Clickhouse MergeTree分区原理
1. MergeTree简介
MergerTree(及其家族)是Clickhouse最强大的表引擎。发生insert操作时,MergeTree以数据片段的方式快速写入数据,后台线程会定期以一定规则对数据片段进行Merge。在大数据场景中,相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。更多介绍可以详见官网。
2. MergeTree创建
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
其中各参数的含义和用法官网有详细的介绍,本文就不赘述了。以之前博客经常用到的启动时长测试表为例,创建一个简单的MergeTree引擎表并插入一些数据。
-- 建表
CREATE TABLE test
(
`t_date` Date,
`t_device_id` String,
`app_name` String,
`package_name` String,
`launch_time` UInt32
)ENGINE = MergeTree
ORDER BY `t_date`
PARTITION BY `t_date`;
-- 插入数据
insert into test values('2022-01-01','D0001','launcher','com.android.launcher',1658),
('2022-01-01','D0002','setting','com.android.settings',2005),
('2022-01-02','D0003','','com.google.setupwizard',1052),
('2022-01-03','D0003','launcher','com.android.launcher',1360),
('2022-01-03','D0004','setting','com.android.settings',0),
('2022-01-03','D0004','','com.google.setupwizard',1357),
('2022-01-04','D0005','qq','com.tencent.qq',1698);
-- 查询
select * from test;3. MergeTree的物理结构
建表后进入[clickhouse_home]/data/[database]/[table]目录(我的表直接建在default库,所以路径是/var/lib/clickhouse/data/default/)

4. MergeTree分区
MergeTree之所以叫做MergeTree,是因为它的分区目录是在数据写入的时候,后台进程不断对分区目录进行新增和合并,相同分区的目录会Merge到一起形成一个新的目录。
4.1 分区ID生成规则
| 类型 | 规则 | 样例 | 分区表达式 | 生成分区ID |
| 不指定 | 没有声明PARTITION BY | / | / | all |
| 整型 | 直接按照该整型的字符作为分区ID | 7,15,80 | PARTITION BY age | 分区1:7 分区2:15 分区3:80 |
| ‘A1’,'A2',‘A111’ | PARTITION BY length(code) | 分区1:2 分区2:3 |
||
| 日期 | 按照日期或格式化后的日期值作为分区ID | 2022-02-24,2022-02-25 | PARTITION BY date | 分区1:20220224 分区2:20220225 |
| 2022-01-24,2022-02-25 | PARTITION BY toYYYYMM(date) | 分区1:202201 分区2:202202 |
||
| 其他 | 通过128位hash算法计算分区ID | 'www.baidu.com' | PARTITION BY url | 分区1:dab19e82e1f9a681 |
4.2 分区新增目录的命名

- PartitionID:按照4.1规则生成的分区ID;
- MinBlockNum:从0开始自增,每生成一个分区目录就自增1,发生合并时取相同分区最小的MinBlockNum作为新目录的MinBlockNum;
- MaxBlockNum:从0开始自增,每生成一个分区目录就自增1,发生合并时取相同分区最大的MaxBlockNum作为新目录的MaxBlockNum;
- Level:新增目录level值永远是0,相同分区的数据每次发生合并自增1。
按照上述规则,新增一个目录,则分区目录命名为PartitionID_2_2_0;再新增一个目录则命名为PartitionID_3_3_0,以此类推。
4.3 分区合并目录的命名
前面介绍了分区新增目录的规则,属于同个分区的多个目录合并之后会形成一个新目录,合并目录的命名规则如下:
- PartitionID:按照4.1规则生成的分区ID,拥有相同PartitionID的目录进行合并;
- MinBlockNum:发生合并时取相同分区最小的MinBlockNum作为新目录的MinBlockNum;
- MaxBlockNum:发生合并时取相同分区最大的MaxBlockNum作为新目录的MaxBlockNum;
- Level:从0开始自增,相同分区的数据每次发生合并自增1。
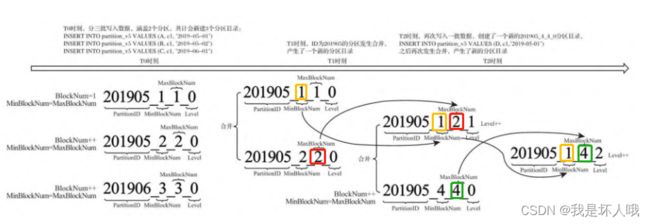
1)T0时刻:写入三组数据,201905_1_1_0和201905_2_2 _0具有相同的PartitionID,后续将对其进行合并。
2)T1时刻:发生合并,取最小的MinBlockNum,即1,作为新目录的MinBlockNum;取最小的MaxBlockNum,即2,作为新目录的MaxBlockNum,发生一次合并,level+1,新目录为201905_1_2_1。
3)T2时刻:新写入一组数据,新增目录201905_4_4_0,按照上述规则再次合并,新目录为201905_1_4_2。
4)合并以后,旧目录会被标识为active=0,等待后续被删除。
5. 参考
Clickhouse官网:MergeTree | ClickHouse Documentation
《Clickhouse原理解析与应用实践》
---------------------------------------------------------------------------------------------------------------------------------
一些无关的题外话:
前几天看到新闻字节28岁程序员猝死,虽然自己一直生活在温室里,工作比较清闲,但是身边不少朋友和同学经常加班到很晚。真心希望,我们可以在工作中发光发热,但是不要过早地燃尽自己的生命。活着,才能感受到阳光的温暖,活着,才有无限可能。