并发编程中常见的设计模式
文章目录
-
- 一、 终止线程的设计模式
-
- 1. 简介
- 2. Tow-phase Termination(两阶段终止模式)—优雅的停止线程
- 二、避免共享的设计模式
-
- 1. 简介
- 2. Immutability模式—想破坏也破坏不了
- 3. Copy-on-Write模式
- 4. Thread-Specific Storage模式—没有共享就没有伤害
- 三、多线程版本的if模式
-
- 1. 简介
- 2. Guarded Suspension模式—等我准备好
- 3. Balking模式—不需要就算了
- 四、多线程分工模式
-
- 1. 简介
- 2. Thread-Per-Message模式—最简单实用的分工方法
- 3. Working Thread模式—如何避免重复创建线程
- 4. 生产者 - 消费者模式—用流水线的思想提高效率
一、 终止线程的设计模式
1. 简介
思考:在一个线程T1中如何正确安全的终止线程T2
- 错误思路1
使用线程对象的stop()方法停止线程,因为Stop方法会真正杀死线程,如果这时线程锁住了共享资源,那么当它被杀死后就再也没有机会释放锁,其它线程将永远无法获取锁。
- 错误思路2
使用System.exit(int)方法停止线程,目的仅是停止一个线程,但这种做法会让整个程序都停止。
2. Tow-phase Termination(两阶段终止模式)—优雅的停止线程
“两阶段停止”(Two-Phase Termination)是一种多线程编程中的设计模式,用于优雅地终止一个线程。这个模式包含两个阶段:
第一阶段 - 发出终止请求: 在这个阶段,通过设置一个标志(通常是一个volatile变量)来通知线程应该停止。线程在执行任务时会周期性地检查这个标志,如果发现终止请求,则会进入第二阶段。
第二阶段 - 执行清理工作: 在这个阶段,线程执行必要的清理工作,释放资源、关闭连接等。这个阶段的目的是确保线程在终止前完成所有必要的清理,以确保系统的稳定性。
这个模式的优点在于它提供了一种可控的、安全的线程终止机制,避免了突然中断线程可能导致的资源泄漏或数据不一致性问题。通过明确地区分终止请求和清理工作两个阶段,可以更好地管理线程的生命周期。
如下面代码就实现了两阶段终止模式:
private static class MyThread extends Thread {
private volatile boolean terminated = false;
@Override
public void run() {
try {
//判断线程是否被中断
while (!terminated) {
// 线程执行的业务逻辑
System.out.println("Working...");
Thread.sleep(1000);
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
cleanup();
}
}
//该线程的中断方法
public void terminate() {
terminated = true;
interrupt(); // 中断线程,唤醒可能在等待状态的线程
}
//中断后的清理工作
private void cleanup() {
// 执行清理工作,例如关闭资源等
System.out.println("Cleanup work...");
}
}
public static void main(String[] args) {
//创建一个新的线程
MyThread myThread = new MyThread();
myThread.start();
// 模拟运行一段时间后终止线程
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 发出终止请求
myThread.terminate();
// 等待线程结束
try {
myThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Main thread exiting...");
}
上面我们我们使用系统提供的中断标志位,而是自己实现的
二、避免共享的设计模式
1. 简介
Immutability模式,Copy-on-Write模式,Thread-Specific Storage模式本质上是为了避免共享。
- 使用时需要注意Immutablility模式的属性不可变性
- Copy-on-Write模式需要注意拷贝的性能问题
- Thread-Specific Storage模式需要注意异步执行问题
