DMFLDR实践
- 导出BOOK_LENDLIST表为lend.txt
- 控制文件lend.ctl
OPTIONS (
MODE='OUT'
CHARACTER_CODE='UTF-8'
LOG='C:\Users\86183\Desktop\lend.log'
)
LOAD DATA
INFILE 'C:\Users\86183\Desktop\lend.txt'
REPLACE
INTO TABLE "LIBRARY"."lend_list"
FIELDS '|'
(
SERNUM,
BOOK_ID,
READER_ID,
LEND_DATE,
BACK_DATE
)
-
- 命令行输入
E:\dmdbms\bin>dmfldr SYSDBA/dzy020131 CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\lend.ctl'
1.3日志输出
dmfldr: 2023-10-23 10:27:37 LIBRARY->lend_list
dmfldr: 2023-10-23 10:28:04 LIBRARY->lend_list export success.
dmfldr: 2023-10-23 10:28:04 LIBRARY->lend_list 7 行数据已导出
用时:8.545(ms)
ENCLOSE BY '"' 表示导出的数据字段用“”扩起
1.4 lend.dat

- 装载数据:dmfldr参数选项DATA指定数据文件
2.1 表结构创建
drop table if exists "LIBRARY"."test";
set SCHEMA LIBRARY;
create table test as select BOOK_ID,READER_ID,LEND_DATE,BACK_DATE from "LIBRARY"."lend_list" where 1<>1;
2.2 控制文件lend2.ctl
LOAD DATA
INFILE * STR X '0A'
REPLACE
INTO TABLE "LIBRARY"."TEST"
FIELDS '|'
(
SERNUM,
BOOK_ID,
READER_ID,
LEND_DATE,
BACK_DATE
)
2.3 命令行输入
E:\dmdbms\bin> dmfldr SYSDBA/dzy020131 CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\lend2.ctl' DATA='C:\Users\86183\Desktop\resource\res\dmfldr\lend.dat' CHARACTER_CODE='UTF-8' LOG='C:\Users\86183\Desktop\resource\res\dmfldr\lend2.log'
2.4 日志输出
dmfldr V8
控制文件:
加载行数:全部
每次提交服务器行数:50000
跳过行数:0
允许错误数:100
是否直接加载:Yes
是否插入自增列:No
数据是否已按照聚集索引排序:No
字符集:UTF-8
数据文件共1个:
C:\Users\86183\Desktop\resource\res\dmfldr\lend.dat
错误文件:fldr.bad
目标表:LIBRARY.TEST
列名
包装数据类型 终止
SERNUM
CHARACTER |
BOOK_ID
CHARACTER |
READER_ID
CHARACTER |
LEND_DATE
CHARACTER |
BACK_DATE
CHARACTER |
行缓冲区数量: 12
任务线程数量: 12
9行记录已提交
目标表:LIBRARY.TEST
load success.
