四. 基于环视Camera的BEV感知算法-BEVDet4D
目录
-
- 前言
- 0. 简述
- 1. 算法动机&开创性思路
- 2. 主体结构
- 3. 损失函数
- 4. 性能对比
- 总结
- 下载链接
- 参考
前言
自动驾驶之心推出的《国内首个BVE感知全栈系列学习教程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习下课程第四章——基于环视Camera的BEV感知算法,一起去学习下 BEVDet4D 感知算法
课程大纲可以看下面的思维导图
0. 简述
本节内容我们和大家一起学习一下另外一篇 BEV 感知算法叫 BEVDet4D,我们在 4.6 节中已经和大家一起学习过 BEVDet,从标题上看 BEVDet4D 是 BEVDet 的延续。那 BEVDet4D 有什么额外信息的增加呢,它额外用了什么信息呢,也就是这里的 4D,那我们说 4D 是什么呢,其实就是四维信息,那么除了空间中的三维以外还增加了什么维度呢,时序维度,那也就是题目中提到的 Temporal cues,时序线索
我们还是从以下四个方面展开,算法动机&开创性思路、主体结构、损失函数以及性能对比
1. 算法动机&开创性思路
我们在讨论 BEVDet4D 的算法动机之前我们还是一起先复习下 BEVDet,BEVDet 的框图如下所示:

那 BEVDet 的输入是一个 Multi-view Images 是一个多视角的图像,那对于 nuScenes 数据集而言,视角个数是 6,输出是 3D 检测结果
那 BEVDet 主要由四个模块组成,一个图像编码器 Image-view Encoder 用来处理多视角图像,通过 Encoder 可以得到多视角图像特征,图像 Encoder 是怎么做呢,由 Backbone 网络和多尺度特征融合网络构成。那 View Transformer 又是什么呢,是从 2D 到 3D 的转换器,图像特征从 2D 映射到 3D 再映射到 BEV 空间我们就可以得到所谓的 Camera BEV Features,而 BEV Encoder 是用来对我们前面提取到的 BEV 特征做进一步的编码,所以它的结构与前面的图像编码器是很相似的,也是由 Backbone 网络和 Neck 网络组成。它们的区别在哪呢,在输入不一样,BEV Encoder 的输入是 BEV Feature,Image-view Encoder 的输入是我们的输入图像,通过 BEV Encoder 之后可以得到用于特定任务的特征,那比如说我们要做 3D 检测任务,我们就是得到了利用 3D 检测 Head 完成 3D 目标检测任务
那除此之外呢像 BEVDet 还考虑了一些很细节的问题,那比如说考虑了过拟合问题,为什么产生过拟合呢,因为 BEV Encoder 的输入是一个 BEV Feature,而前面图像编码器的输入是 6 张图像,是 N 张图像,所以说数量上的不一致导致 BEV Encoder 和图像的 Encoder 两个之间产生了数据量上的差异,因此导致了 BEV Encoder 和 Image-view Encoder 训练出的网络能力不太一样,BEV Encoder 容易陷入过拟合的问题
那此外还考虑什么呢,还考虑 Scale-NMS,我们在上节课中讲过,BEVDet 通过尺度缩放来进一步优化后处理模块的性能
![]()

那 BEVDet4D 相比 BEVDet 什么增加呢,很明显的从图中我们能看到时间信息,T-1,T,T+1 其实都是时序信息,网络输入发生了改变从原本的单一时刻输入变成了时序输入。那网络模块有变化吗,我们从上图中可以看到网络分成几个部分呢,图像编码器,视角转换模块,BEV 编码器和一个检测头,那从模块上看和 BEVDet 有没有什么变化,它的主体模块其实完全没有变化,那么所以针对不同时间的图像输入它考虑的问题是我们怎么利用得到的不同时序的 BEV 特征