2. Immutability模式—想破坏也破坏不了
“多个线程同时读写同一共享变量存在的共享问题”,这里的必要条件之一就是读写,如果只有读,而没有写,是没有并法问题的。解决并法问题,其实最简单的办法就是让共享变量只有读操作,而没有写操作。这个办法如此重要,以致于被上升到了一种解决并法问题的设计模式:不变性(Immutability)模式。所谓不变性,简单来讲,就是对象一旦创建之后,状态就不再发生变化。换句话说,就是变量一旦被赋值。就不允许修改了(没有写操作);没有修改操作,也就是保持了不变性。以下是不变性模式的特点:
线程安全性: 不可变对象天生是线程安全的,因为多个线程无法修改它们的状态。这简化了并发编程,无需使用锁或其他同步机制。
简化代码: 不可变性避免了对象状态的变化,减少了代码的复杂性。由于对象不可变,不需要考虑状态的一致性和变化。
易于缓存: 不可变对象是可缓存的,因为它们的值永远不会改变。可以在对象创建时进行缓存,而无需担心后续的修改。
安全性: 不可变对象不容易受到外部修改的影响,因此更容易设计和维护安全的系统。
- 如何实现:
将一个类所有的属性都设置为final,并且只允许存在只读方法,那么这个类基本上就具备了不可变性了。更严格的做法是这个类本身也是final的,也就是不允许继承。jdk中很多类都具备本可变性,例如经常用到的String和Long、Integer、Double等基础类型的包装类都具备不可变性,这些对象的线程安全性是靠不可变性来保证的,它们都严格遵守来不可变类的三点要求:类和属性都是final的,所有方法都是只读的
- 使用Immutability模式的注意事项
- 所有对象的属性都是final的,并不能保证不可变性:如final修饰的是对象的引用,此时对象的引用目标是不变的,但被引用的对象本身是可以改变的。
- 不可变对象也需要正确的发布
在使用Immutability模式的时候一定要确定保持不变性的边界在哪里,是否要求属性也具备不变性。
public final class ImmutablePerson {
//属性全部定义为final属性
private final String name;
private final int age;
public ImmutablePerson(String name, int age) {
this.name = name;
this.age = age;
}
//只提供了get方法
public String getName() {
return name;
}
public int getAge() {
return age;
}
//当需要修改属性时,会创建一个新的对象,这就是后面要介绍的Copy-on-Write模式
public ImmutablePerson withAge(int newAge) {
return new ImmutablePerson(this.name, newAge);
}
// 不提供setter方法,确保对象的不可变性
@Override
public String toString() {
return "ImmutablePerson{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public static void main(String[] args) {
ImmutablePerson person = new ImmutablePerson("John", 30);
System.out.println(person);
// 通过withAge方法创建新对象,而不是修改现有对象
ImmutablePerson newPerson = person.withAge(31);
System.out.println(newPerson);
// 原始对象仍然保持不可变性
System.out.println(person);
}
}
3. Copy-on-Write模式
- 简介
Java里String在实现replace()方法的时候,并没有更改value[]数组的内容,而是创建了一个新的字符串,这种方法在解决不可变对象的修改问题时经常用到。它本质上就是Copy-on-Write方法,顾命思议,写时复制。
不可变对象的写操作往往都是使用Copy-on-Write 方法解决的,当然Copy-on-Write的应用领域并不局限于 Immutability模式。Copy-on-Write才是最简单的并发解决方案,很多人都在无意中把它忽视了。它是如此简单,以至于 Java 中的基本数据类型 String、Integer、Long 等都是基于Copy-on-Write方案实现的。Copy-on-Write缺点就是消耗内存,每次修改都需要复制一个新的对象出来,好在随着自动垃圾回收(GC)算法的成熟以及硬件的发展,这种内存消耗已经渐渐可以接受了。所以在实际工作中,如果写操作非常少(读多写少的场景),可以尝试使用 Copy-on-Write。