9 行加载成功。
0 行由于数据错误没有加载。
0 行由于数据格式错误被丢弃。
跳过的逻辑记录总数:0
读取的逻辑记录总数:9
拒绝的逻辑记录总数:0
4.050(ms)已使用
2.5 表中数据

- 装载数据:控制文件中指定数据文件路径,带过滤条件
3.1 过滤条件
对于条件过滤的使用需注意以下几点:
1. 判断条件中的操作符'仅支持比较相等和不相等',即=、!=和<>这三个比较操作符;
2. 目前仅支持使用 AND 连接多个过滤条件;
3. BLANKS和WHITESPACE表示若干个空格;
4. 判断条件若使用(p1:p2)作为比较表达式,其意义与在 POSTION 子句中的意义相同,
表示从该行指定位置获取数据进行比较,起始位置和结束位置表示的都是'字节位置',包含边界 p1,p2;
5. 如果判断条件中使用colid作为比较表达式,该列必须在INTO表的coldef_option中进行说明;
6. 如果判断条件中使用colid作为比较表达式,判断条件中使用的列仅用于过滤,并没有对应表中的某个实际列,
应在col_def中指明FILLER属性表示装载时跳过该列;
7. 如果判断条件中比较数据是字符常量值,其长度小于比较表达式长度,则在其之后补充空格;
如果判断条件中比较数据是二进制串常量,其长度小于比较表达式长度,则在之后补充0。
3.2 控制文件lend3.ctl
LOAD DATA
INFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\lend.dat' STR X '0A'
REPLACE
INTO TABLE "LIBRARY"."TEST"
WHEN (1:1) = '2' //这里就是要求每行第一个字节位置的字符要求是字符’1’;
FIELDS '|'
(
SERNUM,
BOOK_ID,
READER_ID,
LEND_DATE,
BACK_DATE
)
3.3 命令行输入
E:\dmdbms\bin>dmfldr SYSDBA/dzy020131 CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\lend3.ctl' CHARACTER_CODE='UTF-8' LOG='C:\Users\86183\Desktop\resource\res\dmfldr\lend3.log' SILENT=true
3.4 日志输出
这里我先采用将字符匹配为首字符为1,则9条数据均未插入成功,在lend3.ctl中将1修改为2则可以成功匹配9条数据。
dmfldr V8
控制文件:
加载行数:全部
每次提交服务器行数:50000
跳过行数:0
允许错误数:100
是否直接加载:Yes
是否插入自增列:No
数据是否已按照聚集索引排序:No
字符集:UTF-8
数据文件共1个:
C:\Users\86183\Desktop\resource\res\dmfldr\lend.dat
错误文件:fldr.bad
目标表:LIBRARY.TEST
列名
包装数据类型 终止
SERNUM
CHARACTER |
BOOK_ID
CHARACTER |
READER_ID
CHARACTER |
LEND_DATE
CHARACTER |
BACK_DATE
CHARACTER |
行缓冲区数量: 12
任务线程数量: 12
9行记录已提交
目标表:LIBRARY.TEST
load success.
9 行加载成功。
0 行由于数据错误没有加载。
0 行由于数据格式错误被丢弃。
跳过的逻辑记录总数:0
读取的逻辑记录总数:9
拒绝的逻辑记录总数:0
4.050(ms)已使用
E:\dmdbms\bin>
E:\dmdbms\bin>dmfldr SYSDBA/dzy020131 CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\lend3.ctl' CHARACTER_CODE='UTF-8' LOG='C:\Users\86183\Desktop\resource\res\dmfldr\lend3.log' SILENT=true
dmfldr V8
目标表:LIBRARY.TEST
load success.
9 行加载成功。
0 行由于数据错误没有加载。
0 行由于数据格式错误被丢弃。
跳过的逻辑记录总数:0
读取的逻辑记录总数:9
拒绝的逻辑记录总数:0
3.757(ms)已使用
E:\dmdbms\bin>dmfldr SYSDBA/dzy020131 CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\lend3.ctl' CHARACTER_CODE='UTF-8' LOG='C:\Users\86183\Desktop\resource\res\dmfldr\lend3.log' SILENT=true
dmfldr V8
目标表:LIBRARY.TEST
load success.