所以图中对时序特征模块是做了额外的突出的,我们从图中能看到颜色很深的地方是时序信息的使用样例,图中黄色的特征图是 T-1 和 T 时刻的 BEV 特征,那依此类推后面还有 T+1 时刻的,T+2 时刻的等等。那 T-1 时刻的 BEV 特征和 T 时刻的 BEV 特征能直接相加吗?那显然是不能直接相加的
因为两个时间的 BEV 特征在空间上是没有对齐的,我们说的 BEV 空间是以车辆为坐标原点建立的,由于车辆的运动导致两张特征图在空间上是没有对齐的,空间位置是存在偏差的,那所以直接相加合理吗,肯定不合理,会产生空间位置的错位,所以说要融合多时间的 BEV 特征第一步要做什么,要做对齐
首先需要把 T-1 时刻的 BEV 特征和 T 时刻的 BEV 特征对齐,那么这种对齐呢我们可以理解成空间层面的对齐,是空间位置的对齐,那在对齐完之后我们有了一个空间对准后的特征,它是一个比较好的特征,是可以用于后续检测任务
所以从动机的角度来讲它增加了额外的时序信息,那既然增加了时序所以就要考虑怎么样才是多帧融合合理的方式,是直接相加吗,显然是不行的,要先做对齐然后再级联
那 OK 说完了算法动机我们来看看网络的主体结构是什么
2. 主体结构
BEVDet4D 的主体结构如下:
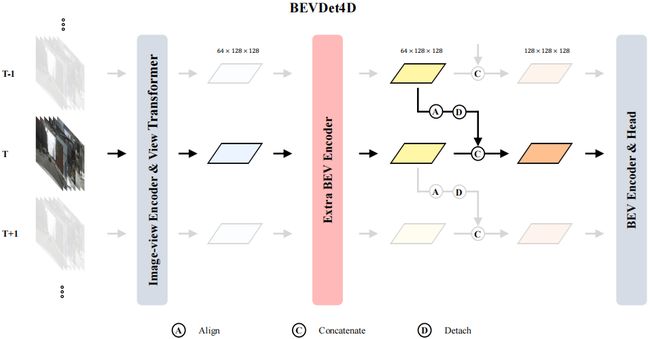
我们其实在动机部分已经把网络主体结构阐述得比较清楚了,BEVDet4D 既然是 BEVDet 的延伸版,我们说它额外引入了什么呢,引入了时序信息,那 OK 如果我们先不考虑时序信息也就是说对于 T 时刻而言输入是一个多视角图像,它怎么得到 BEV 特征呢,通过我们每节课都要讲的图像编码、视角转换、BEV Encoder 等等,我们可以得到 T 时刻也就是说单一时刻的 BEV 特征,那在 T 时刻下得到 BEV 特征的方式与 BEVDet 是一样的,沿用的也是 BEVDet 的方法,所以我们得到了 BEV 特征。T-1 时刻可以得到 BEV 特征,T 时刻也得到 BEV 特征,按照我们动机里讲的不同时刻的 BEV 特征要先做对齐也就是图中的 Align,再做融合,融合后的特征我们认为它不仅包含了当前时刻 BEV 信息还融合了历史时刻的 BEV 信息,所以其实是利用了作者标题中提到的什么,Temporal cues,可以得到更好的检测结果
BEVDet4D 检测核心内容在哪呢,其实是怎么做这个对齐是非常重要的,BEV 只要对齐了后续就非常简单。
OK,另外我们大家来思考一个问题为什么增加时序就可以得到更好的结果呢,时序信息为什么这么重要?可能很多时候大家会觉得这是一个顺理成章的事情,我增加了信息那自然会得到好的结果,那这里还是希望大家可以思考一下为什么时序信息对 3D 检测非常重要,我们讲 BEVFormer 引入了历史 BEV,我们讲 BEVDet4D 引入了时序信息,为什么大家都要这么做。
其实主要原因还是大家认为历史信息是一个非常好的辅助数据,历史帧的信息可以对当前帧起到比较好的辅助作用,那比如什么呢,车辆朝向、车辆运行速度等等,通俗讲的那就是比如历史帧中我们可以知道车是按正前方这个方向行驶的,那么在当前帧当中同样的一辆车很大概率也是按同一方向运行的,那所以这就给我们的检测提供了非常强的先验信息
所以我们说时序是一个非常有用的东西,那既然 BEVDet4D 的核心是引入了时序信息,我们就来看看它的时序对齐是怎么做的