- 应用场景
在Java中,CopyOnWriteArrayList 和 CopyOnWriteArraySet这两个Copy-on-Write
容器,它们背后的设计思想就是Copy-on-Write;通过 Copy-on-Write这两个容器实现的读操作是无锁的,由于无锁,所以将读操作的性能发挥到了极致。Copy-on-Write 在操作系统领域也有广泛的应用。类 Unix 的操作系统中创建进程的 API 是 fork(),传统的 fork() 函数会创建父进程的一个完整副本,例如父进程的地址空间现在用到 了1G 的内存,那么 fork() 子进程的时候要复制父进程整个进程的地址空间(占有 1G 内存) 给子进程,这个过程是很耗时的。而 Linux 中fork() 子进程的时候,并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间;只用在父进程或者子进程需要写入的时候才会复制地址空间,从而使父子进程拥有各自的地址空间。Copy-on-Write 最大的应用领域还是在函数式编程领域。函数式编程的基础是不可变性 (Immutability),所以函数式编程里面所有的修改操作都需要 Copy-on-Write 来解决。像一些RPC框架还有服务注册中心,也会利用Copy-on-Write设计思想维护服务路由表。 路由表是典型的读多写少,而且路由表对数据的一致性要求并不高,一个服务提供方从上线到 反馈到客户端的路由表里,即便有 5 秒钟延迟,很多时候也都是能接受的。
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class CopyOnWriteExample {
private List<String> data = new ArrayList<>();
public void addData(String value) {
// 创建数据副本
List<String> newData = new ArrayList<>(data);
newData.add(value);
// 将新副本赋值给原始数据
data = newData;
}
public void printData() {
// 读取数据,无需加锁
for (String value : data) {
System.out.println(value);
}
}
public static void main(String[] args) {
CopyOnWriteExample example = new CopyOnWriteExample();
// 启动一个线程添加数据
Thread writerThread = new Thread(() -> {
for (int i = 0; i < 5; i++) {
example.addData("Data " + i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// 启动一个线程读取数据
Thread readerThread = new Thread(() -> {
for (int i = 0; i < 3; i++) {
example.printData();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
writerThread.start();
readerThread.start();
}
}
4. Thread-Specific Storage模式—没有共享就没有伤害
Thread-Specific Storage(线程特定存储),简称TSS,是一种设计模式,用于在多线程环境中实现线程私有的数据存储。该模式允许每个线程都有自己的数据副本,而不会影响其他线程的数据。这对于需要在线程之间隔离数据的场景非常有用。在Java中,ThreadLocal类是实现Thread-Specific Storage模式的一种方式。ThreadLocal提供了一种在每个线程中存储数据的机制,确保每个线程都能访问到自己的数据副本。
如果你需要在并发场景中使用一个线程不安全的工具类,最简单的方案就是避免共享。 避免共享有两种方案,一种方案是将这个工具类作为局部变量使用,另外一种方案就是线程本地存储模式。这两种方案,局部变量方案的缺点是在高并发场景下会频繁创建对象,而线程本地存储方案,每个线程只需要创建一个工具类的实例,所以不存在频繁创建对象的问题。