0 行加载成功。
0 行由于数据错误没有加载。
0 行由于数据格式错误被丢弃。
跳过的逻辑记录总数:0
读取的逻辑记录总数:9
拒绝的逻辑记录总数:0
3.159(ms)已使用
3.5表中数据
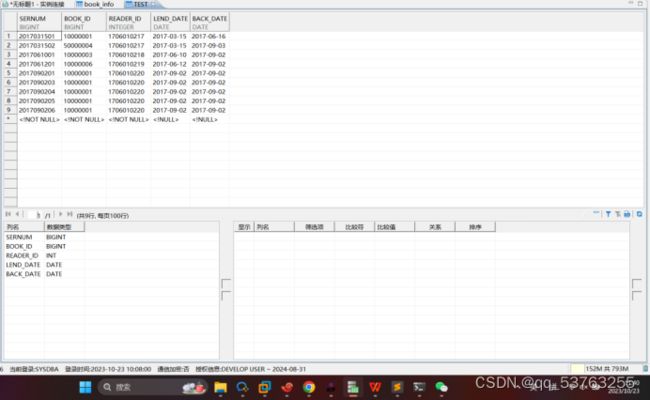
四.多个数据文件装载到同一张表上
4.1 数据准备
# 数据汇总文件:person.txt
C:\Users\86183\Desktop\resource\res\dmfldr\person\person_1.dat
C:\Users\86183\Desktop\resource\res\dmfldr\person\person_2.dat
C:\Users\86183\Desktop\resource\res\dmfldr\person\person_3.dat
# 数据文件1:person_1.dat
11|"张三"|2020-11-24|男|18 70
12|"李四"|2020-11-20|男 |30 70
13|"王五"|2020-11-09|男|22 50
# 数据文件2:person_2.dat
21|"张三2"|2021-04-01|女 |18 60 cn
22|"李四2"|2021-02-10|男|30 (50) cn
23|"王五2"|2021-01-24|女 |22 50 en
# 数据文件3:person_3.dat
31|"张三3"|2021-03-24|女|18 (70) en-us
32|"李四3"|2021-03-24|男|30 (70) en-uk
33|"王五4"|2021-05-24|男 |22 (50) fr-fr
4.2 存储表结构创建
create table person(
id int identity(1,1) primary key,
name varchar(30) not null,
join_date date,
gender varchar(10),
age int check(age between 1 and 150),
description varchar(255) default '大王来巡山',
cons_value varchar(20)
4.3 控制文件lend4.ctl
OPTIONS (
CHARACTER_CODE='UTF-8'
MODE='IN'
DIRECT=TRUE
INDEX_OPTION=1
SET_IDENTITY=TRUE
LOG='C:\Users\86183\Desktop\resource\res\dmfldr\person\person.log'
)
LOAD DATA
INFILE LIST 'C:\Users\86183\Desktop\resource\res\dmfldr\person\person.txt' STR X '0A'
BADFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\person\person.bad'
INTO TABLE LIBRARY.PERSON
WHEN gender = '男'
FIELDS '|'
(
id,
name enclose by '"',
join_date,
gender "trim()",
age terminated by whitespace,
description NULL,
cons_value constant "hello"
)
4.4 命令行输入
E:\dmdbms\bin>dmfldr SYSDBA/dzy020131 CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\person\person.ctl'
4.5 表中数据
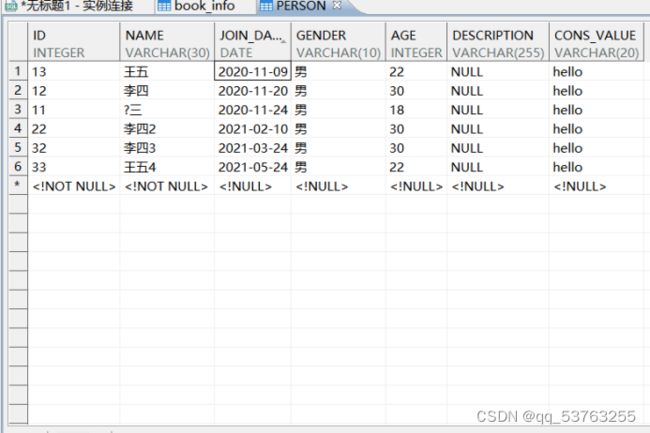
五.多表装载
就是在控制文件中新增多个INTO TABLE字段即可实现同一数据同时装载到多个表中。
5.1 存储表创建
drop table if exists sysdba.job4;
create table job4 as select job_id,job_title from dmhr.job where 1<>1;
drop table if exists sysdba.job5;
