类型,确认操作成功

挂载
挂载点:挂载点必须是一个已经存在的,而且最好是一个新创建的空目录(避免目录内数据被覆盖)
临时挂载,重启消失
先创建一个空文件夹data为挂载点

查看是否挂载成功

解挂载(取消挂载)
![]()
强制解挂载 umount -lf
永久挂载
vim /etc/fstab
///etc/fstab(文件系统表)是Linux系统中的一个配置文件,它包含了关于系统中要挂载的文件系统以及挂载选项的信息。这个文件通常用于定义系统启动时自动挂载的文件系统。
//绝对不能打错,否测重启后虚拟机无法使用
0 0 :表示不对数据备份 不检查分区的文件系统 (目的是提高效率)


SWAP交换分区
系统是有物理内存,物理内存不够用,就需要将其他物理内存当中的一部分空间,进行释放。提供给物理内存使用。释放出来的空间保存在swap当中,用完后,摆存在swap中的内存还会被释放给程序。
Swap交换分区的主要作用包括:
-
内存扩展:允许系统在物理内存不足时继续运行应用程序,虽然性能可能会降低,但不会导致崩溃。
-
进程暂存:将不活跃的进程或数据移到Swap分区,以便物理内存可以用于更紧急的任务。
-
系统稳定性:通过避免内存耗尽,保证系统的稳定性和可用性。
在选择Swap分区的大小时,通常的建议是:
-
如果物理内存小于4GB,Swap分区大小应至少为物理内存的2倍。
-
如果物理内存在4GB到16GB之间,Swap分区大小可以设置为物理内存大小的1.5倍。
-
如果物理内存大于16GB,Swap分区大小可以设置为物理内存的相对较小比例,如16GB或32GB。

 对新分区进行swap挂载
对新分区进行swap挂载
mkswap /dev/sdc1 //创建swap的系统文件类型
swapon /dev/sdc1 //启动该分区
//swap完成扩容LVM
概念
LVM(Logical Volume Manager)是一种在Linux系统上用于管理磁盘存储的高级工具,它提供了磁盘虚拟化和逻辑卷管理的功能。LVM使得磁盘管理更加灵活,允许你创建、调整和管理逻辑卷,而无需依赖于物理磁盘的分区。
LVM的常用操作:
-
创建物理卷(Physical Volume):使用
pvcreate命令创建一个物理卷,这可以是硬盘分区或其他块设备。 -
创建卷组(Volume Group):使用
vgcreate命令创建一个卷组,并将一个或多个物理卷添加到卷组中。 -
创建逻辑卷(Logical Volume):使用
lvcreate命令在卷组内创建逻辑卷,可以指定大小和名称。 -
格式化和挂载逻辑卷(Logical Volume):使用标准文件系统工具(如
mkfs和mount)对逻辑卷进行格式化并挂载到文件系统中。 -
调整逻辑卷大小:使用
lvresize命令来扩展或缩小逻辑卷的大小。 -
移除逻辑卷或卷组:使用
lvremove命令来删除不再需要的逻辑卷,使用vgremove命令来删除卷组。 -
扩展卷组:将新的物理卷添加到现有卷组以扩展存储容量。
-
迁移数据:LVM允许你在物理卷之间移动数据,这对于替换硬盘或重新平衡存储非常有用。
LVM的主要优点包括了灵活性、数据保护和动态调整的能力。它使得存储管理更加容易,并且可以适应变化的需求。然而,使用LVM也需要谨慎,因为不正确的操作可能导致数据丢失。因此,在使用LVM之前,建议备份重要数据并仔细阅读LVM的文档以了解其工作原理。

基本组成
-
物理卷(Physical Volume,PV):物理卷是LVM的基本构建块,可以是硬盘分区、磁盘驱动器或者网络存储设备。这些物理卷被加入到LVM系统中,以便创建逻辑卷。
-
卷组(Volume Group,VG):卷组是物理卷的集合,它充当了逻辑卷的容器。你可以将一个或多个物理卷添加到卷组中,并在操作系统中将卷组表示为单个设备。这使得卷组内的物理卷能够一起协同工作。
-
逻辑卷(Logical Volume,LV):逻辑卷是在卷组内创建的虚拟卷,它类似于传统的硬盘分区,但更加灵活。逻辑卷可以动态调整大小,而无需重新分区硬盘。
-
物理块(Physical Extent,PE):物理块是物理卷的逻辑分割。卷组中的逻辑卷由物理块构建,而物理块的大小是LVM配置的一部分。

