GPT-2能监督GPT-4,Ilya带头OpenAI超级对齐首篇论文来了:AI对齐AI取得实证结果
来自:机器之心
>快来!NLP论文投稿、LLM交流、论文直播群
人类无法监督超级人工智能,但人工智能可以。
过去一年,以「预测下一个 Token」为本质的大模型已经横扫人类世界的多项任务,展现了人工智能的巨大潜力。
在近日的一次访谈中,OpenAI 首席科学家 Ilya Sutskever 大胆预言,如果模型能够很好地预测下一个词,那么意味着它能够理解导致这个词产生的深刻现实。这意味着,如果 AI 按照现有路径发展下去,也许在不久的将来,一个超越人类的人工智能系统就会诞生。
但更加令人担心的是,「超级人工智能」可能会带来一些意想不到的负面后果。这也是「对齐」的意义。
此前的对齐方法依赖于人类的监督,如在 ChatGPT 训练中起到关键作用的人类反馈的强化学习(RLHF)。但未来的人工智能系统或许能够做出极其复杂和富有创造性的行为,使人类难以对其进行可靠的监督。例如,超人类模型可能会编写出数百万行新奇的、具有潜在危险的计算机代码,即使是人类专家也很难理解这些代码。
一旦人工智能的水平超过人类,我们又该如何监督比自己聪明得多的人工智能系统?人类文明最终会被颠覆甚至摧毁吗?
即使是 Hinton 这样的学界巨佬,对这个问题同样持悲观态度 —— 他表示自己「从没见过更高智能水平的东西被远远更低智能水平的东西控制的案例」。
刚刚,OpenAI「超级对齐」团队发布了成立以来的首篇论文,声称开辟了对超人类模型进行实证对齐的新研究方向。

论文链接:https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
OpenAI「超级对齐」团队成立于今年 7 月,目标是在四年内解决超智能 AI 的对齐问题,即搞清楚如何构建一种值得信任的人类水平的研究器,然后将其用于解决对齐问题。据说这个团队投入了公司 20% 的算力。
在这篇论文中,OpenAI 对「人类监督超级人工智能」这个问题做了一个简单的类比:让小模型监督大模型。