上图列出的是 BEVDet4D 时序对齐模块,我们可能乍一眼看眼花缭乱的,我们不要着急,我们一个一个看,我们从头开始
首先 O g O_g Og 是什么,是坐标系,什么坐标系呢,全局坐标系,下面的角标 g g g 叫做 global 是一个全局坐标,全局坐标什么意思呢,世界坐标。那比如我们在上海我们的经纬度是多少,在北京我们的经纬度是多少,是一个世界坐标
那么还有什么坐标系呢,我们还能看到 O e O_e Oe, O e O_e Oe 是什么坐标呢,它叫 Ego Vehicle 自车坐标系,那可能自车这个词大家觉得有点奇怪,它其实就是我们说的自动驾驶车辆,输入图像输入点云的来源是哪,是自车提供的,那所以 O e O_e Oe 我们叫自车坐标
我们还能看到什么呢, O s O_s Os 和 O m O_m Om,它们俩是我们车辆周围的物体,像 O s O_s Os 我们叫静止车辆也就是路边会停留的车,像 O m O_m Om 叫运动车辆也就是路边上运动的车辆
看完了这些我们再来看第一张图,那上面有什么呢,有静止车辆是图中绿色的车, O s ( T ) O_s(T) Os(T) 表示 T 时刻的数据, O s ( T − 1 ) O_s(T-1) Os(T−1) 是 T-1 时刻的数据,那我们说它是静止车辆所以 T 时刻和 T-1 时刻它在全局空间坐标系下位置空间是不会产生变化
那还有什么呢,还有 O e O_e Oe, O e O_e Oe 是我们说的这个自动驾驶车辆,那 O e O_e Oe 变了吗,按照作者给出的图例可以发现它是发生了改变的, T T T 时刻是图中红色的车, T − 1 T-1 T−1 时刻也就是 O e O_e Oe 车上一时刻的空间位置,是在 T 时刻后面的,车辆发生了变化,那运动方向是从哪到哪呢,沿着正前方去运动的
还有什么呢,还有 O m O_m Om 我们叫 moving vehicle 运动车辆,那既然是运动车辆 T 时刻和 T-1 时刻它的位置自然是不一样的,所以我们同样能看到 T 时刻和 T-1 时刻两个位置是产生了偏差的
那 OK 我们这里先停一下,先不看后面的图例,我们思考一个问题,我们先简化看下
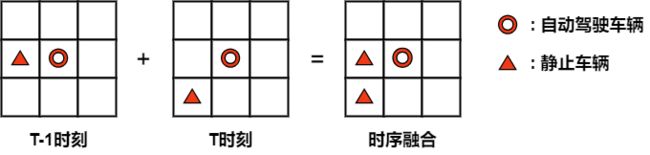
比如我们这里有一个 BEV 空间,一个非常小的 BEV 空间,我们就分成 3x3 的网络,如上图所示。那假设我们自动驾驶车辆在网格中心,那现在我们假设一种情况,T-1 时刻自动驾驶车辆的左侧出现了一个静止车辆,现在我们的自动驾驶车辆从 T-1 时刻运动到了 T 时刻,那是不是我们自动驾驶车辆和静止车辆相对位置就发生了变化,因为我们说静止车辆是不动的,那在 T 时刻静止车辆已经处于我们自动驾驶车辆的一个左后方了,也就是说 T-1 时刻的 BEV 空间静止车辆和自动驾驶车辆相对位置关系是左右的关系,到了 T 时刻相对位置关系已经变成了左后方的关系
如果现在我们把 T 时刻的 BEV 空间和 T-1 时刻的 BEV 空间直接相加会出现什么问题呢,那它会出现两个静止车辆,我们从图中也能看到同样的一个静止车辆在 T 时刻和 T-1 时刻累计完之后会出现在两个不同的位置上,那它其实就是由于空间位置的不匹配所以导致 BEV 特征出错了,这里是给大家一个比较简单的样例

我们再来看一看后续作者提供的样例是什么样的呢,黄色是 T 时刻的 BEV 特征,蓝色是 T-1 时刻的 BEV 特征,如果直接相加出现什么,那图中也提供了很好的范例,出现了两个静止车辆,和我们刚讲的是不是一致。实际情况由于静止车辆在全局坐标系下是没有动的,出现这种结果显然是错误结果。那这种情况不仅仅会出现在静止车辆上,同样对运动车辆也是有偏差的,它实际的运动位置可能并没有图中标注的这么远,那当然上面是错误的范例,是没有做对齐的,我们如果直接做级联会产生的结果
