《PySpark大数据分析实战》-12.Spark on YARN配置Spark运行在YARN上
博主简介
- 作者简介:大家好,我是wux_labs。
热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。
通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP)、TiDB数据库认证SQL开发专家(PCSD)认证。
通过了微软Azure开发人员、Azure数据工程师、Azure解决方案架构师专家认证。
对大数据技术栈Hadoop、Hive、Spark、Kafka等有深入研究,对Databricks的使用有丰富的经验。- 个人主页:wux_labs,如果您对我还算满意,请关注一下吧~
- 个人社区:数据科学社区,如果您是数据科学爱好者,一起来交流吧~
- 请支持我:欢迎大家 点赞+收藏⭐️+吐槽,您的支持是我持续创作的动力~
《PySpark大数据分析实战》-12.Spark on YARN配置Spark运行在YARN上
- 《PySpark大数据分析实战》-12.Spark on YARN配置Spark运行在YARN上
-
- 前言
- 启动Hadoop集群
- 配置Spark运行在YARN上
- 使用spark-submit提交代码
- 结束语
《PySpark大数据分析实战》-12.Spark on YARN配置Spark运行在YARN上
前言
大家好!今天为大家分享的是《PySpark大数据分析实战》第2章第4节的内容:Spark on YARN配置Spark运行在YARN上。
启动Hadoop集群
在node1上执行集群启动命令启动Hadoop集群,包括HDFS和YARN。Hadoop集群启动命令如下:
$ start-all.sh
Hadoop集群启动后各个节点的进程信息如图所示。

对于HDFS,每个节点都是DataNode,node1是NameNode;对于YARN资源调度框架,每个节点都是NodeManager,node1是ResourceManager。Spark集群不需要启动,节点的进程中看不到任何Spark相关的进程。
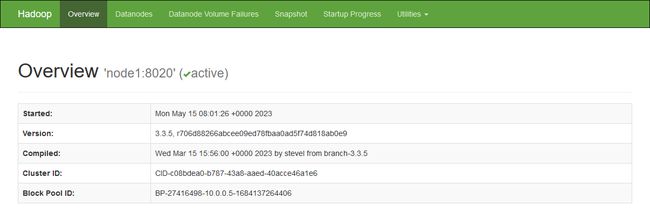
Hadoop 3中HDFS的Web端口默认是9870,通过浏览器访问该端口可以打开Web界面,了解集群的概览信息,如图所示。
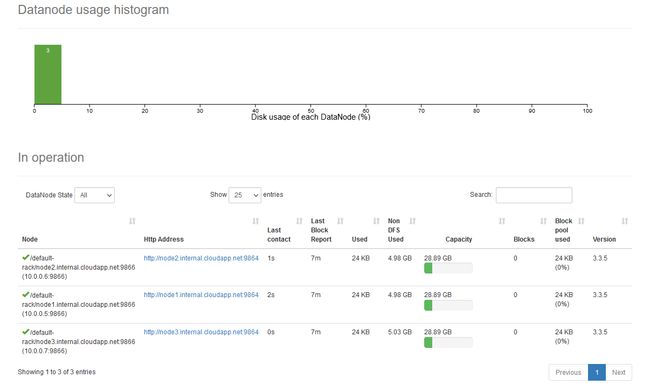
在Web界面的Datanodes页面,列出了集群的DataNode列表,如图所示。
在服务器上通过hdfs命令将words.txt文件上传到HDFS,命令如下:
$ hdfs dfs -put words.txt /
文件上传成功后,通过Web界面浏览HDFS的文件,如图所示。

