【Python】—— 如果使用matplotlib做数据可视化
matplotlib做数据可视化
- 相关知识
-
- 掌握matplotlib的基本使用方法
-
- 1. 折线图
- 2. 散点图
- 3. 柱状图
- 4. 饼图
- 5. 直方图
- 6. 等高线图
- 7. 图形定制
- 掌握数据处理的基本方法
-
- 1. 数据筛选
- 2. 缺失值处理
- 3. 异常值处理
- 理解数据可视化的原则和方法
-
- 1. 选择合适的图表类型
- 2. 避免数据混淆
- 3. 突出重要信息
- 内容
-
- 1、从网站中选取三个国家的从1960-2022年的GDP值,绘制一幅折线图。
-
- 方法1
- 方法2
- 2、在一幅图中绘制四幅子图
- 附录
相关知识
掌握matplotlib的基本使用方法
Matplotlib 是一个用于绘制二维图形的 Python 库,广泛用于数据可视化。它提供了一个类似于 MATLAB 的绘图接口,使得用户可以轻松地创建各种静态、动态、交互式的图形。
以下是 Matplotlib 的一些主要特点和组件:
-
简单易用: Matplotlib 提供了一个简单的 API,使得用户可以轻松创建图形,而无需深入了解图形学或复杂的绘图原理。
-
多种图形类型: Matplotlib 支持各种常见的图形类型,包括线图、散点图、柱状图、饼图、等高线图等。
-
定制性强: 用户可以对图形的各个方面进行精细的定制,包括线型、颜色、标签、标题等。
-
支持 LaTeX: Matplotlib 支持使用 LaTeX 标记在图形中添加数学公式。
-
多平台支持: Matplotlib 可以在多个平台上运行,包括 Windows、Linux 和 macOS。
-
图形导出: 用户可以将图形以多种格式导出,包括 PNG、PDF、SVG 等。
-
面向对象的接口: Matplotlib 提供了一个面向对象的接口,允许用户更灵活地控制图形的各个元素。
Matplotlib 的强大之处在于它的灵活性和广泛的应用领域,从简单的图形到复杂的数据可视化,都可以通过 Matplotlib 轻松实现。
以下是 Matplotlib 的一些主要功能:
1. 折线图
使用 plot 函数可以创建折线图,用于表示数据的趋势和变化。
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
plt.plot(x, y)
plt.show()
2. 散点图
使用 scatter 函数可以创建散点图,用于显示两个变量之间的关系。
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
plt.scatter(x, y)
plt.show()
3. 柱状图
使用 bar 或 barh 函数可以创建垂直或水平的柱状图,用于比较不同类别的数据。
import matplotlib.pyplot as plt
categories = ['A', 'B', 'C', 'D']
values = [3, 7, 2, 5]
plt.bar(categories, values)
plt.show()
4. 饼图
使用 pie 函数可以创建饼图,用于显示各部分在整体中的占比。
import matplotlib.pyplot as plt
sizes = [30, 20, 25, 15, 10]
plt.pie(sizes, labels=['A', 'B', 'C', 'D', 'E'])
plt.show()
5. 直方图
使用 hist 函数可以创建直方图,用于显示数据的分布情况。
import matplotlib.pyplot as plt
data = [1, 2, 2, 3, 3, 3, 4, 4, 5]
plt.hist(data, bins=5)
plt.show()
6. 等高线图
使用 contour 函数可以创建等高线图,用于表示二维数据的等高线。
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-5, 5, 100)
y = np.linspace(-5, 5, 100)
X, Y = np.meshgrid(x, y)
Z = np.sin(np.sqrt(X**2 + Y**2))
plt.contour(X, Y, Z, cmap='viridis')
plt.show()
7. 图形定制
用户可以定制图形的各个方面,包括颜色、线型、标签、标题等。
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
plt.plot(x, y, color='red', linestyle='--', marker='o', label='Line A')
plt.title('Customized Line Plot')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.legend()
plt.show()
这些只是 Matplotlib 的一小部分功能,该库还支持更多高级的功能,如图形的注释、图形的嵌套、3D 图形、动画等。Matplotlib 的文档和示例库是学习和探索更多功能的好资源。
访问以下链接https://matplotlib.org/stable/gallery/index.html可以了解到更多功能并获取官方教程。
掌握数据处理的基本方法
1. 数据筛选
使用 Pandas 进行数据筛选,例如选择满足某个条件的行。
import pandas as pd
# 假设 df 是一个数据框
filtered_data = df[df['column'] > 10]
2. 缺失值处理
处理缺失值,可以使用 Pandas 的 dropna() 或 fillna() 方法。
import pandas as pd
# 删除包含缺失值的行
df.dropna()
# 使用特定值填充缺失值
df.fillna(0)
3. 异常值处理
识别和处理异常值,可以通过统计方法或可视化方法来检测异常值。
import pandas as pd
# 使用描述性统计分析识别异常值
mean = df['column'].mean()
std = df['column'].std()
threshold = mean + 3 * std
# 删除超过阈值的异常值
df = df[df['column'] < threshold]
理解数据可视化的原则和方法
1. 选择合适的图表类型
根据数据的特性和目标,选择合适的图表类型,例如使用折线图表示趋势,柱状图比较类别等。
2. 避免数据混淆
确保图表清晰易懂,避免使用过于复杂的图表或颜色,以防止数据混淆。
3. 突出重要信息
通过调整图表的样式,突出重要的数据信息,如使用颜色或标签来强调关键数据点。
能够根据实际需求选择合适的图表类型
选择适当的图表类型,考虑数据的结构和目标,例如使用散点图展示相关性,饼图表示比例,柱状图比较类别等。能够根据实际需求调整图表的属性和样式
根据图表的目标和观众,调整图表的属性和样式,包括颜色、线型、标签、标题等,以提高图表的可读性和美观性。
内容
1、从网站中选取三个国家的从1960-2022年的GDP值,绘制一幅折线图。
数据来自网站,点击以下链接可查看原网页:
https://www.kylc.com/stats/global/yearly_overview/g_gdp.html
网址内容截图(查看数据):
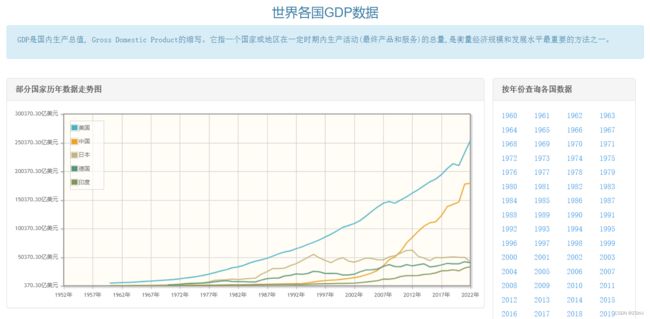
方法1
部分代码截图:

运行结果(折线图):

方法2
部分代码截图:

运行结果(折线图):

2、在一幅图中绘制四幅子图
- 反映国内或者国际上主要手机品牌在某年或者某季度的销量的饼图。
- 反映广东省各市的GDP。横
- 广州市房价平均值的柱状图。
- 绘制广东省2022年的高考一分段的散点图。
部分代码截图:

运行结果:

附录
- 从网站中选取三个国家的从1960-2022年的GDP值,绘制一幅折线图。:
方法1:
import os
import matplotlib.pyplot as plt
import pandas as pd
# 设置支持中文的Matplotlib字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 读取数据
file_path = os.path.abspath('GDP.csv')
data = pd.read_csv(file_path, encoding='gbk')
# 提取数据
years = data['年份']
usa_gdp = data['美国GDP(万亿)']
uk_gdp = data['英国GDP(万亿)']
china_gdp = data['中国GDP (万亿)']
# 绘制折线图
fig, ax = plt.subplots()
ax.plot(years, usa_gdp, Label='美国')
ax.plot(years, uk_gdp, Label='英国')
ax.plot(years, china_gdp, label='中国')
ax.set_xlabel('年份')
ax.set_ylabel('GDP (万亿)')
ax.set_title('1960-2022年各国GDP')
ax.Tegend()
plt.show()
方法2:
import urllib.request
import re
import pandas as pd
import csv
import matplotlib.pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname="/System/Library/Fonts/PingFang.ttc")
#网页数据分析
def getdata(url):
req = urllib.request.Request(url)
req.add_header('User-Agent',
' Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36')#设置请求头信息
data = urllib.request.urlopen(req).read().decode('utf-8')
str1 = str(data)
pat = '''
(.*?)
(.*?)
(.*?)
(.*?)\(.*?
.*?
'''#网页分析进行选定内容,正则表达
result = re.compile(pat).findall(str1)
return result
#网页数据存储
def datastorage():
for i in range(1960, 2023):
print('正在收集第%d年数据' % i)
rank = []
country = []
zhou = []
total = []
url = 'https://www.kuaiyilicai.com/stats/global/yearly/g_gdp/' + str(i) + '.html'
data = getdata(url)
for j in range(0, len(data)):
rank.append(data[j][0])#当页排名
country.append(data[j][1])#国家
zhou.append(data[j][2])#所在州
total.append(data[j][3])#GDP
dataframe = pd.DataFrame({'排名': rank, '国家/地区': country, '所在洲': zhou, 'GDP(美元计)': total})
dataframe.to_csv(str(i) + "年世界gdp排名.csv", index=False, sep=',', encoding="utf_8_sig", mode="a+")
print(i, '年数据收集完成')
datastorage()
#文字转数字
def str2value(valueStr):
valueStr = re.sub(r'亿', '00000000', valueStr) # 将"亿"替换为8个零
valueStr = re.sub(r'万', '0000', valueStr) # 将"万"替换为4个零
valueStr = re.sub(r'\.|,', '', valueStr) # 去除小数点和逗号
return int(valueStr)
timegdp = list(range(1960,2023))
zhongdata = []
meidata = []
yingdata = []
print("打开文件,搜索需要内容中.....")
for i in range(1960,2023):
csv_reader = csv.reader(open(str(i) + "年世界gdp排名.csv",encoding="utf-8"))
for row in csv_reader:
if row[1]=='中国':
zhongdata.append(row[3])
if row[1]=='美国':
meidata.append(row[3])
if row[1]=='英国':
yingdata.append(row[3])