create table job5 as select job_id,job_title from dmhr.job where 1<>1;
drop table if exists sysdba.job6;
create table job6 as select min_salary,max_salary from dmhr.job where 1<>1;
5.2 数据文件person2.txt
11|总经理|8000|50000
12|总经理助理|5000|20000
13|秘书|3000|6000
21|行政部经理|5000|10000
22|文员|2500|5000
31|开发部经理|8000|20000
32|项目经理|6000|20000
33|开发工程师|6000|15000
41|市场部经理|5000|20000
42|市场专员|3000|6000
51|技术支持部经理|7000|18000
52|技术支持工程师|4000|12000
61|测试部经理|8000|20000
62|测试工程师|4000|10000
71|人力资源部经理|6000|12000
72|招聘专员|2500|6000
5.3 控制文件person2.ctl
OPTIONS (
CHARACTER_CODE='UTF-8'
LOG='C:\Users\86183\Desktop\resource\res\dmfldr\person2\job_multi.log'
)
LOAD DATA
INFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\person2\person2.txt'
BADFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\person2\person2.bad'
REPLACE
INTO TABLE sysdba.job6
FIELDS '|'
(
a filler,
b filler,
min_salary,
max_salary
)
INTO TABLE sysdba.job5
WHEN (1:1) = '5'
FIELDS '|'
(
job_id position(1:2),
job_title position(4)
)
INTO TABLE sysdba.job4
WHEN (1:1) = '4'
FIELDS '|'
(
job_id position(1:2),
job_title position(4)
)
这里将一份数据,通过增加多个INTO TABLE模块,实现了向多个表装载数据的功能。
- 大字段数据导出
6.1 注意事项
1.达梦数据库支持的大字段数据类型有TEXT、LONGVARCHAR、IMAGE、LONGVARBINARY、BLOB 以及 CLOB。
2.当dmfldr处于导出模式,即MODE为OUT时,dmfldr导出的大字段会放在一个单独文件中,其包含大字段的数据文件名由LOB_FILE_NAME指定。
LOB_FILE_NAME参数默认文件名为dmfldr.lob,文件存放于LOB_DIRECTORY 指定的目录。
如果未指定LOB_DIRECTORY,则存放于指定导出数据文件的同一目录中。
6.2 存储结构创建
declare
v_ch varchar :='';
v_name varchar(20) assign '';
begin
for i in 1..10 loop
set v_ch = REPLICATE(i,1000);
v_name := dbms_random.string('U',10);
execute immediate 'insert into LIBRARY.t_lob(id,name,cb) values(?,?,?);' using i,v_name,v_ch;
end loop;
commit;
end;
6.3 控制文件t_lob.ctl
OPTIONS (
CHARACTER_CODE='UTF-8'
MODE='OUT'
LOG='/dmdata/data/FLDR/t_lob.log'
LOB_DIRECTORY='/dmdata/data/FLDR'
LOB_FILE_NAME='t_lob.lob'
SILENT=TRUE
)
LOAD DATA
INFILE '/dmdata/data/FLDR/t_lob.dat'