public class ThreadSpecificStorageExample {
private static ThreadLocal<Integer> threadLocalData = new ThreadLocal<>();
public static void main(String[] args) {
// 启动两个线程,分别操作ThreadLocal中的数据
Thread thread1 = new Thread(() -> {
threadLocalData.set(1);
System.out.println("Thread 1: Data = " + threadLocalData.get());
});
Thread thread2 = new Thread(() -> {
threadLocalData.set(2);
System.out.println("Thread 2: Data = " + threadLocalData.get());
});
// 启动线程
thread1.start();
thread2.start();
// 主线程操作ThreadLocal中的数据
threadLocalData.set(0);
System.out.println("Main Thread: Data = " + threadLocalData.get());
}
}
三、多线程版本的if模式
1. 简介
Guarded Suspension模式和Balking模式属于多线程版本的if模式
- Guarded Suspension模式需要注意性能
- Balking模式需要注意竞态条件
2. Guarded Suspension模式—等我准备好
Guarded Suspension(保护性暂停) 模式是一种多线程设计模式,用于解决在特定条件下才能执行的操作。这个模式的核心思想是,当条件不满足时,线程暂时挂起等待,直到条件满足时再继续执行。这种模式通常用于协调多个线程之间的操作,其中一个线程(称为 “等待方”)等待另一个线程(称为 “通知方”)满足某个条件。Guarded Suspension 模式有助于防止在条件不满足时执行不必要的操作,提高系统效率。
以下是 Guarded Suspension 模式的一般步骤:
- 等待条件: “等待方” 在某个条件不满足时挂起等待,例如使用 wait 方法。
- 通知: “通知方” 在满足条件时通知等待方,例如使用 notify 或 notifyAll 方法。
- 唤醒: “等待方” 在收到通知后被唤醒,检查条件是否满足,如果满足则执行相应操作,否则继续等待。
场景的使用这种设计模式的场景有如下三种:
- synchronized+wait/notify/notifyAll
- reentrantLock+Condition(await/singal/dingalAll)
- cas+park/unpark
这种设计模式常用于多线程环境下多个线程访问相同实例资源,从实例资源中获得资源并处理。实例资源需要管理自身拥有的资源,并对请求线程的请求作出允许与否的判断。
public class GuardedSuspensionExample {
private boolean condition = false;
public synchronized void waitForCondition() {
while (!condition) {
try {
// 等待条件满足
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 条件满足后执行操作
System.out.println("Condition is satisfied!");
}
public synchronized void notifyCondition() {
// 修改条件为满足
condition = true;
// 通知等待的线程
notifyAll();
}
public static void main(String[] args) {
GuardedSuspensionExample example = new GuardedSuspensionExample();
// 启动一个线程等待条件满足
Thread waitingThread = new Thread(() -> example.waitForCondition());
// 启动另一个线程通知条件满足
Thread notifyingThread = new Thread(() -> {