后面第二行后续作者就给出了如果做完空间对齐之后我们再做级联会把上面第一行的影响直接降到最低,我们可以看到后续如果先做 Align 也就是先做对齐然后再做级联我们得到后续的结果,我们可以看到 O s O_s Os 是一个静止车辆, O m O_m Om 是一个运动车辆,在我们融合后的 BEV 上我们的静止车辆有几个呢,只有一个,所以说先做对齐然后做级联是一个比较好的方式,后续作者还进一步尝试用公式来表述这个过程,我们来一起看一下

那我们看到这堆公式可能头都大了,我们先不着急还是慢慢一个一个看, P s e \mathbf{P}_s^e Pse 是什么呢,是静止车辆在自车坐标系中的位置, e e e 我们叫 ego vehicle 表示的是自动驾驶车辆的坐标系, s s s 是静止车辆, P s e ( T ) ( T ) \mathbf{P}_s^{e(T)}(T) Pse(T)(T) 表示 T 时刻静止车辆在自车坐标系下的位置,同理 P s e ( T − 1 ) ( T − 1 ) \mathbf{P}_s^{e(T-1)}(T-1) Pse(T−1)(T−1) 表示 T-1 时刻静止车辆在自车坐标系下的位置
那我们可以思考一下,按照常识推理两个相减出现了什么,那可能有第一种情况如果自车没有动,静止车辆没有动,我们叫敌不动我不动,那这个值应该等于 0,因为二者的相对位置没有发生改变。那如果第二种情况,如果自车运动了然而静止车辆没有动,那么这两个值如果直接相减还等于 0 吗,显然不等于 0,因为相对位置是发生了变化的
OK,我们带着这个理解看一看它等于什么,那我们讲静止车辆它之所以叫静止车辆是从全局坐标也就是世界坐标的角度去看的,参照系是世界坐标系。所以作者把这个位置先转换到世界坐标系下, P s g \mathbf{P}_s^{g} Psg 是静止车辆在世界坐标系下的位置,那如果想把静止车辆在自车坐标系下的位置转换到静止车辆在世界坐标系下的位置我们应该怎么做?应该乘上一个转换矩阵,那这个转换矩阵是从世界坐标系转换到我们自车坐标系的转换矩阵叫 T g e \mathbf{T}_g^{e} Tge,乘上之后, P s e ( T ) ( T ) \mathbf{P}_s^{e(T)}(T) Pse(T)(T) 是等于 T g e ( T ) P s g ( T ) \mathbf{T}_g^{e(T)}\mathbf{P}_s^{g(T)} Tge(T)Psg(T),同理在 T-1 时刻是不是也是一样, P s e ( T − 1 ) ( T − 1 ) \mathbf{P}_s^{e(T-1)}(T-1) Pse(T−1)(T−1) 是我们静止车辆在 T − 1 T-1 T−1 时刻全局坐标系下的位置, T g e ( T − 1 ) \mathbf{T}_g^{e(T-1)} Tge(T−1) 是全局坐标到 T-1 时刻的自车坐标系的转换矩阵,那对于静止车俩而言我们说它是静止的,所以说全局坐标是没有发生变化的,也就是说 P s g ( T ) \mathbf{P}_s^{g}(T) Psg(T) 和 P s g ( T − 1 ) \mathbf{P}_s^{g}(T-1) Psg(T−1) 是相等的
那如果自车也没有发生变化也就是说 e ( T ) e(T) e(T) 和 e ( T − 1 ) e(T-1) e(T−1) 的位置是没有发生变化的,也就是我们第一种情况,如果自车也是没有变的话,前面两个转换矩阵 T g e ( T ) \mathbf{T}_g^{e(T)} Tge(T) 和 T g e ( T − 1 ) \mathbf{T}_g^{e(T-1)} Tge(T−1) 也是相等的,所以两个相减后的值就是 0