REPLACE INTO TABLE sysdba.t_lob
FIELDS '|'
6.4 命令行输入
E:\dmdbms\bin>dmfldr SYSDBA/dzy020131 CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\t_lob\t_lob.ctl'
dmfldr V8
export success.
10 行数据已导出
用时:6.302(ms)
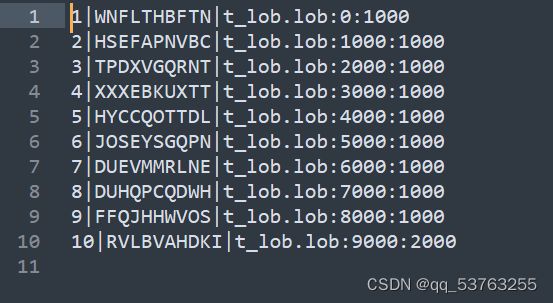
七.大字段数据导入(快速装载)
-
7.1 注意事项
1.DIRECT=TRUE (表示数据传输不通过数据据缓冲区)-快速装载的快速从这里来& MODE=IN,数据装载中涉及大字段对象需手工指定大字段数据文件。
2.CLIENT_LOB=TRUE,LOB_DIRECTORY表示大字段数据文件所在的客户端本地目录。
CLIENT_LOB=FALSE,须先把相关文件传送到达梦数据库服务器所在主库,再使用LOB_DIRECTORY指明存放目录。
3.大字段数据文件在数据文件中指定,可以是任意格式的文件。 在数据文件中,大字段以“文件名:起始偏移:长度”的形式记录在数据文件中。 指定的文件名无效时,dmfldr会报错,装载失败。
对于CLOB类型字段,当指定的偏移、长度范围内带有不完整字符时,dmfldr将装载失败。
7.2 存储结构创建
drop table if exists LIBRARY.t_lob;
create table t_lob (id int, name varchar(20), cc clob);
7.3 控制文件t_lob1.ctl
OPTIONS(
CHARACTER_CODE='UTF-8'
DIRECT=TRUE
MODE='IN'
LOG='C:\Users\86183\Desktop\resource\res\dmfldr\t_lob1\t_lob1.log'
CLIENT_LOB=TRUE
LOB_DIRECTORY='C:\Users\86183\Desktop\resource\res\dmfldr\t_lob1'
LOB_FILE_NAME='t_lob1.lob'
SET_IDENTITY=FALSE
SILENT=TRUE
)
LOAD DATA
INFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\t_lob1\t_lob1.dat'
BADFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\t_lob1\t_lob1.bad'
REPLACE INTO TABLE LIBRARY.t_lob
FIELDS '|'
(
id,
name filler,
cc
)
-
7.4 命令行输入
E:\dmdbms\bin>dmfldr SYSDBA/dzy020131 CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\t_lob1\t_lob1.ctl'
dmfldr V8
目标表:LIBRARY.T_LOB
load success.
10 行加载成功。
0 行由于数据错误没有加载。
0 行由于数据格式错误被丢弃。
跳过的逻辑记录总数:0
读取的逻辑记录总数:10
拒绝的逻辑记录总数:0
5.039(ms)已使用
这里注意文件的命名发生修改之后,.lob文件名改变后.dat文件中也要对应修改,否则报错
7.5 表中数据
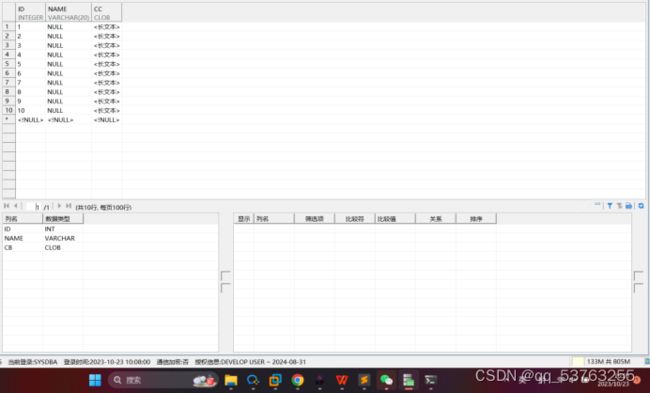
- 大字段数据导入(普通装载)
-
8.1 注意事项
1.MODE=IN 且 DIRECT=FALSE,BLOB_TYPE参数才有效,数据文件中大字段列数据,即字段内容。
2.BLOB_TYPE=HEX_CHAR (默认值),数据文件中 BLOB 列当作为十六进制内容; BLOB_TYPE=HEX,数据文件中BLOB列为字符串形式内容,导入后会转换为十六进制。
3.NULL_MODE=TRUE, 载入时NULL 字符串处理为NULL,载出时空值处理为NULL字符串. NULL_MODE=FALSE,载入时 NULL 字符串处理为字符串,载出时空值处理为空串.
