知识图谱之关键实体数据爬取
目录
爬取实体概览
爬取技术介绍
requests_html
Selenium
两者比较
学习路径
代码结构
高可用爬取策略
基于文件记录位点
请求失败指数退避重试
爬取代码
品牌数据
车系数据
车型数据
车型配置数据
代码地址
爬取实体概览
一个品牌有多个车系,一个车系有多个车型,一个车型对应一个车型配置
 实体关系
实体关系
爬取技术介绍
- 本文品牌,车系,车型爬取用到了requests_html
- 本文车型配置爬取用到了Selenium
requests_html
requests_html 是一个 Python 库,它结合了 requests 库的简易性和 BeautifulSoup 的解析能力,用于处理网页内容。它主要用于发送 HTTP 请求,获取网页的 HTML 内容,并对其进行解析
Selenium
Selenium 是一个自动化测试工具,广泛用于 web 应用程序的自动化测试。Selenium WebDriver 允许您使用不同的编程语言(包括 Python)来编写测试脚本,并通过真实的浏览器环境执行这些脚本。
两者比较
-
使用场景:
requests_html更适合于简单或中等复杂度的网页数据抓取,尤其是当页面内容主要是静态的或只涉及有限的 JavaScript 时。Selenium 更适用于需要与网页进行复杂交互或完全模拟浏览器环境的场景。 -
性能:
requests_html在执行速度和资源消耗上通常优于 Selenium,因为它不需要启动一个完整的浏览器实例。 -
功能复杂度:Selenium 提供了更多的功能,能够处理更复杂的场景,但相应的,它的学习曲线也更陡峭。
requests_html对于复杂网页的爬取支持不太完善要完成某个功能需要做出对应的取舍。
学习路径
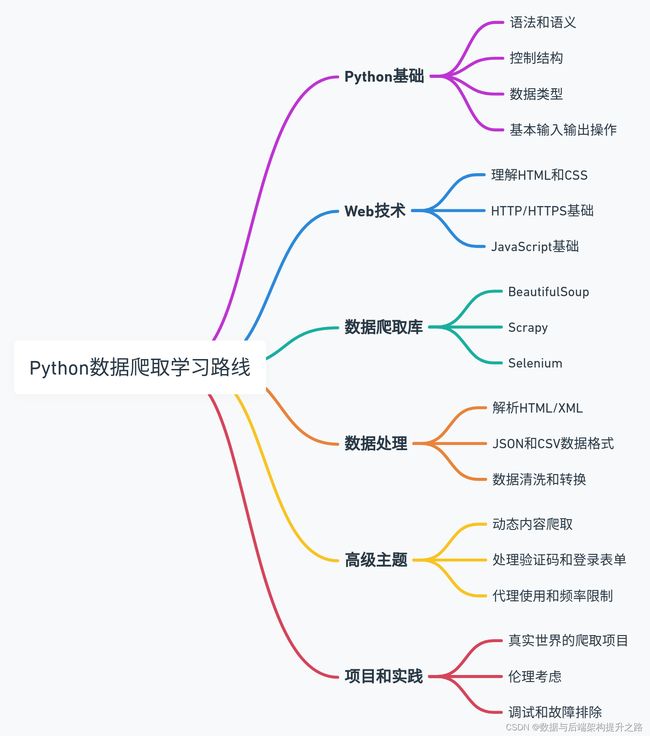 爬虫技术学习路径
爬虫技术学习路径
代码结构