主要命令

创建卷组(在已有物理卷的前提下)


卷组名为jz1,后面是物理卷的地址
查看卷组
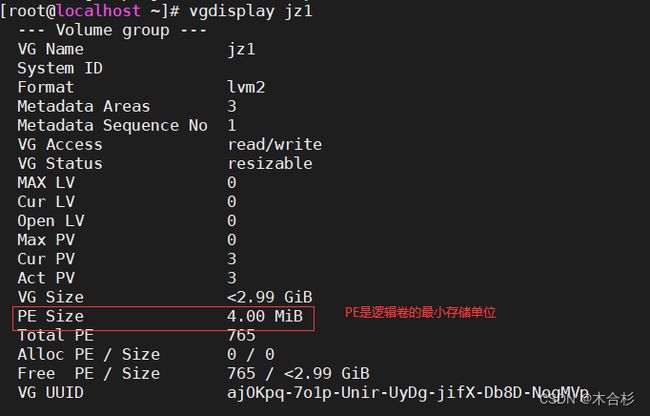 创建逻辑卷
创建逻辑卷

-L +2G:指定了逻辑卷的大小,大于卷组会创建失败
-n:指定逻辑卷名称
最后是卷组名程,指定哪个卷组创建逻辑卷
查看逻辑卷

建立文件系统并挂载
建立文件系统
 挂载
挂载
![]()
查看

逻辑卷扩容(当逻辑卷空间满时)
查看

扩容

lvextend: 这是命令本身,用于执行逻辑卷的扩展操作。
-L: 这是参数,用于指定要扩展的逻辑卷的新大小。
+10M: 这是 -L 参数后面的值,表示要将逻辑卷扩展 10MB。+ 表示要在当前大小的基础上增加 10MB。
/dev/jz1/lj1: 这是要扩展的逻辑卷的路径。/dev/jz1/lj1 表示逻辑卷的路径,其中 /dev 是设备目录,jz1 是卷组(Volume Group)的名称,lj1 是逻辑卷的名称。
所以,这个命令的含义是扩展位于卷组 /dev/jz1 中的逻辑卷 lj1,将其大小增加 10MB。
刷新,扩容成功

缩容(xfs文件系统不能缩容,ext43可以缩容。)
先解挂载,再缩容
磁盘配额


前期准备

关闭检测

赋权
![]()
解挂载
必须要以磁盘配额的方式实现挂载。否则,就会报错

限制磁盘

 限制文件数
限制文件数
![]()
模拟创建一个大小为120M的文件。
dd if=/dev/zero of=/test/123.txt bs=10M count=12 dd 连续复制的命令 if=指定输出的文件 /dev/zero 零设备文件,可以提供无限的空字符,可以用来生成一个特定大小的文件 of 把这些空字符指向到文件 bs=10M 每一次复制的大小是10M count:复制12次
 取消配额
取消配额
xfs_quota -x -c 'disable -up' /data