try {
// 模拟一些操作
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
example.notifyCondition();
});
waitingThread.start();
notifyingThread.start();
}
}
3. Balking模式—不需要就算了
Balking是“退缩不前”的意思。如果现在不适合执行这个操作,或者没必要执行这个操作,就停止处理,直接返回。当流程的执行顺序依赖于某个共享变量的场景,可以归纳为多线程if模式。Balking 模式常用于一个线程发现另一个线程已经做了某一件相同的事,那么本线程就无需再做了,直接结束返回。Balking模式是一种多个线程执行同一操作A时可以考虑的模式;在某一个线程B被阻塞或者执行其他操作时,其他线程同样可以完成操作A,而当线程B恢复执行或者要执行操作A时,因A 已被执行,而无需线程B再执行,从而提高了B的执行效率。Balking模式和Guarded Suspension模式一样,存在守护条件,如果守护条件不满足,则中断处理;这与Guarded Suspension模式不同,Guarded Suspension模式在守护条件不满足的时候会一直等待至可以运行。
这个模式的核心思想是在某个条件未满足时立即返回,而不是等待条件满足后再执行操作。
以下是 Balking 模式的一般步骤:
检查条件: 在执行操作之前,首先检查某个条件是否满足。
条件满足: 如果条件满足,执行操作。
条件不满足: 如果条件不满足,立即返回,避免执行不必要的操作。
- 常用场景
- sychronized轻量级锁膨胀逻辑, 只需要一个线程膨胀获取monitor对象
- DCL单例实现
- 服务组件的初始化
public class BalkingExample {
private boolean condition = false;
public synchronized void performOperation() {
// 检查条件
if (condition) {
// 条件满足,执行操作
System.out.println("Operation performed!");
// 执行完操作后,将条件重置为不满足
condition = false;
} else {
// 条件不满足,返回
System.out.println("Condition not met. Operation skipped.");
}
}
public synchronized void setCondition() {
// 修改条件为满足
condition = true;
// 唤醒可能在等待的线程
notifyAll();
}
public static void main(String[] args) {
BalkingExample example = new BalkingExample();
// 启动一个线程执行操作
Thread operationThread = new Thread(() -> example.performOperation());
// 启动另一个线程设置条件为满足
Thread setConditionThread = new Thread(() -> {
try {
// 模拟一些操作
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
example.setCondition();
});
operationThread.start();
setConditionThread.start();
}
}
四、多线程分工模式
1. 简介
Thread-Per-Message模式、Worker Thread模式和生产者-消费者模式属于多线程分工模式。
- Thread-Per-Message模式需要注意线程的创建、销毁以及是否会导致OOM
- Worker Thread模式需要注意死锁问题,提交的任务之间不要有依赖
- 生产者-消费者模式可以直接使用线程池来实现
2. Thread-Per-Message模式—最简单实用的分工方法
Thread-Per-Message 模式是一种多线程设计模式,它通过为每个消息或任务创建一个新的线程来处理。每个消息都由一个独立的线程处理,从而实现并发处理的效果。这种模式通常用于处理异步任务,每个任务都在自己的线程中执行,从而不阻塞主线程或其他任务的执行。
以下是 Thread-Per-Message 模式的一般步骤:
消息创建: 每当需要处理一个任务或消息时,创建一个新的线程。