研究表明,15 亿参数的 GPT-2 模型可以被用来激发 GPT-4 的大部分能力,使其达到接近 GPT-3.5 级别的性能,甚至可以正确地泛化到小模型失败的难题上。
OpenAI 将这种现象称为「弱到强泛化」(Weak-to-strong generalization),这表明强大的模型具备如何执行任务的隐含知识,并且即使在给出粗制滥造的指令时也可以在其自身中找到这些知识。
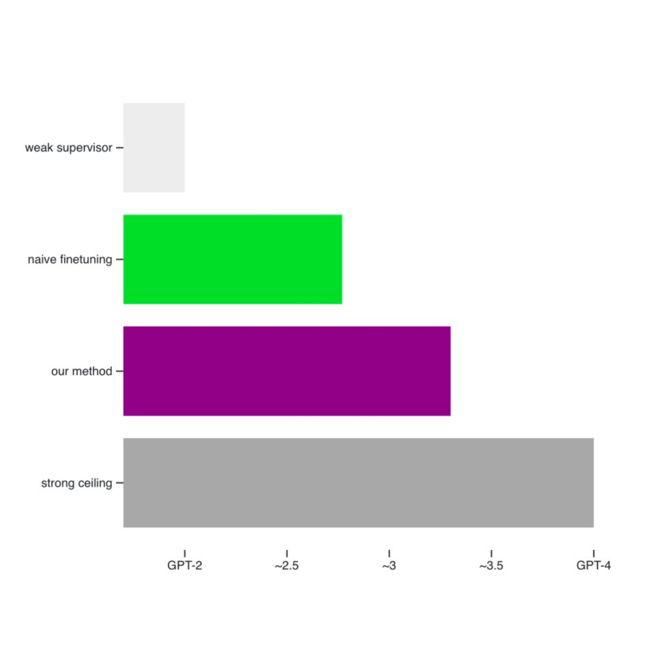
但研究同时指出,用弱监督训练的强模型和用真实标签训练的强模型之间仍然存在很大的差距。这表明在没有额外工作的情况下,诸如基于人类反馈的强化学习(RLHF)之类的技术可能无法很好地扩展到超人类模型。对于 ChatGPT 奖励建模任务来说,性能差距尤其大。
几种简单的方法可以显著提高弱到强的泛化能力,比如使用中间模型大小进行引导监督,在微调时添加辅助置信度损失以鼓励模型即使在与弱标签相矛盾时也能保持自信,或者通过额外的无监督预训练改进表征学习。
为了鼓励其他研究人员解决此类问题,OpenAI 今天还宣布将提供 1000 万美元的资助,用于各种比对方法的研究。
以下是论文细节。
研究方法
本文主要通过人类反馈 (RLHF) 的强化学习来指导或对齐模型,他们是这样做的:强化评估人员评价高的行为,惩罚评估人员评价低的行为。假如说人类评估者能够准确判断模型行为是好是坏,这种做法非常有效,并且这种方式还是训练如 ChatGPT 等大语言模型的核心部分。
然而问题来了,超级模型可能做出人类无法完全理解的复杂行为和创造性行为。例如,一个超级助手模型生成的代码达到一百万行,那么人类将无法为关键对齐相关任务提供可靠的监督,包括代码是否遵循用户的意图,助手模型是否如实地回答有关代码的问题,代码执行是否安全或危险,等等。
因此,如果我们在人类的监督下微调超级模型,我们无法确定这个模型将如何泛化到那些人类自己也难以可靠监督的复杂行为。换句话说,这意味着即使在人类的指导下,这些超级模型在处理一些复杂或未知情况时的表现仍然是不确定的。
这就为对齐超级模型带来了挑战:不那么聪明的监督者怎么能控制比他们聪明得多的模型呢?尽管这个问题很重要,但目前很难进行实证研究。
一般来讲,超级对齐的一个核心挑战是人类需要监督比自己更聪明地模型。这是一个弱 - 强(weak-to-strong)的学习问题:一个弱监督者如何监督一个比它聪明得多的模型?为了解决这个问题,本文提出了一个简单的类比,用弱模型作为监督者来代替较弱的人类监督者。
一般来讲,传统的机器学习侧重于这种设置,即人类监督的模型比人类弱。但对于最终的超级对齐问题,人类监督的模型比他们聪明。因而本文研究了一个类似的问题:使用弱模型来监督强模型。
他们是这样实现的,对于一个给定的任务:
构建弱监督者。本文通过在真值标签上微调较小的预训练模型来构造弱监督者,他们把弱监督者的表现称为弱表现,并通过弱模型的预测来生成弱标签。
通过弱监督训练强学生模型。本文使用生成的弱标签微调强模型,并将该模型称为强学生模型,将其产生的性能称为从弱到强的性能。
训练一个以真值标签为上限的强模型。为了比较,本文使用真值标签对强模型进行了微调。将此模型的最终性能称为强大的上限性能。
通常,弱到强的表现将介于弱表现和强上限表现(strong ceiling)之间。本文将 PGR(performance gap recovered)定义为上述三种性能(弱、弱到强和强上限)的函数,如下图所示。

如果实现完美的弱到强泛化,则 PGR 为 1。如果弱到强模型的表现并不比弱监督者更好,则 PGR 为 0。
实验结果
在 NLP 任务、国际象棋和奖励建模任务中,本文评估了强学生模型的表现,结果如下。总的来说,在所有的设置中,本文观察到从弱到强的泛化:强学生模型始终胜过他们的弱监督者。

本文发现可以使用简单的方法来大大提高弱到强的泛化,如图 4 所示。

图 5 表明,对于较小的强学生来说,虽然它的表现比 naive 基线稍差,但提高泛化能力还是很明显的。

图 7 (a) 显示了 ChatGPT RM 任务训练过程中的真值测试准确度曲线,图 7 (b) 和 (c) 比较了最佳和最终真值测试的准确度。

图 9a 考虑了 7 个有代表性的 NLP 任务,并比较了微调、零样本提示和 5-shot 提示;对于零样本和 5-shot 基线,本文使用表 2 中总结的特定于任务的提示。

了解更多内容,请参考原论文。
公众号后台回复aaai、acl、naacl直接进投稿群~
回复LLM进入技术交流群~
回复 nice 进入每周论文直播分享群~