RAID
是一种数据存储技术,旨在提高数据的可用性、冗余和性能。它通过将多个硬盘驱动器组合在一起,以创建一个单一的逻辑存储单元,从而提供了数据保护和性能增益。不同的RAID级别提供不同的数据保护和性能特性。
- RAID 0:
-
也称为条带化(striping),数据被均匀分布在两个或更多硬盘上。
-
提供了卓越的性能,因为数据可以同时从多个磁盘读取和写入。
-
不提供冗余,如果一个硬盘故障,所有数据都会丢失。
-
读写最快
- RAID 1:
-
也称为镜像,数据被复制到两个或更多硬盘上。
-
提供了数据冗余,如果一个硬盘故障,数据仍然可用。
-
性能通常不如RAID 0,因为数据必须同时写入多个硬盘。
-
硬盘个数必须是偶数
-
写的速度稍慢,读性能和raid0相似
- RAID 5:
-
使用分布式奇偶校验来实现数据冗余和性能。
-
数据被分成块并存储在多个硬盘上,每个块的奇偶校验也存储在不同硬盘上。
-
如果一个硬盘故障,数据可以通过奇偶校验重建。
-
提供了良好的性能和适度的冗余。
-
最少三块硬盘,磁盘利用率:(n-1)N
-
写性能差,读性能强
- RAID 6:
-
类似于RAID 5,但使用了两个独立的奇偶校验块,提供了更高级别的冗余。
-
可以容忍两个硬盘的故障。
-
提供了良好的性能和更高级别的数据冗余。
-
最少四块盘
-
读性能还行,写性能特别差
- RAID 10:
-
也称为RAID 1+0,是RAID 0和RAID 1的组合。
-
数据首先被镜像,然后被条带化,提供了高性能和高冗余。
-
可以容忍基组内各坏一个,具有很高的可用性。
-
最少四块,且必须偶数个
- RAID 50:
-
也称为RAID 5+0,是RAID 5的条带化版本。
-
数据被分成块并存储在多个RAID 5组中,然后这些组被条带化。
-
提供了高性能和适度的冗余。
- RAID 60:
-
类似于RAID 50,但使用了两个独立的RAID 6组,提供更高级别的冗余。
-
可以容忍多个硬盘的故障。
选择适当的RAID级别取决于特定需求,包括性能、数据冗余和可用性。RAID技术是在硬件和软件级别都可以实施的,通常用于服务器、存储阵列和数据中心等环境,以保护和提高数据的可用性
热备份
在Linux系统中,磁盘热备份通常是通过软RAID(Redundant Array of Independent Disks)技术来实现的。软RAID允许你将多个物理磁盘组合成一个逻辑卷,提高数据冗余和可用性。其中,热备份是一种方式,用于在主要磁盘故障时迅速切换到备用磁盘。
以下是在Linux中配置热备份的一般步骤:
-
安装
mdadm:首先,确保你的系统上安装了mdadm,这是Linux上管理软RAID的工具。你可以使用包管理器来安装它,如apt(Debian/Ubuntu)或yum(CentOS/RHEL)。 -
添加物理磁盘:如果你有额外的物理磁盘,将它们连接到系统并识别它们。你可以使用命令
fdisk -l来列出所有磁盘。 -
创建RAID数组:使用
mdadm命令创建RAID数组。例如,如果要创建一个RAID 1(镜像)数组,可以运行如下命令:
mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sdX /dev/sdY
其中,/dev/md0是新的RAID设备名称,--level指定了RAID级别(1表示镜像),--raid-devices指定了参与热备份的物理磁盘。
4.创建文件系统:一旦创建了RAID数组,你需要在上面创建文件系统。你可以使用mkfs命令来执行此操作,如:
mkfs.ext4 /dev/md0
5.挂载RAID数组:将新创建的RAID数组挂载到系统中的某个目录,以便访问数据。你可以使用mount命令来挂载它,或者将其添加到/etc/fstab以在系统启动时自动挂载。
6.添加热备份:对于热备份,你可以使用mdadm命令将其他物理磁盘添加为备用设备。例如:
mdadm /dev/md0 --add /dev/sdZ
这样,如果主要磁盘故障,备用磁盘会接管工作。
7.监控和维护:定期检查RAID数组的状态,确保一切正常。你可以使用mdadm命令来查看数组状态和事件日志。
磁盘热备份提供了数据冗余和可用性,但需要小心配置和维护,以确保它能够正常工作。请注意,以上步骤中的命令和选项可能会根据你的需求和Linux发行版而有所不同。在执行任何RAID操作之前,请务必备份重要数据,并仔细查阅相关文档。
综合实验示例(RAID5热备份)
创建

查看创建进度

详细信息


格式化,挂载

测试
写入数据

强制下线


这里强制下线了sdb1,可以看到sde1顶了上来,热备份成功