那如果我们的自车发生了变化,也就是说两个转换矩阵 T g e ( T ) \mathbf{T}_g^{e(T)} Tge(T) 和 T g e ( T − 1 ) \mathbf{T}_g^{e(T-1)} Tge(T−1) 它们俩不相等,那所以作者就给出了后续的推论,那它怎么做呢,那既然你们俩不等,你们俩差在哪里,差在前面的 T e ( T ) e ( T − 1 ) \mathbf{T}_{e(T)}^{e(T-1)} Te(T)e(T−1) 矩阵上,如果说自车运动那其实我们自车在 T 时刻和 T-1 时刻也有一个转换关系,就用这个 T e ( T ) e ( T − 1 ) \mathbf{T}_{e(T)}^{e(T-1)} Te(T)e(T−1) 矩阵表示
那我们转换到最后一步能发现什么事情呢,对于静止车辆而言 T 时刻和 T-1 时刻在全局坐标位置不变,也就是说 P s g ( T ) \mathbf{P}_s^{g}(T) Psg(T) 和 P s g ( T − 1 ) \mathbf{P}_s^{g}(T-1) Psg(T−1) 它们俩相等,而 T g e ( T ) \mathbf{T}_g^{e(T)} Tge(T) 是一模一样的矩阵所以它们差在哪呢,那也就是在最前面的 T e ( T ) e ( T − 1 ) \mathbf{T}_{e(T)}^{e(T-1)} Te(T)e(T−1) 转换矩阵上,是最前面这个转换矩阵有了影响,所以作者得出一个结论,我们静止车辆相对于自车而言相对位置产生偏差的最主要原因来自于哪呢,来自于自车运动的转换矩阵,我们的自车在 T-1 时刻到 T 时刻产生了运动所以才导致这个公式等于 0
所以要想消除这个影响我们怎么做,如果我们一开始把这个偏差值就给它乘上去是不是就把这个影响消除了,所以作者这里我们可以看到相比于上面的式子,下面的式子乘上了一个 T e ( T − 1 ) e ( T ) \mathbf{T}_{e(T-1)}^{e(T)} Te(T−1)e(T) 再按照上面的公式展开前面的 T e ( T − 1 ) e ( T ) \mathbf{T}_{e(T-1)}^{e(T)} Te(T−1)e(T) 和 T e ( T ) e ( T − 1 ) \mathbf{T}_{e(T)}^{e(T-1)} Te(T)e(T−1) 两项其实就抵消掉了,它们俩一乘结果是 1 相互抵消,所以我们得到了最后的结果,我们认为乘上转换矩阵之后是消除了自车运动影响的结果
那以上其实是公式的推导,从对齐的角度来讲是什么意思,比如还是有两张 BEV 特征图,有一张是 T 时刻的,另外一张是 T-1 时刻的,T 时刻特征如果要融合 T-1 时刻,融合的是哪个位置呢,是对应位置吗,不是,是 T-1 时刻位置乘上转换矩阵之后的位置,乘上转换矩阵之后对应的 T-1 时刻位置,通过这样一个位置关系对应然后得到最终的融合结果
3. 损失函数
我们这里再总结下 BEVDet4D 的总体框架,如下图所示:

我们这里再看看 BEVDet4D 的核心思路是什么呢,通过 BEVDet 初始框架可以得到一系列的 BEV 特征,然后再通过 Align 也就是我们说的对齐操作将前一时刻的 BEV 特征和当前时刻的 BEV 特征进行对齐后然后做级联,接着送入 BEV Encoder 编码加强特征提取,最后再送到 BEV 检测头进行检测
所以损失函数这块没有什么新奇的,是通用的我们检测的损失函数,那主要这个点其实在于对齐的操作
4. 性能对比