8.2 存储结构创建
drop table if exists LIBRARY.t_lob21;
create table t_lob21 (id int not null, name varchar(20), join datetime, cc clob, bb blob);
drop table if exists LIBRARY.t_lob22;
create table t_lob22 (id int not null, name varchar(20), join datetime, cc clob, bb blob);
8.3 数据文件
# 数据文件:t_lob2.dat
ID NAME JOIN CC BB
1|Well Smith|202106182040|abcdefg|30
2|Scott Jim|202106182040|hijlkmn|32
3|Tony Ja|202006182040|adefhjd|33
4|Tom Jason|202106182045|123456789|34
5|Rianledo Lee|20210618204010|98765431|35
6|null|202106182041|yyyyyyyyy|36
7|NuLL|202106182058|zzzzzzzzz|36
8.4 控制文件
T_lob21.ctl
OPTIONS (
MODE='IN'
SKIP=1
DIRECT=FALSE
CHARACTER_CODE='UTF-8'
BLOB_TYPE='HEX_CHAR'
NULL_MODE=TRUE
SILENT=TRUE
LOG='C:\Users\86183\Desktop\resource\res\dmfldr\t_lob2\t_lob21.log'
)
LOAD DATA
INFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\t_lob2\t_lob2.dat'
BADFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\t_lob2\t_lob21.bad'
REPLACE INTO TABLE LIBRARY.T_LOB21
FIELDS '|'
(
id,
name "REPLACE(:REPLACE,'J','X')",
join date format 'YYYYMMDDHH24MISS',
cc,
bb
)
T_lob22.ctl
OPTIONS (
MODE='IN'
SKIP=1
DIRECT=FALSE
CHARACTER_CODE='UTF-8'
BLOB_TYPE='HEX'
NULL_MODE=FALSE
SILENT=TRUE
LOG='C:\Users\86183\Desktop\resource\res\dmfldr\t_lob2\t_lob22.log'
)
LOAD DATA
INFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\t_lob2\t_lob2.dat'
BADFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\t_lob2\t_lob22.bad'
REPLACE INTO TABLE LIBRARY.t_lob22
FIELDS '|'
(
id,
name NULL,
join date format 'YYYYMMDDHH24MISS',
cc,
bb
)
8.5 命令行输入
BLOB_TYPE=HEX_CHAR
E:\dmdbms\bin>dmfldr SYSDBA/dzy020131 CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\t_lob2\t_lob21.ctl'
dmfldr V8
7 rows processed.
目标表:LIBRARY.T_LOB21
load success.
7 行加载成功。
0 行由于数据错误没有加载。
0 行由于数据格式错误被丢弃。
跳过的逻辑记录总数:1
读取的逻辑记录总数:7
拒绝的逻辑记录总数:0
4.064(ms)已使用
BLOB_TYPE=HEX
E:\dmdbms\bin>dmfldr SYSDBA/dzy020131 CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\t_lob2\t_lob22.ctl'
dmfldr V8
7 rows processed.
目标表:LIBRARY.T_LOB22
load success.
7 行加载成功。
0 行由于数据错误没有加载。
0 行由于数据格式错误被丢弃。
跳过的逻辑记录总数:1
-
读取的逻辑记录总数:7
-
拒绝的逻辑记录总数:0
3.235(ms)已使用
-
8.6 表中数据
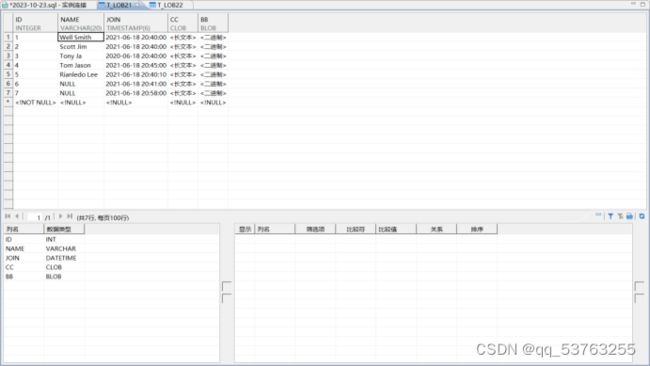
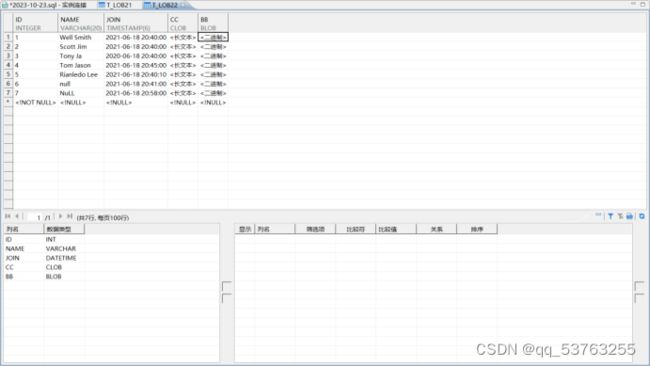
-
8.7 空值比较
select 'T_LOB21',id,ifnull(name,'NULL_VALUE') from "LIBRARY"."T_LOB21"
