selenium+xpath爬取二手房标题
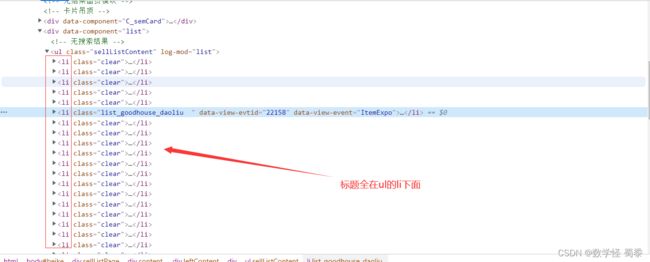
贝壳找房标题爬取需要注意的是,在页面中间有一个小广告
而他就在ul的li下面,当我们进行title所以输出时,会报错。
所以在进行页面解析之前必须把广告叉掉,不然也把广告那一部分的li给爬取下来了
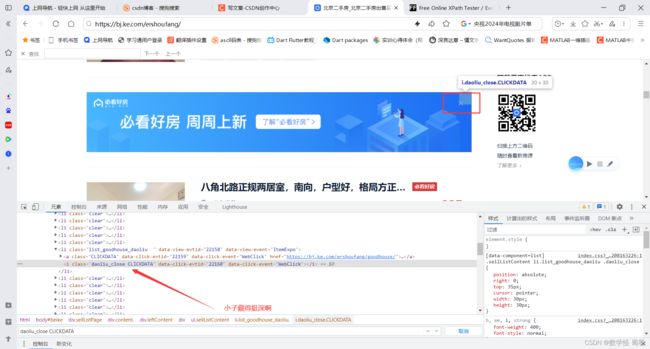
所以,我们,定位到上面箭头那里,进行 x掉,也就是利用click事件进行处理
然后第二个就是当进行下一页时,url会更换
所以当我们要第23456……页时,必须刷新新的url
(如果换页时,url没变的情况下,则只需元素定位到下一页的按钮进行click事件处理即可)。
要注意的就是以上那么多,代码如下
from selenium import webdriver
from lxml import etree
from selenium.webdriver.common.by import By
from time import sleep
from selenium.webdriver import ChromeOptions
cho=ChromeOptions()
cho.add_experimental_option('excludeSwitches',['enable-automation'])
#浏览器驱动
bro=webdriver.Chrome(options=cho)
sleep(1)
all_page=[]
for i in range(5):
bro.get(f'https://bj.ke.com/ershoufang/pg{i+1}/')
# 睡个两秒,防止页面没有加载完成
sleep(2)
#把广告去掉,因为广告是ul下的一个li。
bro.find_element(By.CLASS_NAME,'daoliu_close').click()
#点击后进行解析,并且放进列表里面
all_page.append(bro.page_source)
print(f'已经把第{i+1}页HTML内容放入列表中')
print('--------------------------------------------------------------------------------------------------------------')
s=1
#页面列表循环遍历进行解析。
for page in all_page:
tree=etree.HTML(page)
#睡个两秒,防止页面没有加载完成
sleep(2)
li_list=tree.xpath('/html/body/div[1]/div[4]/div[1]/div[4]/ul/li')
#再睡个两秒,防止页面没有加载完成
sleep(2)
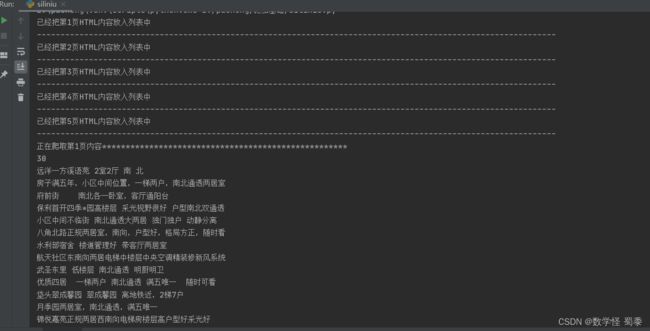
print(f"正在爬取第{s}页内容****************************************************")
sleep(1)
#打印测试有没有空元素
print(len(li_list))
for dl in li_list:
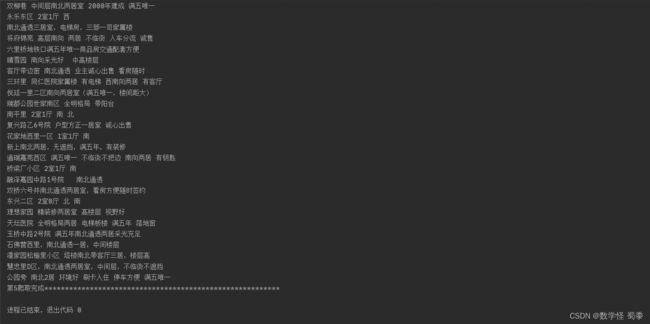
title=dl.xpath('./a/@title')[0]#@title只有一个所以【0】就行
print(title)
print(f'第{s}爬取完成*********************************************************')
s=s+1
sleep(1)
sleep(2)
bro.quit()