Hadoop 3中YARN的Web端口默认是8088,通过浏览器访问该端口可以查看YARN的信息,YARN集群信息如图所示。

配置Spark运行在YARN上
Spark on YARN是不需要启动Spark的,所以Spark的配置大多数都是可以省略的,但是需要配置告诉Spark在哪里去寻找YARN,所以需要配置spark-env.sh,为Spark配置HADOOP_CONF_DIR和YARN_CONF_DIR。需要保证在集群的每个节点上这个配置保持同步,可以在每个节点单独配置,也可以在一个节点上配置完成后同步到其他节点。spark-env.sh配置命令如下:
$ vi $SPARK_HOME/conf/spark-env.sh
spark-env.sh配置内容如下:
HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-3.3.5/etc/hadoop
YARN_CONF_DIR=/home/hadoop/apps/hadoop-3.3.5/etc/hadoop
使用spark-submit提交代码
words.txt已经上传到HDFS,在Spark应用程序中可以访问HDFS上的文件,修改脚本/home/hadoop/WordCount.py,读取HDFS上的文件。修改后WordCount.py的代码如下:
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("WordCount")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
# 通过SparkContext对象读取文件
fileRdd = sc.textFile("hdfs://node1:8020/words.txt")
# 将文件中的每一行按照空格拆分成单词
wordsRdd = fileRdd.flatMap(lambda line: line.split(" "))
# 将每一个单词转换为元组,
wordRdd = wordsRdd.map(lambda x: (x, 1))
# 根据元组的key分组,将value相加
resultRdd = wordRdd.reduceByKey(lambda a, b: a + b)
# 将结果收集到Driver并打印输出
print(resultRdd.collect())
使用spark-submit命令,指定master是yarn,提交代码进行运行,命令如下:
$ spark-submit --master yarn WordCount.py
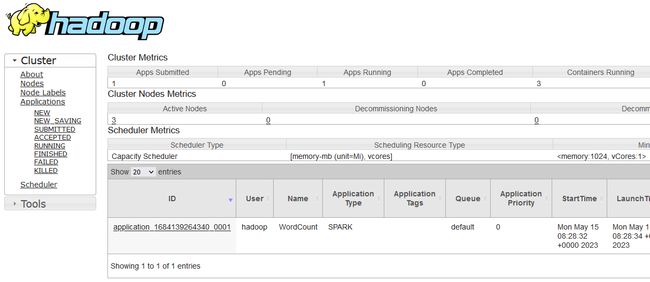
在YARN的Web界面,Applications菜单下,可以看到提交运行的Spark应用程序,如图所示。
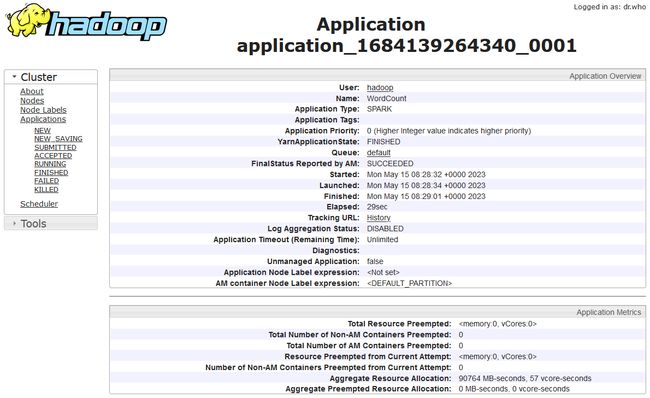
在列表中点击应用ID链接,可以查看应用程序执行的详细信息,如图所示。
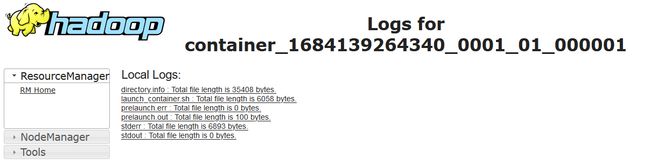
在详情页面底部的列表中点击Logs链接,可以查看应用程序运行日志等信息,如图所示。
结束语
好了,感谢大家的关注,今天就分享到这里了,更多详细内容,请阅读原书或持续关注专栏。