union all
select 'T_LOB22',id,ifnull(name,'NULL_VALUE') from "LIBRARY"."T_LOB22";

可以看到在参数NULL_MODE=TRUE时,数据文件中的NULL均被导入成NULL_VALUE,
在NULL_MODE=FALSE时,NULL以字符串的形式被导入;
九.关于某数据列(聚集索引)排序装载
9.1 注意事项
1.SORTED参数作用驱于已经按聚集索引排序的数据列,默认为 FALSE。
SORTED=TRUE,须保证数据已按聚集索引排序完成,且表中存在数据,插入时,数据文件中的索引值要比表中数据的索引值大,服务器在做插入操作时顺序进行插入。若数据并未按照索引排序,则 dmfldr 会报错,装载失败。
SORTED=FALSE,则服务器对于每条记录进行定位插入。此参数SORTED仅在MODE为IN且DIRECT为TRUE 的情况下有效,对于其他情况此参数无效。
在数据量大且确定数据已按照聚集索引排序完成的情况下,将SORTED参数设置为TRUE,可以提升装载性能。
9.2 存储结构创建
drop table if exists LIBRARY.t_sort;
create table LIBRARY.t_sort
(
c1 int ,
c2 varchar(20),
c3 int ,
cluster primary key (c1)
);
insert
into LIBRARY.t_sort(c1,c2,c3)
values (1,'aaaaxx',100),(2,'bbbb',97);
commit;
select * from LIBRARY.t_sort;
# 数据文件:sort.dat
1,aaaa,99
2,bbbb,97
3,cccc,98
4,dddd,100
5,eeee,96
6,ffff,93
7,gggg,102
8,hhhh,80
-

-
9.3 控制文件t_sort.ctl
OPTIONS (
SKIP=2 //根据注意事项中写到,装载索引数据时表中需要有数据,我们提前插入了2条数据。但是装载时如果数据文件中存在索引值小于表中值的记录,就会导致导入失败,索引要设置参数SKIP=2来跳过已经插入的有序数据。
CHARACTER_CODE='UTF-8'
MODE='IN'
DIRECT=TRUE
SORTED=TRUE
SILENT=TRUE
LOAD=3
FLUSH_FLAG=TRUE
IGNORE_BATCH_ERRORS=TRUE
)
LOAD DATA
INFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\t_sort\t_sort.dat'
BADFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\t_sort\t_sort.bad'
APPEND INTO TABLE LIBRARY.t_sort
FIELDS ','
9.4 命令行输入
E:\dmdbms\bin>dmfldr SYSDBA/dzy020131 CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\t_sort\t_sort.ctl' LOG='C:\Users\86183\Desktop\resource\res\dmfldr\t_sort\t_sort.log'
dmfldr V8
目标表:LIBRARY.T_SORT
load success.
3 行加载成功。
0 行由于数据错误没有加载。
0 行由于数据格式错误被丢弃。
跳过的逻辑记录总数:2
读取的逻辑记录总数:3
拒绝的逻辑记录总数:0
3.957(ms)已使用
9.5 表中数据

-
十.SQL查询导出
10.1 数据准备
set schema LIBRARY
create table fstest (c1 VARCHAR(20), c2 int);
insert into fstest values('数学', 90), ('语文', 99), ('英语', 100);
commit;
select * from fstest;
-

-
10.2 控制文件fstest.ctl
第一种实现
OPTIONS
(
CHARACTER_CODE='UTF-8'
MODE='OUT'
SQL='SELECT * FROM LIBRARY.FSTEST WHERE C2>=99'
)
LOAD DATA
INFILE 'C:\Users\86183\Desktop\resource\res\dmfldr\fstest\fstest.dat'
INSERT
INTO TABLE LIBRARY.FSTEST
FIELDS '|'
10.3 命令行输入
E:\dmdbms\bin>dmfldr SYSDBA/SYSDBA CONTROL='C:\Users\86183\Desktop\resource\res\dmfldr\fstest\fstest.ctl'
dmfldr V8
2 rows is load out
export success.