任务处理: 将任务或消息分配给新创建的线程,由该线程负责处理。
线程生命周期: 线程在完成任务后结束,释放资源。
- 应用场景
Thread-Per-Message模式的一个最经典的应用场景是网路编程里服务端的实现,服务端为每个客户端请求创建一个独立的线程,当线程处理完毕后,自动销毁,这是一种简单的并发处理网络请求的方法。
public class ThreadPerMessageExample {
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
// 模拟创建并处理消息
Message message = new Message("Message " + i);
processMessage(message);
}
}
private static void processMessage(Message message) {
// 创建新线程处理消息
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " processing " + message.getContent());
}).start();
}
static class Message {
private String content;
public Message(String content) {
this.content = content;
}
public String getContent() {
return content;
}
}
}
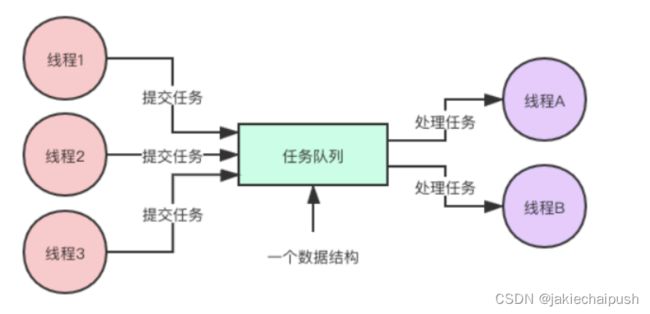
3. Working Thread模式—如何避免重复创建线程
“Worker Thread” 模式是一种并发设计模式,用于处理异步任务。在这个模式中,创建一个固定数量的工作线程(Worker Thread),这些线程负责处理异步任务队列中的任务。通过使用 Worker Thread 模式,可以实现异步处理,提高系统的响应性,并允许主线程(或其他线程)继续执行其他任务。
Worker Thread 模式能避免线程频繁创建、销毁的问题,而且能够限制线程的最大数量。Java 语言里可以直接使用线程池来实现 Worker Thread 模式,线程池是一个非常基础和优秀的工具类,甚至有些大厂的编码规范都不允许用 new Thread() 来创建线程,必须使用线程池。
Java和GO等其它语言不同,它不会创建轻量级现场,它创建的每一个线程都对应于一个操作系统内核级线程,如果评价创建会导致系统性能过低
public class WorkerThreadExample {
public static void main(String[] args) {
// 创建固定数量的工作线程池
ExecutorService executorService = Executors.newFixedThreadPool(3);
// 提交异步任务
for (int i = 0; i < 5; i++) {
executorService.submit(() -> {
System.out.println(Thread.currentThread().getName() + " processing task");
// 模拟任务执行时间
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
// 关闭线程池
executorService.shutdown();
}
}
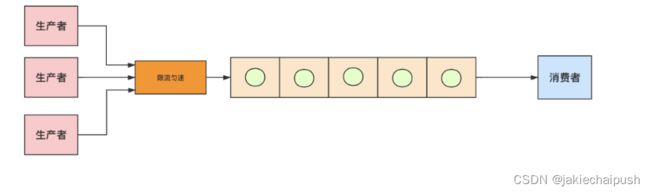
4. 生产者 - 消费者模式—用流水线的思想提高效率
生产者 - 消费者模式的核心是一个任务队列,生产者线程生产任务,并将任务添加到任务队列中,而消费者线程从任务队列中获取任务并执行。生产者-消费者模式是一种经典的多线程设计模式,用于解决生产者和消费者之间的协作问题。在这个模式中,有一个共享的缓冲区(或队列),生产者将产品放入缓冲区,而消费者从缓冲区取出产品。这有助于实现生产者和消费者的解耦和协同工作。
import java.util.LinkedList;
import java.util.Queue;
public class ProducerConsumerExample {
private static final int CAPACITY = 5;
private static Queue<Integer> buffer = new LinkedList<>();
public static void main(String[] args) {