OK,说完这些我们再看看性能,BEVDet4D 的作者训练环境是 8 张 3090,它的 batch 是等于 8 的,训练了 20 个 epoch

从主要结果看与 PETR、BEVFormer、DETR3D 相比还是有提升的,那后面它即使是轻量化版本的对比也是比较能打的
我们还是重点关注消融实验部分,我们先看表 3:

作者这里讨论得非常详细,它这里的 Baseline 是一个轻量化版本的 BEVDet,Baseline 的 mAP 是 0.312,那 A 方法是什么呢,是将多帧特征直接级联后的也就是说没有做对齐的。我们刚刚讲如果直接级联会造成什么问题,造成空间上的不匹配,从结果也能看出来 a 方法如果做的是直接级联的话,性能是有所下降的,无论是从 mAP 还是 NDS 来讲性能都是下降的
我们再接着看,如果对齐只考虑平移行不行呢,T 叫平移,如果只考虑自车在空间位置的变化,而不考虑自车运动方向的变换,性能怎么样呢,和 Baseline 相比性能还是有一点点提升的;从 B 到 C 是什么呢,我们看到从 Speed 变到 Offset 其实就是引入了额外的模块,预测目标位置偏移量;从 C 到 D 是引入了 Extra,Extra 是什么意思呢,是额外的 BEV Encoder 的,就是说除了初始的 BEV Encoder 之后又引入了一个额外的 BEV Encoder 去编码融合特征
从 D 到 E 把训练权重修改了一下,从 0.2 变到 1.0;从 E 到 F 又增加了一大块,我们看到有 R 进去了,R 是什么呢,叫做 Rotation 旋转,前面都是只考虑自车平移的,那加入 R 之后又引入了额外的这个自车旋转量。后面增广就很好理解了,我们说图像增广如翻转平移缩放裁剪,那这里作者说的增广就是采样时间跨度的增广,也就是说我们进行时序特征融合之后,历史 BEV 用的是哪帧数据呢,所以这里进行了增广,那这一系列实验做完之后就得到了最终的结果,相比 Baseline 还是有挺大提升的

那表 5 中作者做了个什么事情呢,是对 BEV Encoder 进行了讨论,时序融合在哪做呢,有 befor 的,有 after 的,我们时序融合在 BEV Encoder 的哪个部分做,作者分别采用了三种方式提供了不同的结果,所以我们其实说 BEVDet4D 的设计在原理上动机上都是非常通俗易懂的,而且作者其实整体思维是非常清晰的,实验也很扎实
那这个工作还是对工程性的支撑比较好的,所以大家感兴趣的可以在 GitHub 实际试用一下,还是非常棒的一个框架,我们对 BEVDet 系列的一个讲解也就到此结束了。
总结
这节课程我们一起学习了 BEVDet 的延续 BEVDet4D,其中的 4D 表示除空间中的三维外它还增加了时序维度,BEVdet4D 本身的网络结构其实并没有发生变化,还是分成了图像编码器、视角转换模块、BEV 编码器和检测头这几个部分,那不同的是 BEVDet4D 作者考虑了利用不同时序的 BEV 特征为后续检测提供更加强烈的先验信息。那不同时序的 BEV 特征直接相加会导致空间位置的偏差,BEVDet4D 的作者考虑的是先对齐然后再级联相加,通过引入自车运动的转换矩阵来抵消静止车辆相对于自车而言的位置偏差,由此完成对两个时刻的特征图进行对齐
OK,以上就是 BEVDet4D 的全部内容了,下节我们学习一篇非常经典的 BEV 感知算法 PETR,敬请期待
下载链接
- 论文下载链接【提取码:6463】
- 数据集下载链接【提取码:data】
参考
- [1] Huang et al. Bevdet4d: Exploit temporal cues in multi-camera 3d object detection