2 行数据已导出
用时:7.467(ms)
-
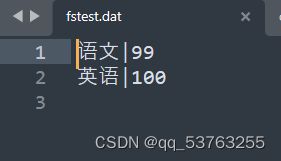
- 高效数据装载参数配置
-
高效装载无非就是指支持多线程多并发,加大数据缓存,批量发送数据,索引更新处理。
1. BUFFER_NODE_SIZE:设置读取文件缓冲区页大小。
值越大,缓冲区的页越大,每次读取的数据就越多,每次发送到服务器的数据也就越多,效率越高。但其大小受dmfldr客户端内存大小限制。
2. READ_ROWS:限制处理的行数。
在某些情况下,BUFFER_NODE_SIZE读入的数据行数很大,而后续操作处理不了这么大的行数,此时可以用 READ_ROWS限制行数。
dmfldr取 READ_ROWS和BUFFER_NODE_SIZE中较小的值作为一次处理的行数。
3. SEND_NODE_NUMBE:指定dmfldr在数据载入时发送节点的个数,默认由系统计算一个初始值。
若在数据载入时发现发送节点不够用,系统会动态增加分配。
在系统内存足够的情况下,可以适当设大SEND_NODE_NUMBER 值,提升 dmfldr 载入性能。
4. TASK_THREAD_NUMBER:指定dmfldr在数据载入时处理用户数据的线程数目。
默认情况下,dmfldr 将该参数值设为系统 CPU 的个数,但当CPU个数大于 8 时,默认值都被置为8。
在 dmfldr客户端所在机器CPU大于8 环境中,提高TASK_THREAD_NUMBER 值可以提升 dmfldr 装载性能。
5. BLDR_NUM 水平分区表装载时,指定服务器 BLDR 的最大个数,默认为 64。
服务器的 BLDR 保存水平分区子表相关信息,BLDR_NUM 的设置也就指定了服务器能同时载入的水平分区子表的个数。
若BLDR_NUM设置太大,当水平分区子表数过多时,可能会导致服务器内存不足。
当载入时实际需要的 BLDR 个数超出 BLDR_NUM 设置时,会淘汰指定子表的BLDR,并替换为新的子表BLDR。
6. BDTA_SIZE: BDTA(Batch Data)的大小,默认为 5000。
BDTA代表 DM 数据库批量数据处理机制中一个批量,在内存、CPU 允许的条件下,增大 BDTA_SIZE 能加快装载速度;
在网络是装载性能瓶颈时,增大 BDTA_SIZE 影响不大。
7. INDEX_OPTION 索引的设置选项,默认为 1。
1 --> 代表服务器装载数据时先不刷新二级索引,而是将新数据按照索引预先排序,在装载完成后,再将排好序的数据插入索引。
如果在数据载入前,目标表中已有较多数据,建议INDEX_OPTION 置为 1。
2 --> 代表服务器在快速装载过程中不刷新二级索引数据,只在装载完成时重建所有二级索引。
如果在数据载入前,目标表中没有数据或数据量较小,建议 INDEX_OPTION 置为 2。
3 --> 代表服务器使用追加模式来进行二级索引的插入,在数据装载的过程中, 同时进行二级索引的插入,
当原有数据量远大于插入数据量时, 建议 INDEX_OPTION 置为 3。
8. PARALLEL 载入数据时,是否开启并行模式。
开启并行参数后,可以运行多个用户同时向同一张表装载数据,此模式可以充分利用客户端的数据处理能力,
服务器接收到各个客户端发送过来的数据后,再进行统一的数据处理和刷盘。
-
社区地址:https://eco.dameng.com