Thread producerThread = new Thread(() -> {
for (int i = 0; i < 10; i++) {
produce(i);
}
});
Thread consumerThread = new Thread(() -> {
for (int i = 0; i < 10; i++) {
consume();
}
});
producerThread.start();
consumerThread.start();
}
private static void produce(int item) {
synchronized (buffer) {
// 检查缓冲区是否已满
while (buffer.size() == CAPACITY) {
try {
// 如果满了,等待消费者取出产品
buffer.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 生产产品并放入缓冲区
buffer.offer(item);
System.out.println("Produced: " + item);
// 通知消费者可以取出产品
buffer.notifyAll();
}
}
private static void consume() {
synchronized (buffer) {
// 检查缓冲区是否为空
while (buffer.isEmpty()) {
try {
// 如果为空,等待生产者生产产品
buffer.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 从缓冲区取出产品并消费
int item = buffer.poll();
System.out.println("Consumed: " + item);
// 通知生产者可以继续生产产品
buffer.notifyAll();
}
}
}
- 生产者-消费者队列的优点
支持异步处理
场景:用户注册后,需要发注册邮件和注册短信。传统的做法有两种 1.串行的方式;2.并行方式
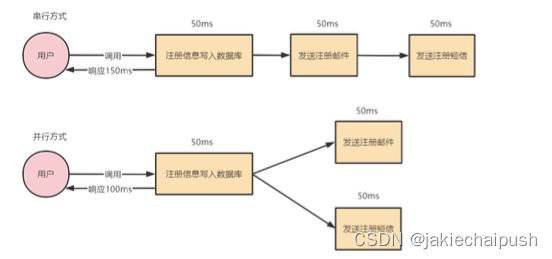
引入消息队列,将不是必须的业务逻辑异步处理
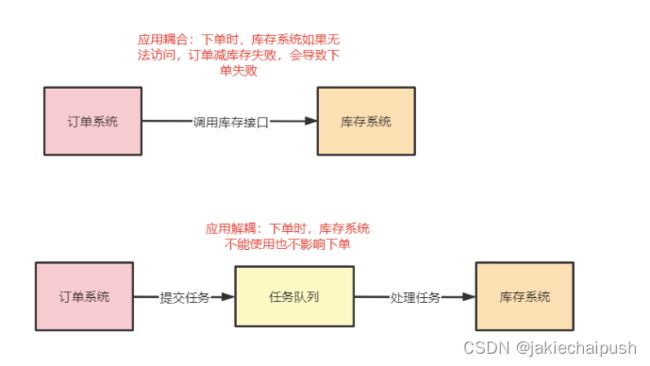
解耦
场景:用户下单后,订单系统需要通知库存系统扣减库存。
削峰,消除生产者生产与消费者消费之间速度差异
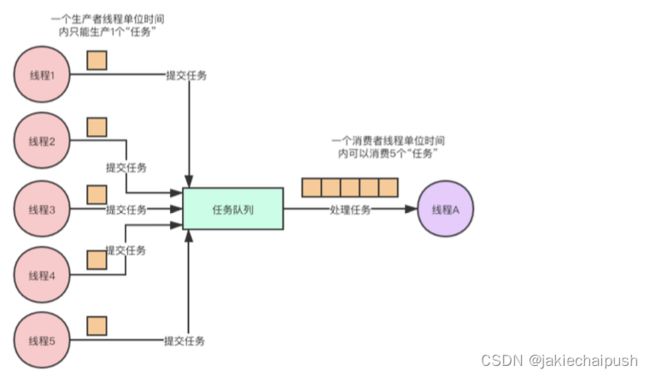
在计算机当中,创建的线程越多,CPU进行上下文切换的成本就越大,所以我们在编程的时候创建的线程并不是越多越好,而是适量即可,采用生产者和消费者模式就可以很好的支持我们使用适量的线程来完成任务。如果在某一段业务高峰期的时间里生产者“生产”任务的速率很快,而消费者“消费”任务速率很慢,由于中间的任务队列的存在,也可以起到缓冲的作用,我们在使用MQ中间件的时候,经常说的削峰填谷也就是这个意思。
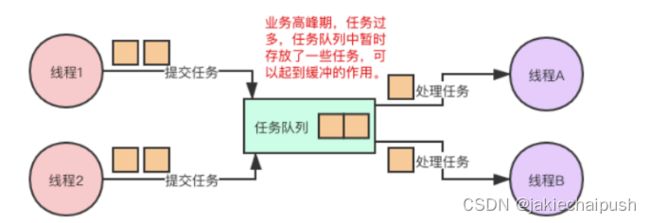
- 过饱问题解决方案
在实际项目开发中会有些极端的情况,导致生产者/消费者模式可能出现过饱的问题。单位时间内,生产者的速度大于消费者的速度,导致任务不断堆积在阻塞队列中,队列堆满只是时间问题。
是不是只要保证消费者的消费速度一直对生产者的生产速度快就可以解决过饱问题?
其实我们只要在业务可以容忍的最长响应时间内,把堆积的任务处理完,那就不算过饱。
什么是业务容忍的最长响应时间? 比如埋点数据统计前一天的数据生成报表,第二天老板要看的,你前一天的数据第二天还没处理完,那就不行,这样的系统我们就要保证,消费者在24小时内的消费能力要比生产者高才行。
场景一:消费者每天能处理的量比生产者生产的少;如生产者每天1万条,消费者每天只能消费 5千条。
解决办法:消费者加机器
原因:生产者没法限流,因为要一天内处理完,只能消费者加机器
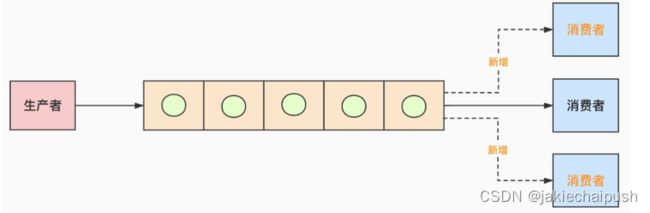
场景二:消费者每天能处理的量比生产者生产的多。系统高峰期生产者速度太快,把队列塞爆了
解决办法:适当加大队列
原因:消费者一天的消费能力已经高于生产者,那说明一天之内肯定能处理完,保证高峰期别把队列塞满就好
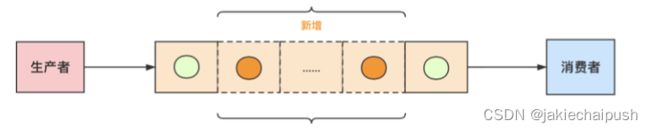
场景三:消费者每天能处理的量比生产者生产的多。条件有限或其他原因,队列没法设置特别大。系统高峰期生产者速度太快,把队列塞爆了
解决办法:生产者限流
原因:消费者一天的消费能力高于生产者,说明一天内能处理完,队列又太小,那只能限流生产者,让高峰期塞队列的速度慢点