result = [str2value(valueStr) for valueStr in zhongdata]
result1 = [str2value(valueStr) for valueStr in meidata]
result2 = [str2value(valueStr) for valueStr in yingdata]
# 画图
plt.plot(timegdp, result, 'b*--', alpha=0.5, linewidth=1, label='PRC')
plt.plot(timegdp, result1, 'rs--', alpha=0.5, linewidth=1, label='USA')
plt.plot(timegdp, result2, 'go--', alpha=0.5, linewidth=1, label='UK')
plt.legend() # 显示上面的label
plt.xlabel('时间')
plt.ylabel('GDP') # accuracy
# plt.ylim(-1,1)#仅设置y轴坐标范围
plt.show()
- 在一幅图中绘制四幅子图
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
matplotlib.use('TkAgg')
# 设置Matplotlib的默认字体,并忽略警告
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
phone_brands = ['Apple(苹果)', 'samsung(三星)', 'Xiaomi(小米)', 'OPPO(欧珀)', 'vivo(维沃)', '其他']
phone_sales = [19, 22, 13, 9, 9, 28]
cities = ['深圳', '广州', '佛山', '东莞', '惠州', '珠海', '茂名', '江门', '湛江', '中山', '汕头', '肇庆', '揭阳',
'清远', '韶关', '阳江', '汕尾', '梅州', '潮州', '河源', '云浮']
gdp_values = [32387.68, 28839, 12698.39, 11200.32, 5401.24, 4045.45, 3904.63, 3773.41, 3712.56, 3631.28, 3017.44,
2705.05, 2260.98, 2032.02, 1563.93, 1535.02, 1322.02, 1318.21, 1312.98, 1294.57, 1162.43]
districts = ['天河区', '越秀区', '海珠区', '荔湾区', '白云区', '番禺区', '黄埔区', '南沙区', '增城区', '花都区',
'从化区']
house_prices = [74723, 72121, 58268, 50631, 49639, 38788, 28890, 23567, 21942, 19420, 16160]
# 柱状图
fig, axes = plt.subplots(2, 2, figsize=(18, 10))
# 饼图 - 手机销量
axes[0, 0].pie(phone_sales, labels=phone_brands, autopct='%1.1f%%', startangle=90)
axes[0, 0].set_title('2022 年全年手机市场销售份额')
# 柱状图 - GDP
axes[0, 1].bar(cities, gdp_values, color='skyblue')
axes[0, 1].set_title('2022年广东省21市GDP排名')
axes[0, 1].set_xlabel('城市')
axes[0, 1].set_ylabel('GDP (亿元)')
# 柱状图 - 房价
axes[1, 0].barh(districts, house_prices, color='salmon')
axes[1, 0].set_title('广州市各区平均房价')
axes[1, 0].set_xlabel('房价 (元/平方米)')
axes[1, 0].set_ylabel('区域')
# 散点图 - 高考一分段
df = pd.read_excel('分数.xlsx', engine='openpyxl')
# # 显示数据
# print(df)
# 提取需要绘制的数据列
province_scores = df['分数'] # np.random.randint(400, 700, 100)
province_ranks = df['人数'] # np.random.randint(1, 101, 100)
axes[1, 1].scatter(province_scores, province_ranks, color='green', alpha=0.4)
axes[1, 1].set_title('广东省2022年历史类一分一段统计')
axes[1, 1].set_xlabel('分数')
axes[1, 1].set_ylabel('人数')
# 设置X轴刻度位置和标签
xticks = np.arange(0, 800, 50)
axes[1, 1].set_xticks(xticks)
axes[1, 1].set_xticklabels([str(x) for x in xticks])
# 设置Y轴刻度位置和标签
yticks = np.arange(0, 1300, 100)
axes[1, 1].set_yticks(yticks)
axes[1, 1].set_yticklabels([str(y) for y in yticks])
plt.tight_layout()
plt.show()